Este blog foi publicado como parte de Data Science Blogathon 7
importar pandas como pd
Cada projeto de análise de dados requer um conjunto de dados. Esses conjuntos de dados estão disponíveis em vários formatos de arquivo, como .xlsx, .json, .csv, .html. Convencionalmente, conjuntos de dados são encontrados principalmente em .csv formato. CSV (o Valores Separados Por Virgula), como o nome sugere, têm elementos de dados separados por vírgulas. Os arquivos CSV são arquivos de texto simples que têm um tamanho de arquivo mais leve. O que mais, Os arquivos CSV podem ser visualizados e salvos em forma de tabela em ferramentas populares como Microsoft Excel e Planilhas Google.
As vírgulas usadas em arquivos CSV são conhecidas como delimitadores. Pense nos delimitadores como um limite de separação que distingue entre dois itens de dados subsequentes.

Ler arquivos CSV usando Pandas
Para ler esses arquivos CSV, usamos uma função da biblioteca Pandas chamada read_csv ().
df = pd.read_csv()
A função read_csv () ele tem dezenas de parâmetros, dos quais um é obrigatório e os outros são opcionais para uso ad hoc. Este parâmetro obrigatório especifica o arquivo CSV que queremos ler. Por exemplo,
df = pd.read_csv("C:UsersRahulDesktopabc.csv")
Observação: Lembre-se de usar barras invertidas duplas ao especificar o caminho do arquivo.

(Fonte: computador pessoal)
O parâmetro sep
Um dos parâmetros opcionais em read_csv () isto é set, um nome curto para separador. Este operador é o delimitador de que falamos antes. Este parâmetro sep diz ao intérprete, qual delimitador é usado em nosso conjunto de dados ou no termo de Layman, como os elementos de dados são separados em nosso arquivo CSV.
O valor padrão do parâmetro sep é o coma (,) o que significa que se não especificarmos o parâmetro sep em nossa função read_csv (), nosso arquivo é entendido como usando uma vírgula como delimitador. Portanto, em nosso trecho de código acima, não especificamos o parâmetro sep, nosso arquivo foi entendido como tendo vírgulas como delimitadores.
Use outros delimitadores
Muitas vezes pode acontecer, o conjunto de dados no formato de arquivo .csv possui elementos de dados separados por um delimitador que não é uma vírgula. Inclui ponto e vírgula, dois pontos, espaço de tabulação, barras verticais, etc. Em tais casos, precisamos usar o parâmetro sep dentro da função read.csv (). Por exemplo, um arquivo chamado Exemplo.csv é um arquivo CSV separado por ponto e vírgula.
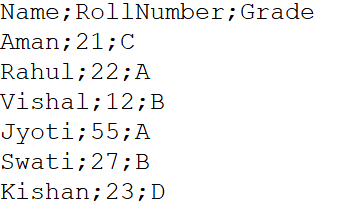
(Fonte: computador pessoal)
df = pd.read_csv("C:UsersRahulDesktopExample.csv", sep = ';')
Ao executar este código, obtemos um quadro de dados chamado df:
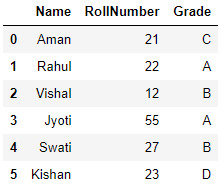
(Fonte: computador pessoal)
Separador de barra vertical
Portanto, um arquivo delimitado por barras verticais pode ser lido por:
df = pd.read_csv("C:UsersRahulDesktopExample.csv", sep = '|')
Separador de cólon
E um arquivo delimitado por dois pontos pode ser lido por:
df = pd.read_csv("C:UsersRahulDesktopExample.csv", sep = ':')
Separador de tabulações
Muitas vezes podemos encontrar conjuntos de dados em formato de arquivo .tsv. Esses arquivos .tsv têm valores separados por tabulação ou podemos dizer que tem um espaço de tabulação como delimitador. Esses arquivos podem ser lidos usando a mesma função .read_csv () de pandas e precisamos especificar o delimitador. Por exemplo:
df = pd.read_csv("C:UsersRahulDesktopExample.tsv", sep = 't')
de forma similar, outros separadores podem ser usados com base no delimitador identificado de nossos dados.
conclusão
É sempre útil verificar como nossos dados são armazenados em nosso conjunto de dados. Você precisa entender os dados antes de começar a trabalhar com eles. Um delimitador pode ser identificado facilmente, verificando os dados. De acordo com nossa inspeção, podemos usar o delimitador relevante no parâmetro sep.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





