Este artigo foi publicado como parte do Data Science Blogathon
Introdução
Os dados estão em toda parte no mundo dos dados de hoje e só podemos nos beneficiar deles se conseguirmos extrair informações dos dados. A visualização de dados é o aspecto mais atraente visualmente da análise de dados porque nos permite interagir com os dados. É aquela técnica mágica de transmitir informações a grandes grupos de pessoas com um único olhar e criar histórias interessantes a partir de dados.. Pandas é uma das ferramentas de análise de dados mais populares e amplamente utilizadas em Python. Ele também possui um recurso de plotagem integrado para amostras. Porém, quando se trata de visualização interativa, Os usuários de Python que não possuem habilidades de engenharia de front-end podem ter alguns desafios, como muitas bibliotecas, como D3, chart.js, requer algum conhecimento de JavaScript. Plotly e Twins são úteis neste ponto.
Quando há uma grande quantidade de dados e as empresas têm dificuldade em extrair informações críticas deles, a visualização de dados desempenha um papel importante na tomada de decisões críticas de negócios.
Plotly é uma biblioteca gráfica construída sobre d3.js que pode ser usada diretamente com os frames de dados do Pandas graças a outra biblioteca chamada Cufflinks.
Mostraremos como usar gráficos interativos Plotly com quadros de dados Pandas neste tutorial rápido.. Para manter as coisas simples, usaremos Jupyter Notebook (instalado usando a distribuição Anaconda com Python) e o famoso conjunto de dados do Titanic.
Visualização de dados em Python
Depois de completar a limpeza e manipulação de dados, a próxima etapa no processo de análise de dados é extrair percepções e conclusões significativas dos dados, o que pode ser alcançado por gráficos e tabelas. Python tem várias bibliotecas que podem ser usadas para este propósito. Em geral, somos ensinados apenas sobre as duas bibliotecas matplotlib e seaborn. Essas bibliotecas incluem ferramentas para a criação de gráficos de linha, gráfico de setores, gráficos de barra, plotagens de caixaDiagramas de caixa, Também conhecido como diagramas de caixa e bigode, são ferramentas estatísticas que representam a distribuição de um conjunto de dados. Esses diagramas mostram a mediana, Quartis e outliers, permitindo que a variabilidade e a simetria dos dados sejam visualizadas. Eles são úteis na comparação entre diferentes grupos e na análise exploratória, facilitando a identificação de tendências e padrões nos dados.... y una variedad de otros diagramas. Você provavelmente está se perguntando por que precisamos de outras bibliotecas para visualização de dados se já temos matplotlib e seaborn. Quando ouvi pela primeira vez sobre a trama e os gêmeos, Eu tinha a mesma pergunta na minha cabeça.
Completamente
O lançamento mais recente de Plotly foi 5.1.0, enquanto aquele com gêmeos era 0.17.5. Porque as versões mais antigas de botões de punho não são compatíveis com as versões de plotagem recém-lançadas, é essencial atualizar os dois pacotes ao mesmo tempo ou encontrar versões compatíveis. In Anaconda Prompt, execute os seguintes comandos para instalar o plotly (o en Terminal si usa OS o Ubuntu)
Plotly é uma biblioteca de código aberto e gráfica que permite plotagem interativa. Pitão, R, MATLAB, Arduino e REST, entre outros, estão entre as linguagens de programação suportadas pela biblioteca.
Cufflink é uma biblioteca Python que conecta plotly e pandas, nos permitindo desenhar gráficos diretamente em quadros de dados. É essencialmente um plugin.
Os gráficos são interativos, o que nos permite rolar acima dos valores, amplie e afaste os gráficos e identifique outliers no conjunto de dados. The Matplotlib e Seaborn Letters, por outro lado, eles são estáticos; não podemos ampliar ou reduzir a imagem, e todos os valores no gráfico não são detalhados. A característica mais importante do Plotly é que ele nos permite criar gráficos dinâmicos da web diretamente do Python, o que não é possível com matplotlib. Também podemos fazer gráficos e animações interativas a partir de dados geográficos, cientistas, estatísticas e finanças usando plotly.
Instalar no pc “enredo “ e “gêmeos“ usando um ambiente anaconda
conda install -c plotly plotly
conda install -c conda-forge abotoaduras-py
o usando pip
pip install plotly --upgrade
pip install abotoaduras - atualização
Carregando bibliotecas
Bibliotecas Pandas, Plotly e Cufflinks irão carregar primeiro. Porque plotly é uma plataforma online, requiere una credencial de inicio de sessãoo "Sessão" É um conceito-chave no campo da psicologia e da terapia. Refere-se a uma reunião agendada entre um terapeuta e um cliente, onde os pensamentos são explorados, Emoções e comportamentos. Essas sessões podem variar em duração e frequência, e seu principal objetivo é facilitar o crescimento pessoal e a resolução de problemas. A eficácia das sessões depende da relação entre o terapeuta e o terapeuta.. para usarla en línea. Usaremos o modo offline neste artigo, o que é suficiente para o Jupyter Notebook.
#importando pandas importar pandas como pd #importing plotly e botões de punho no modo offline
importar botões de punho como cf import plotly.offline cf.go_offline() cf.set_config_file(offline = False, world_readable = True)
Carregando conjunto de dados
Mencionamos que usaremos o conjunto de dados do Titanic, o que você pode tirar disso kaggle_link. Apenas o arquivo train.csv será usado.
df = pd.read_csv("train.csv")
df.head()

Histograma
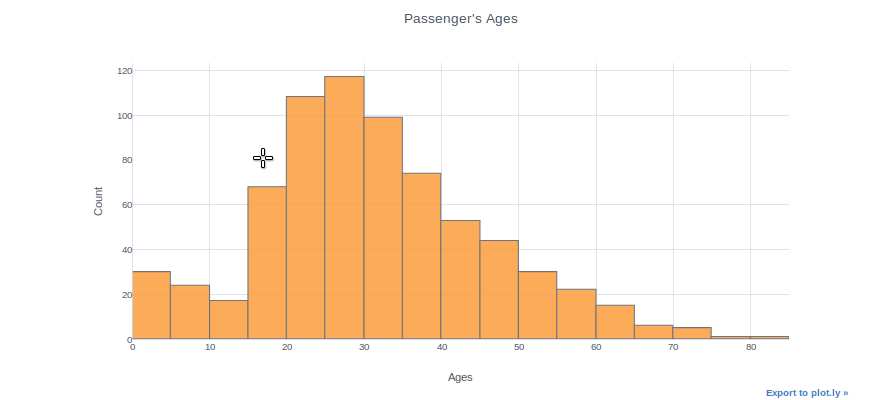
o histogramasHistogramas são representações gráficas que mostram a distribuição de um conjunto de dados. Eles são construídos dividindo o intervalo de valores em intervalos, o "Caixas", e contando quantos dados caem em cada intervalo. Essa visualização permite identificar padrões, tendências e variabilidade de dados de forma eficaz, facilitando a análise estatística e a tomada de decisões informadas em várias disciplinas.... se pueden utilizar para inspeccionar las distribuciones de una característica, como o recurso “Era” neste caso. Nós simplesmente usamos o (quadro de dados["nome da coluna"]) para selecionar uma coluna e, em seguida, adicionar a função iplot. Como exemplo, podemos especificar o tamanho do contêiner, o tema, o título e nomes dos eixos. Com o comando “ajuda (df.iplot)”, puede ver todos los parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... del parámetro iplot.
df["Era"].iplot(kind ="histograma", bins = 20, tema ="Branco", título ="Idade do Passageiro",xTitle ="Idades", yTitle ="Contar")
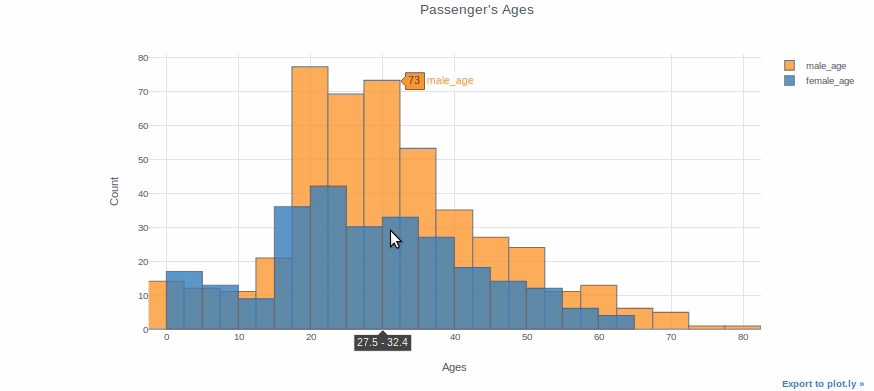
Você pode plotar duas distribuições diferentes como duas colunas diferentes se quiser compará-las. Por exemplo, vamos colocar as idades dos passageiros do sexo masculino e feminino no mesmo pacote.
df["male_age"]= df[df["Sexo"]=="macho"]["Era"]
df["idade_feminina"]= df[df["Sexo"]=="fêmea"]["Era"]df[["male_age","idade_feminina"]].iplot(kind ="histograma", bins = 20, tema ="Branco", título ="Idade do Passageiro",
xTitle ="Idades", yTitle ="Contar")
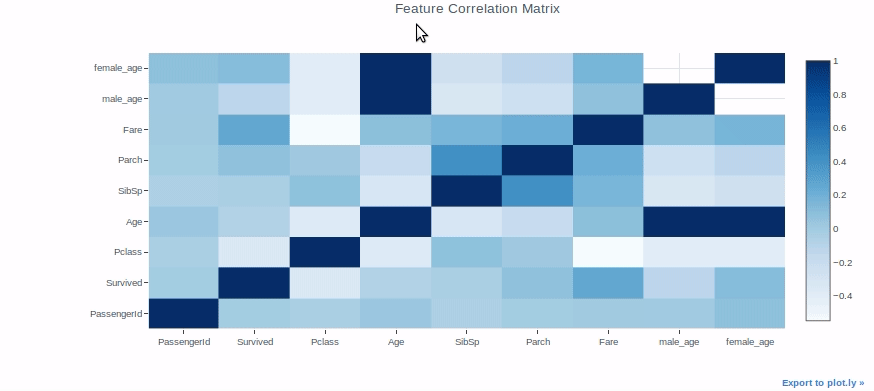
Mapa de caloruma "mapa de calor" é uma representação gráfica que usa cores para mostrar a densidade de dados em uma área específica. Comumente usado em análise de dados, Estudos de marketing e comportamentais, Esse tipo de visualização permite identificar padrões e tendências rapidamente. Através de variações cromáticas, Os mapas de calor facilitam a interpretação de grandes volumes de informações, ajudando a tomar decisões informadas....
Os mapas de calor podem ser usados para uma variedade de propósitos, mas vamos usá-los para verificar a correlação entre os recursos em um conjunto de dados como um exemplo.
Box plot
Os gráficos de caixa são extremamente úteis para interpretar rapidamente a assimetria nos dados, outliers e intervalos de quartil. Agora vamos usar um gráfico de caixa para mostrar a distribuição de “Avaliar” para cada classe do Titanic.
#obteremos ajuda de tabelas dinâmicas para obter valores de tarifa em diferentes colunas para cada classe. df[['Pclass', 'Tarifa']].pivô(colunas ="Pclass", valores ="Tarifa").iplot(kind = 'caixa')
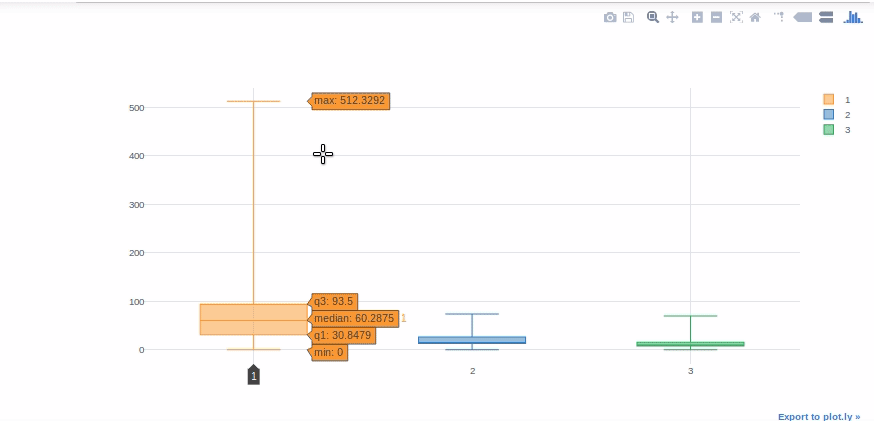
Gráfico de dispersãoUm gráfico de dispersão é uma representação visual que mostra a relação entre duas variáveis numéricas usando pontos em um plano cartesiano. Cada eixo representa uma variável, e a localização de cada ponto indica seu valor em relação a ambos. Esse tipo de gráfico é útil para identificar padrões, Correlações e tendências nos dados, facilitando a análise e interpretação de relações quantitativas....
Os gráficos de dispersão são comumente usados para visualizar a relação entre duas variáveis numéricas. Para variáveis “Avaliar” e “Era”, vamos usar diagramas de dispersão. "Categorias" nos permite mostrar as variáveis de uma característica selecionada em várias cores (sexo dos passageiros neste caso).
df.iplot(kind ="espalhar", tema ="Branco",x ="Era",y ="Tarifa",
categorias ="Sexo")
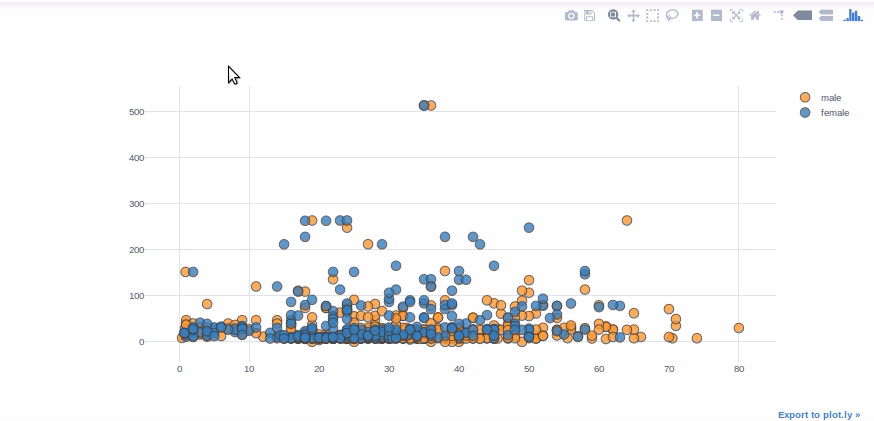
um lembrete rápido: o parâmetro “categorias” deve ser uma string ou coluna do tipo float64. Por exemplo, no exemplo do gráfico de bolhas, deve converter coluna “Sobreviveu” do tipo inteiro em float64 ou string.
Gráfico de bolhas
Podemos usar gráficos de bolhas para ver vários relacionamentos de variáveis ao mesmo tempo. Com os parâmetros de “categorias” e “Tamanho” no gráfico, podemos facilmente ajustar as subcategorias de cor e tamanho. Com o parâmetro “texto”, também podemos especificar a coluna de texto flutuante.
#convertendo a coluna Sobrevivido em float64 para poder usar em plotagem
df[['Sobreviveu']] = df[['Sobreviveu']].astype('float64', copy = False)df.iplot(kind = 'bolha', x ="Tarifa",y ="Era",categorias ="Sobreviveu", tamanho ="Pclass", text ="Nome", xTitle ="Tarifa", yTitle ="Era")
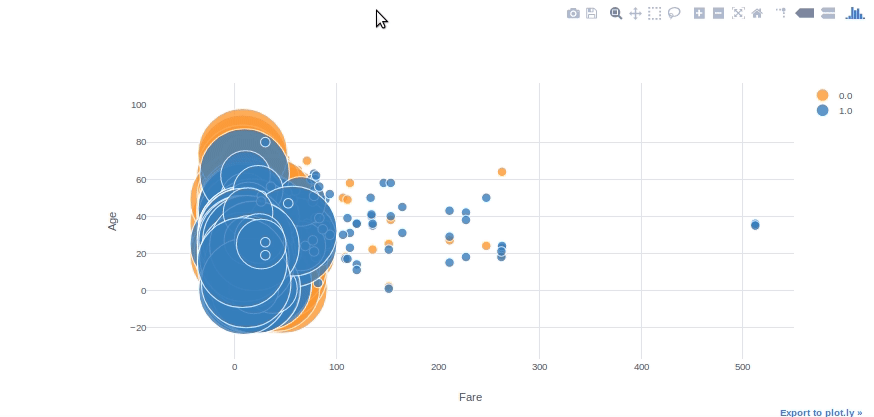
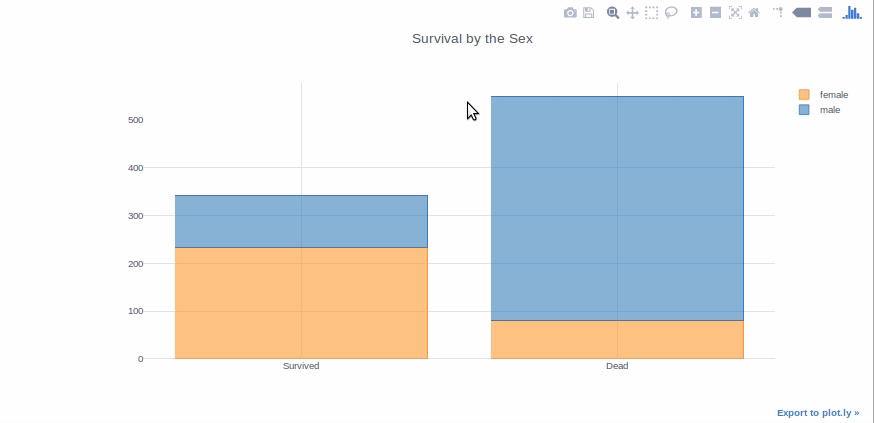
Gráfico de barrasO gráfico de barras é uma representação visual de dados que usa barras retangulares para mostrar comparações entre diferentes categorias. Cada barra representa um valor e seu comprimento é proporcional a ele. Esse tipo de gráfico é útil para visualizar e analisar tendências, facilitar a interpretação de informações quantitativas. É amplamente utilizado em várias disciplinas, como estatísticas, Marketing e pesquisa, devido à sua simplicidade e eficácia....
Os gráficos de barras são bons para apresentar dados de diferentes grupos que são comparados entre si. O que mais, pode ser usado empilhado para mostrar diferentes efeitos de variáveis. Faremos um gráfico de barras para mostrar a contagem de passageiros sobreviventes por sexo.
survived_sex = df[df['Sobreviveu']== 1]['Sexo'].valor_contas() dead_sex = df[df['Sobreviveu']== 0]['Sexo'].valor_contas() df1 = pd.DataFrame([survived_sex,dead_sex]) df1.index = ['Sobreviveu','Morto'] df1.iplot(kind = 'bar',moda bar ="pilha", título ="Sobrevivência pelo Sexo")
Tentei explicar tudo o mais simples possível. Espero que seja mais fácil para os recém-chegados entender o enredo.
Plotly também fornece gráficos científicos, Gráficos 3D, mapas e animações. Você pode visitar a documentação do plotly aqui para mais detalhes.
Dê uma olhada no EDA – Análise exploratória de dados com Python Pandas e SQL CLIQUE PARA LER
EndNote
Obrigado pela leitura!
Espero que você tenha gostado do artigo e aumentado seu conhecimento.
Por favor sinta-se à vontade para me contactar sobre Correio eletrônico
Qualquer coisa não mencionada ou você deseja compartilhar suas idéias? Sinta-se à vontade para comentar abaixo e eu entrarei em contato com você.
Sobre o autor
Hardikkumar M. Dhaduk
Analista de informações | Especialista em análise de dados digitais | Estudante de Ciência de Dados
Conecte-se comigo no Linkedin
Conecte-se comigo no Github
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





