Introdução
Teoria da estimativa e Testando hipóteses são os conceitos muito importantes de Estatística amplamente utilizados por Estatisticas, Engenheiros de aprendizado de máquina, e Cientistas de dados.
Então, neste post, vamos discutir estimadores de ponto na teoria de estimativa de estatísticas.
Tabela de conteúdo
1. Estimadores e estimadores
2. O que são estimadores pontuais?
3. Qual é a amostra aleatória e estatística?
4. Duas estatísticas comuns usadas:
- Amostra média
- Variância da amostra
5. Propriedades dos estimadores pontuais
- Imparcialidade
- Eficiente
- Consistente
- O suficiente
6. Métodos comuns para encontrar estimativas pontuais
7. Estimativa pontual vs. estimativa de intervalo
Estimativa e estimadores
Seja X uma variável aleatória com distribuição FX(x; θ), onde θ é um parâmetro desconhecido. Uma amostra aleatória, X1, X2, –, XNorte, de tamanho n tirado em X.
O problema de estimativa de pontos é selecionar uma estatística, g (X1, X2, —, XNorte), que melhor estima o parâmetro θ.
Uma vez observado, o valor numérico de g (x1, X2, —, XNorte) é chamado de estimativa e estatística g (X1, X2, —, XNorte) é chamado de estimador.
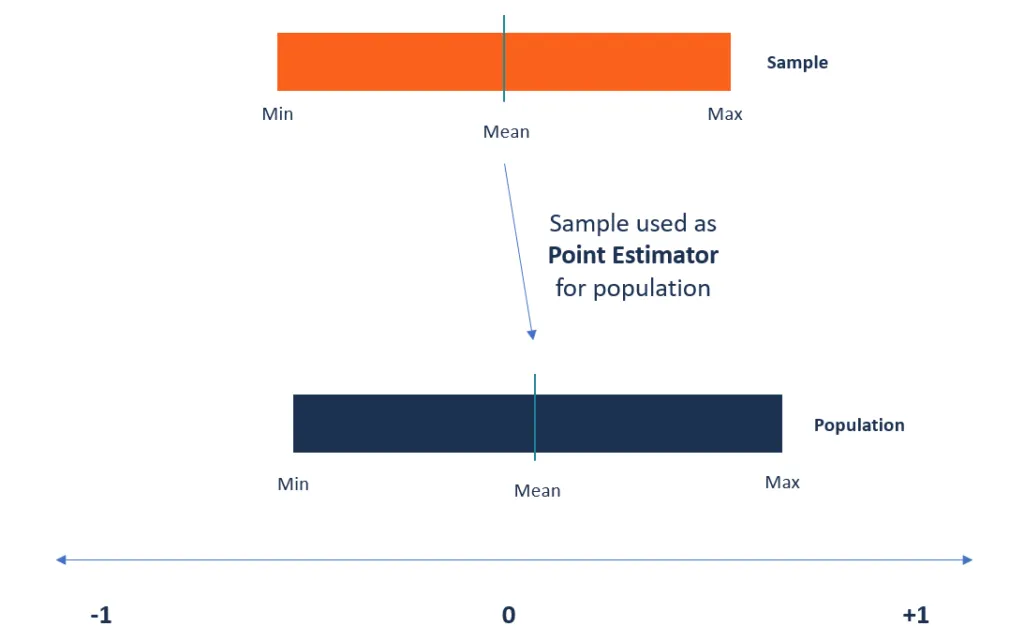
O que são estimadores pontuais?
Os estimadores pontuais são definidos como as funções usadas para encontrar um valor aproximado de um parâmetro da população a partir de amostras aleatórias da população.. Eles usam a ajuda de dados de amostra de uma população para estabelecer uma estimativa pontual ou estatística que sirva como a melhor estimativa de um parâmetro desconhecido de uma população.
Fonte da imagem: Imagens do google
Muitas vezes, os métodos existentes para encontrar os parâmetros de grandes populações são irrealistas.
Como um exemplo, quando queremos encontrar a altura média das pessoas que participam de uma conferência, será impossível coletar a altura exata de todas as cidades de conferência do mundo. Em vez de, um estatístico pode usar o estimador de ponto para estimar o parâmetro da população.
Amostra aleatória e estatísticas
Amostra aleatória: Um conjunto de IID (distribuído de forma independente e idêntica) variáveis aleatórias, X1, X2, X3, —, XNorte estabelecido no mesmo espaço amostral é chamado de amostra aleatória de tamanho n.
Estatisticas: Uma função de uma amostra aleatória é chamada de estatística (se não for dependente de qualquer entidade desconhecida)
Como um exemplo, X1+ X2+ —— + XNorte, X12X2+ eX3, X1– XNorte
Média da amostra e variância da amostra
Duas estatísticas importantes:
Deixe x1, X2, X3, —, XNorte seja uma amostra aleatória, então:
A média da amostra é denotada por X, e a variação da amostra é denotada por s2
Aqui x̄ ys2 eles são chamados de parâmetros de amostra.
Os parâmetros populacionais são indicados por meio de:
σ2 = variação da população e µ = média da população

FIG. População e média da amostra
Fonte da imagem: Imagens do google

FIG. População de amostra e variância
Fonte da imagem: Imagens do google
Características da média da amostra:
E (x̄) = 1 / n (Σ E (Xeu)) = 1 / n (nµ) = µ
Onde (x̄) = 1 / n2(Σ Var (Xeu)) = 1 / n2 (nσ2) = σ2/Norte
Características da variância da amostra:
s2 = 1 / (n-1) (Σ (xeu– X )2 ) = 1 / (n-1) (Σ xeu2 – 2x̄ Σ xeu + nx̄2 ) = 1 / (n-1) (Σ xeu2 – nx̄2 )
Agora, Vamos considerar a expectativa de ambos os lados, nós obtemos:
E (s2) = 1 / (n-1) (Σ E (xeu2) – nenhum (x̄2)) = 1 / (n-1) (Σ (µ2+ σ2) – n (µ2+ σ2/ n)) = 1 / (n-1) ((n-1) σ2) = σ2.
Propriedades dos estimadores pontuais
Em qualquer problema de estimativa, podemos ter uma classe infinita de estimadores apropriados para selecionar. O problema é encontrar um estimador g (X1, X2, —, XNorte), para um parâmetro desconhecido θ ou sua função Ψ (θ), que tem propriedades “legais”.
Essencialmente, gostaríamos que o estimador g fosse "próximo" de Ψ.
A seguir estão as principais propriedades dos estimadores pontuais:
1. imparcialidade:
Vamos primeiro entender o significado do termo “Tendência”
A diferença entre o valor esperado do estimador e o valor do parâmetro estimado é chamada de viés de um estimador pontual..
Por isso, o estimador é considerado imparcial quando o valor estimado do parâmetro e o valor do parâmetro sendo estimado são iguais.
Ao mesmo tempo, quanto mais próximo o valor esperado de um parâmetro estiver do valor do parâmetro sendo medido, quanto menor o valor de polarização.
Matematicamente,
Um estimador g (X1, X2, —, XNorte) é considerado um estimador imparcial de θ se
E (g (X1, X2, —, XNorte)) = θ
Em outras palavras, em média, esperamos que g esteja próximo do parâmetro verdadeiro θ. Vimos que se X1, X2, —, XNorte ser uma amostra aleatória de uma população com média µ e variância σ2, depois de
E (x̄) = µ y E (s2) = σ2
Por isso, x̄ e s2 são estimadores imparciais para µ e σ2
2. Eficiente:
O estimador de ponto mais eficiente é aquele com a menor variância de todos os estimadores não enviesados e consistentes.. A variância representa o nível de dispersão da estimativa, e a menor variância deve variar menos de amostra para amostra.
Geralmente, a eficiência do estimador depende da distribuição da população.
Matematicamente,
Um estimador grama1(X1, X2, —, XNorte) é mais eficiente do que grama2(X1, X2, —, XNorte), para θ sim
Onde (g1(X1, X2, —, XNorte)) <= Var (g2(X1, X2, —, XNorte))
3. Consistente:
A consistência descreve quão próximo o estimador de ponto permanece do valor do parâmetro à medida que aumenta de tamanho.. Para torná-lo mais consistente e preciso, o estimador de ponto precisa de um grande tamanho de amostra.
Podemos também verificar se um estimador de ponto é consistente, observando seu respectivo valor esperado e variância.
Para o estimador de ponto ser consistente, o valor esperado deve mover-se em direção ao valor real do parâmetro.
Matematicamente,
Deixe g1, g2, g3, ——- seja uma sequência de estimadores, a sequência é considerada consistente se convergir para θ em probabilidade, Em outras palavras,
P (| gmetro(X1, X2, —, XNorte) – θ | > ε) -> 0 quando m-> ∞
Se X1, X2, —, XNorte é uma sequência de variáveis aleatórias IID tal que E (Xeu) = µ, mais tarde por WLLN (Lei fraca de grandes números):
XNorte‘—–> µ de probabilidade
Onde XNorte'É a média de X1, X2, X3, —, XNorte
4. O suficiente:
Seja uma amostra de X ~ f (x; θ). E Y = g (X1, X2, —, XNorte) é uma estatística tal que para qualquer outra estatística Z = h (X1, X2, —, XNorte), a distribuição condicional de Z, uma vez que Y = y não depende de θ, então Y é chamado de estatística suficiente para θ.
Métodos comuns para encontrar estimativas pontuais
O procedimento de estimativa pontual envolve a utilização do valor de uma estatística obtida com o auxílio de dados amostrais para estabelecer a melhor estimativa do respectivo parâmetro desconhecido da população.. Vários métodos podem ser usados para calcular ou determinar os estimadores pontuais, e cada técnica tem propriedades diferentes. Alguns dos métodos são os seguintes:
1. Método dos momentos (MÃE)
Ele começa considerando todos os fatos conhecidos sobre uma população e, em seguida, aplica esses fatos a uma amostra da população.. Em primeiro lugar, deriva equações que relacionam os momentos da população aos parâmetros desconhecidos.
O próximo passo é extrair uma amostra da população que será usada para estimar os momentos da população. As equações geradas na etapa um são então resolvidas com a ajuda da média da amostra dos momentos da população. Isso dá a melhor estimativa dos parâmetros desconhecidos da população.
Matematicamente,
Considere uma amostra X1, X2, X3, —, XNorte a partir de f (x; θ1, θ2, —–, θmetro) .O objetivo é estimar os parâmetros θ1, θ2, —–, θmetro.
Que os momentos da população sejam (teóricos) uma1, uma2, ——–, umar, que são funções de parâmetros desconhecidos θ1, θ2, —–, θmetro.
Equacionando os momentos da amostra e os momentos da população, obtemos os estimadores de θ1, θ2, —–, θmetro.
2. Estimador de máxima verossimilhança (MLE)
Este método de encontrar estimadores pontuais tenta encontrar os parâmetros desconhecidos que maximizam a função de verossimilhança. Pegue um modelo conhecido e use os valores para comparar conjuntos de dados e encontrar a melhor correspondência para os dados.
Matematicamente,
Considere uma amostra X1, X2, X3, —, XNorte desligado (x; θ). O objetivo é estimar os parâmetros θ (escalar ou vetor).
A função de verossimilhança é definida como:
eu (θ; x1, X2, —, XNorte) = f (x1, X2, —, XNorte; θ)
Um MLE de θ é o valor θ ‘(uma função de amostra) que maximiza a função de verossimilhança
Se L é uma função diferenciável de θ, então a próxima equação de verossimilhança é usada para obter o MLE (θ ‘):
d / dθ (em (eu (θ; x1, X2, —, XNorte) = 0
Se θ é um vetor, então considera-se que as derivadas parciais obtêm as equações de verossimilhança.
Estimativa pontual vs. estimativa de intervalo
Simplesmente, Existem dois tipos principais de estimadores em estatísticas:
- Estimadores de ponto
- Estimadores de intervalo
A estimativa de ponto é o oposto da estimativa de intervalo.
A estimativa de pontos gera um valor único, enquanto a estimativa de intervalo gera uma gama de valores.
Um estimador de ponto é uma estatística usada para estimar o valor de um parâmetro desconhecido em uma população. Usa dados de amostra da população ao calcular uma única estatística que será considerada a melhor estimativa para o parâmetro desconhecido da população.

Fonte da imagem: Imagens do google
Pelo contrário, a estimativa de intervalo leva dados de amostra para estabelecer a faixa de valores possíveis de um parâmetro desconhecido em uma população. O intervalo do parâmetro é selecionado para estar dentro de um 95% ou mais provavelmente, também conhecido como intervalo de confiança. O intervalo de confiança descreve o quão confiável é uma estimativa e é calculado a partir dos dados observados. Os pontos finais dos intervalos são conhecidos como superior e limites de confiança mais baixos.
Notas finais
Obrigado pela leitura!
Espero que você tenha gostado da postagem e aumentado seu conhecimento da teoria de estimativa.
Por favor sinta-se à vontade para me contactar sobre Correio eletrônico
Qualquer coisa não mencionada ou você deseja compartilhar suas idéias? Sinta-se à vontade para comentar abaixo e eu entrarei em contato com você.
Sobre o autor
Aashi Goyal
Neste momento, Estou cursando bacharelado em tecnologia (B.Tech) em Engenharia Eletrônica e de Comunicação Universidad Guru Jambheshwar (GJU), Hisar. Estou muito animado com as estatísticas, aprendizado de máquina e aprendizado profundo.
A mídia mostrada nesta postagem não é propriedade da DataPeaker e é usada a critério do autor.





