Tabela de conteúdo
-
Introdução
-
Visão geral suave
-
Contras de usar PCA
-
Exemplo prático
-
conclusão
Introdução
“A inteligência artificial é a última invenção que a humanidade precisará fazer”. A citação definitivamente deixa claro que o aprendizado de máquina é o futuro e grandes oportunidades e benefícios para todos. Que este seja um novo começo para você aprender um algoritmo muito bom em aprendizado de máquina.
Como todos sabem, Muitas vezes nos deparamos com problemas de armazenamento e processamento de big data em tarefas de aprendizado de máquina, pois é um processo demorado e também surgem dificuldades na interpretação. Nem todos os recursos de dados são necessários para previsões. Esses dados ruidosos podem levar a um desempenho insatisfatório e ajuste excessivo do modelo.. Através deste artigo, deixe-me apresentar a você uma técnica de aprendizagem não supervisionada PCA (Análise do componente principal) o que pode ajudá-lo a lidar efetivamente com esses problemas até certo ponto e fornecer resultados de previsão mais precisos.
O PCA foi inventado no início do século 20 por Karl Pearson, semelhante a teorema do eixo principal em mecânica e é amplamente utilizado. Através deste método, nós realmente transformamos os dados em uma nova coordenada, onde aquele com a maior variação é o principal componente principal. Fornecendo-nos, assim, as melhores representações de dados possíveis.
Abstrato suave
Dados com muitas características podem ter correlações e duplicações dentro deles. Então, depois de obter os dados, a etapa principal é limpá-los removendo recursos irrelevantes e aplicando técnicas de engenharia de recursos que podem até fornecer resultados melhores do que os recursos originais. Análise do componente principal (PCA) é uma daquelas técnicas pelas quais a redução da dimensionalidade é possível (transformação linear de atributos existentes) e análise multivariada. Tem várias vantagens, incluindo redução de tamanho de dados (portanto, execução mais rápida), melhores visualizações com menos dimensões, maximizar a variância, reduz overfitting, etc.
O componente principal realmente significa as sequências de vetores de direção que diferem com base nas linhas de melhor ajuste. Também pode ser afirmado que esses componentes são autovetores da matriz de covariância.. Examinaremos esse conceito a seguir..
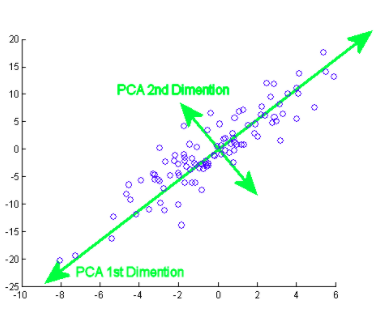
Como se faz isto? Inicialmente, você precisa encontrar os componentes principais de diferentes pontos de vista durante a fase de treinamento, daqueles que você pega os componentes importantes e menos correlacionados e ignora o resto deles, reduzindo assim a complexidade. O número de componentes principais pode ser menor ou igual ao número total de atributos.
Suponha que duas colunas X e Y sejam o 2 caracteristicas,
XY
1 4
2 3
3 4
4 6
5 8
Significar
X ‘= 3, E’ = 5
Covarianza
a (x, e) = Σ (XI – X ‘) (Yi – E') / n – 1, onde i = 1 um
C = [ a(x,x) a (x,e) ]
[a(e,x) a(e,e) ]
de forma similar, para mais recursos, encontramos a matriz de covariância completa com mais dimensões. Continuando a calcular os valores próprios, vetor, etc., podemos encontrar os principais componentes. Importar algoritmos e usar bibliotecas exatas facilita a identificação de componentes sem cálculos / operações manuais. Observe que o número de valores próprios / Os vetores próprios darão a você o número de dimensões e a quantidade de variância associada a esses componentes.
Contudo, pois existem vários componentes principais para Big Data, é selecionado principalmente com base no que representa a maior variação possível. Como resultado, os seguintes componentes também são decididos em ordem decrescente de variância dos componentes anteriores ordenando os autovalores, contanto que estes também não tenham uma correlação com os componentes principais anteriores. Em seguida, descartamos esses componentes com menos autovalores / vetor (menos significativo).
Na última etapa, usamos vetores de recursos para orientar os dados para aqueles representados pelos componentes principais (Análise do componente principal). Isso é feito multiplicando a transposição do conjunto de dados original pela transposição do vetor de característica.
Contras de usar PCA / Desvantagens
Você deve estar ciente de que a padronização de dados (que também inclui a conversão de variáveis categóricas em numéricas) é obrigatório antes de usar o PCA. Ao aplicar PCA, recursos independentes tornam-se menos interpretáveis porque esses componentes principais também não são legíveis ou interpretáveis. Também há chances de você perder informações durante o PCA.
Exemplo prático
Agora, vamos ver como um algoritmo é implementado em um conjunto de dados. Vou guiá-lo passo a passo por cada parte do código.
Confira este conjunto de dados. Este é o famoso conjunto de dados de flores IRIS, contendo características como comprimento sépala, comprimento da pétala, a largura da sépala e a largura da pétala, e a variável alvo é a espécie. O que você quer dizer com variável de destino é o valor / classe você precisa prever, que neste caso é o tipo de espécie à qual a flor pertence.
fonte: Wikipedia
Importando conjuntos de dados e bibliotecas básicas
Em primeiro lugar, vamos começar importando as bibliotecas necessárias,
importar numpy como np importar pandas como pd import matplotlib.pyplot as plt de sklearn.datasets import load_iris
Carregue os dados e exiba os nomes das características e classes para sua compreensão,
iris = load_iris() #Nomes de recursos e codificação de variáveis de destino imprimir(iris.feature_names) imprimir(iris.target_names) data = pd.DataFrame(iris.data) data.columns = iris.feature_names dados['CLASSE'] = iris.target data.head()
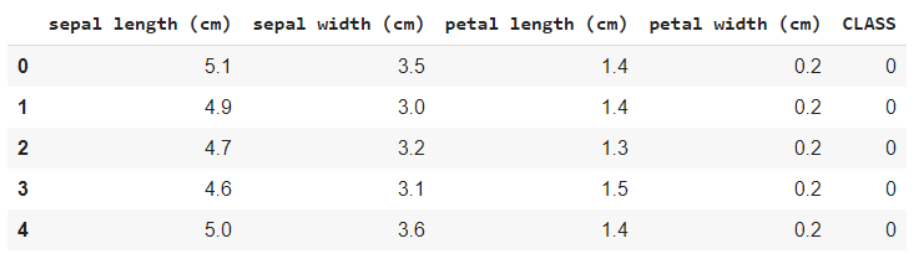
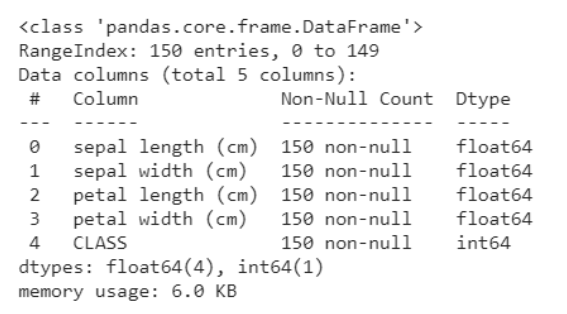
O seguinte snippet de código ajuda a obter uma análise dos dados, ou seja, quantas variáveis são categóricas e quantas são numéricas. O que mais, é claro abaixo que todas as linhas não são nulas, no caso de objetos nulos, obtemos a contagem e linhas / colunas em que estão presentes. Isso nos ajuda a passar pelas etapas de pré-processamento para limpar os dados.
data.info()
A função data.describe () geralmente fornece uma descrição estatística do conjunto de dados. Isso pode ser benéfico de várias maneiras, você pode usar esses dados para preencher os valores ausentes ou criar uma nova característica, e muito mais.
data.describe()
Aqui você está dividindo os dados nas características e nas variáveis de destino como X e e respectivamente. E ao usar o método de forma, sabe que os dados têm 150 linhas e 5 colunas no total, das quais 1 coluna é a sua variável de destino e outras 4 são as características / atributos.
x = data.iloc[:,:4] #recursos y = data.iloc[:,4] #alvo x.shape, y.shape
Fora de: ((150, 4), (150,))
Uma vez que todas as características são numéricas, é fácil para o modelo de treinamento. Se os dados contiverem variáveis categóricas, devemos primeiro convertê-los para numéricos, desde as maquinas / computadores podem lidar melhor com números.
Importação de biblioteca PCA
de sklearn.decomposition import PCA pca = PCA() X = pca.fit_transform(x) pca.get_covariance()

Account_variance = pca.explained_variance_ratio_ variância_explicada

Visualizações
com plt.style.context('dark_background'):
plt.figure(figsize =(6, 4))
plt.bar(faixa(4), variância_explicada, alfa = 0,5, alinhar = 'centro',
rótulo ="variância individual explicada")rodução
plt.ylabel('Razão de variância explicada')
plt.xlabel('Componentes principais')
plt.legend(loc ="melhor")
plt.tight_layout()
A partir das visualizações, obtém-se a intuição de que existem principalmente apenas 3 componentes com variância significativa, portanto, selecionamos o número de componentes principais como 3.
pca = PCA(n_components = 3) X = pca.fit_transform(x)
Teste de trem dividido
A divisão de teste de trem é um método comum de treinamento e avaliação. Em geral, previsões sobre os próprios dados treinados podem levar ao sobreajuste, dando resultados ruins para dados desconhecidos. Neste caso, dividindo os dados em conjuntos de treinamento e teste, você treina e, em seguida, prevê usando o modelo em 2 conjuntos diferentes, resolvendo assim o problema de overfitting.
de sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, e, test_size = 0.3, random_state = 20, stratify = y)
Treinamento de modelo
Nosso objetivo é identificar a classe / espécie a que a flor pertence dadas algumas de suas características. Portanto, este é um problema de classificação e o modelo que usamos usa K vizinhos mais próximos.
de sklearn.neighbors import KNeighboursClassifier model = KNeighborsClassifier(7) model.fit(X_train,y_train) y_pred = model.predict(X_test)
Previsões
de sklearn.metrics import confused_matrix de sklearn.metrics import precision_score cm = confusão_matriz(y_test, y_pred) #matriz de confusão imprimir(cm) imprimir(precisão_pontuação(y_test, y_pred))
A matriz de confusão mostrará a contagem de falsos positivos, falsos negativos, verdadeiros positivos e verdadeiros negativos.
A pontuação de precisão dirá a você o quão eficaz nosso modelo tem sido no fornecimento de previsões para novos dados. o 97% é uma pontuação muito boa, e é por isso que podemos dizer que o nosso é um bom modelo.
Você pode ver o código completo em esta colaboração do google planejado.
conclusão
Eu realmente espero que você tenha intuição sobre o PCA e também esteja familiarizado com o exemplo discutido acima. Não é tão complexo de digerir, apenas fique focado. Leia mais uma vez se achar útil e desenvolva você mesmo o algoritmo para entendê-lo melhor..
Que tenha um lindo dia !! 🙂
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





