Visão geral
- Aprenda web scraping em Python usando a biblioteca BeautifulSoup
- Web Scraping é uma técnica útil para converter dados não estruturados na web em dados estruturados
- BeautifulSoup é uma biblioteca eficiente disponível em Python para executar arranhões da web diferentes urllib
- Um conhecimento básico de HTML e tags HTML é necessário para fazer web scraping em Python
Introdução
A necessidade e a importância de extrair dados da web estão se tornando mais fortes e claras. A cada poucas semanas, Estou em uma situação em que precisamos extrair dados da web para construir um modelo de aprendizado de máquina.
Por exemplo, Na semana passada, estávamos pensando em criar um índiceo "Índice" É uma ferramenta fundamental em livros e documentos, que permite localizar rapidamente as informações desejadas. Geralmente, é apresentado no início de um trabalho e organiza os conteúdos de forma hierárquica, incluindo capítulos e seções. Sua correta preparação facilita a navegação e melhora a compreensão do material, tornando-se um recurso essencial para estudantes e profissionais de várias áreas.... coceira e sensação ao longo de vários cursos de ciência de dados disponível na internet. Isso não exigiria apenas encontrar novos cursos!, mas também pesquise na web por seus comentários e, em seguida, resuma-os em algumas métricas!
Este é um dos problemas / produtos cuja eficácia depende mais de web scraping e extração de informações (coleta de dados) qual das técnicas usadas para resumir os dados.
Observação: Também criamos um curso gratuito para este artigo: Introdução ao web scraping com Python. Este formato estruturado ajudará você a aprender melhor.
Maneiras de extrair informações da web
Existem várias maneiras de extrair informações da web. Uso de APIs sendo provavelmente a melhor maneira de extrair dados de um site. Quase todos os grandes sites como o Twitter, Facebook, Google, Twitter, StackOverflow fornece APIs para acessar seus dados de uma forma mais estruturada. Se você puder obter o que precisa por meio de uma API, quase sempre é a abordagem preferida sobre web scraping. Isso ocorre porque se você acessar dados estruturados do provedor, Por que você deseja criar um mecanismo para extrair as mesmas informações?
Lamentavelmente, nem todos os sites fornecem uma API. Alguns fazem isso porque não querem que os leitores extraiam muitas informações de uma forma estruturada, enquanto outros não fornecem API devido à falta de conhecimento técnico. O que você faz nesses casos? Nós vamos, precisamos raspar o site para obter as informações.
Pode haver outras maneiras, como feeds RSS, mas seu uso é limitado e, portanto, Não vou incluí-los na discussão aqui.

O que é Web Scraping?
Web scraping é uma técnica de software de computador para extrair informações de sites. Esta técnica é focada principalmente na transformação de dados não estruturados (Formato HTML) na web em dados estruturados (base de dadosUm banco de dados é um conjunto organizado de informações que permite armazenar, Gerencie e recupere dados com eficiência. Usado em várias aplicações, De sistemas corporativos a plataformas online, Os bancos de dados podem ser relacionais ou não relacionais. O design adequado é fundamental para otimizar o desempenho e garantir a integridade das informações, facilitando assim a tomada de decisão informada em diferentes contextos.... ou planilha).
Você pode realizar web scraping de várias maneiras, incluindo o uso do Google Docs em quase todas as linguagens de programação. Eu recorreria ao Python por sua facilidade e rico ecossistema. Tem uma biblioteca conhecida como 'BeautifulSoup’ o que ajuda nesta tarefa. Neste artigo, vou mostrar a maneira mais fácil de aprender web scraping usando programação python.
Para aqueles que precisam de uma maneira não programada para extrair informações de páginas da web, eles também podem olhar import.io . Fornece uma interface guiada por GUI para realizar todas as operações básicas de web scraping. Os hackers podem continuar lendo este artigo!!
Bibliotecas necessárias para web scraping
Como sabemos, Piton é uma linguagem de programação de código aberto. Você pode encontrar muitas bibliotecas para realizar uma função. Portanto, você precisa encontrar a melhor biblioteca para usar. eu prefiro Sopa linda (Biblioteca Python), porque é fácil e intuitivo trabalhar nisso. Precisamente, vou usar dois módulos python para extrair dados:
- Urllib2: É um módulo Python que pode ser usado para pesquisar URL. Defina funções e classes para ajudar com ações de URL (autenticação básica e sumária, redireciona, biscoitos, etc.). Para mais detalhes, Veja o página de documentação. Observação: urllib2 é o nome da biblioteca incluída no Python 2. Em seu lugar, você pode usar a biblioteca urllib.request incluída com python 3. A biblioteca urllib.request funciona da mesma maneira que urllib.request funciona em Python 2. Porque é já incluído não há necessidade de instalar.
- BeautifulSoup: É uma ferramenta incrível para extrair informações de uma página da web. Você pode usá-lo para extrair tabelas, listas, parágrafo e você também pode colocar filtros para extrair informações de páginas da web. Neste artigo, usaremos a versão mais recente do BeautifulSoup 4. Você pode consultar as instruções de instalação em seu página de documentação.
A BeautifulSoup não pesquisa o site por nós. Por isso, Eu uso urllib2 em combinação com a biblioteca BeautifulSoup.
Piton tem várias outras opções para extração de HTML além de BeatifulSoup. Aqui estão alguns outros:
Conceitos básicos: familiarize-se com HTML (rótulos)
Enquanto fazemos a web robusta, nós cuidamos das tags html. Portanto, devemos entendê-los bem. Se você já conhece o básico de HTML, você pode pular esta seção. Abaixo está a sintaxe básica do HTML: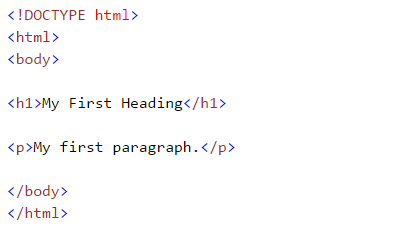 Esta sintaxe possui várias tags que são detalhadas abaixo:
Esta sintaxe possui várias tags que são detalhadas abaixo:
- : Os documentos HTML devem começar com uma declaração de tipo
- O documento HTML está contido entre e
- A parte visível do documento HTML está entre e
- Os cabeçalhos HTML são definidos com o
para rótulos - Os parágrafos HTML são definidos com o rótulo
Outras tags HTML úteis são:
- Os links HTML são definidos com o rótulo, “<uma href =“Http://www.test.com”>Este é um link para test.com</uma> ”
- As tabelas HTML são definidas com
, linha como
e as linhas são divididas em dados como 
- A lista HTML começa com
- (confuso) e
- Importe as bibliotecas necessárias:
- (arrumado). Cada item da lista começa com
Se você é novo nessas tags HTML, Eu também recomendo que você verifique Tutorial HTML de W3schools. Isso lhe dará uma compreensão clara das tags HTML.
Raspando una página web usando BeautifulSoup
Aqui, Estou extraindo dados de um Página da Wikipedia. Nosso objetivo final é extrair uma lista de capitais estaduais e territoriais da Índia. E alguns detalhes básicos como o estabelecimento, a velha capital e outros formam este página da wikipedia. Vamos aprender fazendo este projeto passo a passo:
#importar a biblioteca usada para consultar um site import urllib2 #se você estiver usando a versão python3 +, import urllib.request
#especifique o url wiki = "https://en.wikipedia.org/wiki/List_of_state_and_union_territory_capitals_in_India"
#Consulte o site e retorne o html para a variável 'página' page = urllib2.urlopen(wiki) #Para python 3 use urllib.request.urlopen(wiki)
#importe as funções de sopa bonita para analisar os dados retornados do site de bs4 import BeautifulSoup
#Analise o html na variável 'page', e armazene-o no formato Beautiful Soup sopa = BeautifulSoup(página)
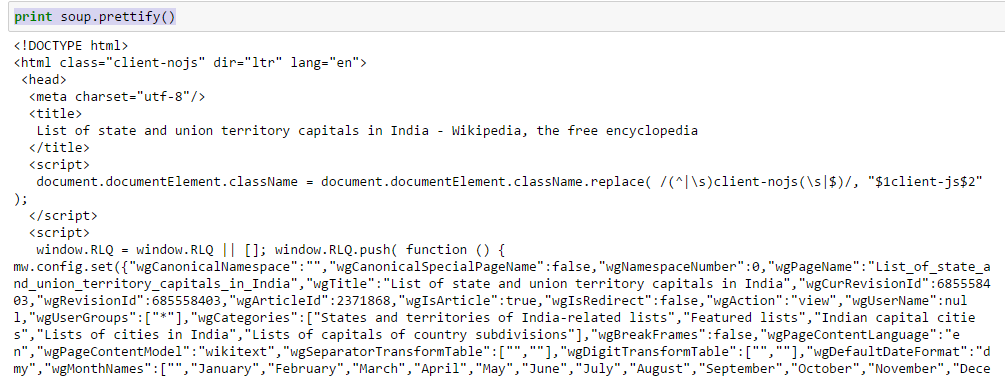
- Use a função “embelezar” para ver a estrutura aninhada da página HTML
 Acima, você pode ver a estrutura das tags HTML. Isso ajudará você a aprender sobre as diferentes tags disponíveis e como você pode brincar com elas para extrair informações.
Acima, você pode ver a estrutura das tags HTML. Isso ajudará você a aprender sobre as diferentes tags disponíveis e como você pode brincar com elas para extrair informações.
- Trabalhe com tags HTML
- sopa. : Retorna o conteúdo entre a tag de abertura e fechamento, incluindo etiqueta.
No[30]:sopa.título Fora[30]:<título>Lista de capitais estaduais e territoriais da união na Índia - Wikipedia, a enciclopédia livre</título>
- sopa. .fragmento: String de retorno dentro da tag fornecida
No [38]:sopa.título.fragmento Fora[38]:u'Lista de capitais estaduais e territoriais da união na Índia - Wikipedia, a enciclopédia livre'
- Encontre todos os links dentro das tags da página :: Nós sabemos isso, podemos marcar um link usando a tag ““. Então, devemos ir com a opção sopa. uma e deve retornar os links disponibilizados no site. Vamos fazer.
No [40]:sopa.uma Fora[40]:<a id ="principal"></uma>
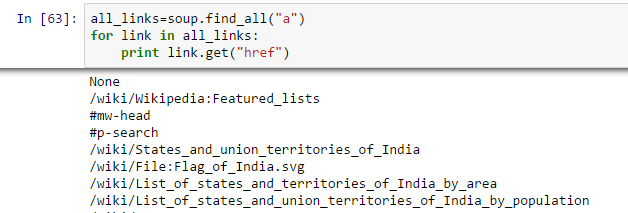
Acima, você pode ver que só temos uma saída. Agora, para extrair todos os links dentro , usaremos “encontrar tudo().

Acima, mostrar todos os links, incluindo títulos, links e outras informações. Agora, para mostrar apenas os links, devemos iterar sobre cada tag a e, em seguida, retornar o link usando o atributo “href” com pegue.

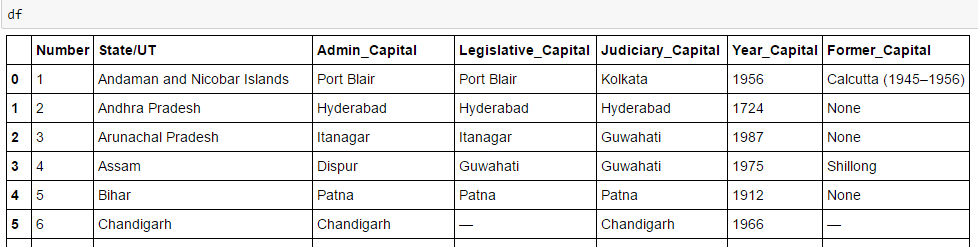
- Encontre a mesa certa: Como procuramos uma tabela para extrair informações sobre as capitais dos estados, devemos primeiro identificar a tabela correta. Vamos escrever o comando para extrair informações dentro de todos mesa rótulos.
all_tables = soup.find_all('tabela')Agora, para identificar a tabela correta, vamos usar o atributo “classe” da tabela e vamos usá-lo para filtrar a tabela correta. No Chrome, você pode verificar o nome da classe clicando com o botão direito na tabela necessária da página da web -> Inspecionar elemento -> Copie o nome da classe OU vá para a saída do comando acima e encontre o nome da classe na tabela certa.
right_table = soup.find('tabela', classe _ = 'cabeçalhos planas classificáveis wikitable') right_table Acima de, somos capazes de identificar a mesa certa.
Acima de, somos capazes de identificar a mesa certa. - Extraia as informações para DataFrame: Aqui, precisamos iterar em cada linha (tr) e, em seguida, atribua cada elemento de tr (td) para um variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... e adicione-o a uma lista. Vejamos primeiro a estrutura HTML da tabela (Não vou extrair informações para o cabeçalho da tabela
)  Acima, você pode notar que o segundo elemento de
Acima, você pode notar que o segundo elemento de
está dentro da etiqueta , não , então devemos cuidar disso. Agora, para acessar o valor de cada elemento, vamos usar a opção “procurar (text = True)” com cada elemento. Vamos ver o código: #Gerar listas A =[] B =[] C =[] D =[] E =[] F =[] G =[] para linha em right_table.findAll("tr"): células = row.findAll('td') states = row.findAll('º') #Para armazenar os dados da segunda coluna se len(células)== 6: #Extraia apenas o corpo da tabela, não o título A. anexar(células[0].achar(text = True)) B. anexar(estados[0].achar(text = True)) C.append(células[1].achar(text = True)) D.append(células[2].achar(text = True)) E. anexar(células[3].achar(text = True)) F. anexar(células[4].achar(text = True)) G.append(células[5].achar(text = True))#importe pandas para converter a lista em data frame importar pandas como pd df = pd.DataFrame(UMA,colunas =['Número']) df['State / UT']= B df['Admin_Capital']= C df['Legislative_Capital']= D df['Judiciary_Capital']= E df['Year_Capital']= F df['Former_Capital']= G df
Finalmente, temos dados no quadro de dados:

Do mesmo modo, você pode realizar outros tipos de web scraping usando “Sopa linda“. Isso reduzirá seus esforços manuais para coletar dados de páginas da web.. Você também pode olhar para outros atributos, como .parent, .conteúdo, .descendentes y .next_sibling, .prev_sibling e vários atributos para navegar usando o nome da tag. Isso o ajudará a remover páginas da web de forma eficaz.Mas, Por que não posso usar regex?
Agora, se você conhece expressões regulares, você pode estar pensando que pode escrever código usando regex que pode fazer o mesmo por você. Eu definitivamente tinha essa pergunta. Na minha experiência com BeautifulSoup e regex para fazer o mesmo, Eu descobri:
- O código escrito em BeautifulSoup geralmente é mais robusto do que o código escrito com expressões regulares. Códigos escritos com expressões regulares devem ser modificados com quaisquer mudanças nas páginas. Até a BeautifulSoup precisa disso em alguns casos, é que BeautifulSoup é relativamente melhor.
- Expressões regulares são muito mais rápidas do que BeautifulSoup, geralmente por um fator de 100 para dar o mesmo resultado.
Portanto, tudo se resume a velocidade versus robustez do código e não há um vencedor universal aqui. Se as informações que você está procurando podem ser extraídas com declarações simples de regex, você deve ir em frente e usá-los. Para quase qualquer trabalho complexo, Eu geralmente recomendo BeautifulSoup mais do que regex.
Nota final
Neste artigo, analisamos os métodos de web scraping que eles usam “BeautifulSoup” e “urllib2” e Python. Também analisamos os fundamentos do HTML e executamos a web scraping passo a passo enquanto resolvíamos um desafio.. Eu recomendo que você pratique isso e use-o para coletar dados de páginas da web.
Você acha útil este artigo? Compartilhe suas opiniões / pensamentos na seção de comentários abaixo.
Observação: Também criamos um curso gratuito para este artigo: Introdução ao web scraping com Python. Este formato estruturado ajudará você a aprender melhor.
Se você gostou do que acabou de ler e deseja continuar seu aprendizado sobre análise, inscreva-se em nossos e-mails, Siga-nos no Twitter ou como o nosso página do Facebook.
Relacionado




- A lista HTML começa com

 Acima, você pode ver a estrutura das tags HTML. Isso ajudará você a aprender sobre as diferentes tags disponíveis e como você pode brincar com elas para extrair informações.
Acima, você pode ver a estrutura das tags HTML. Isso ajudará você a aprender sobre as diferentes tags disponíveis e como você pode brincar com elas para extrair informações.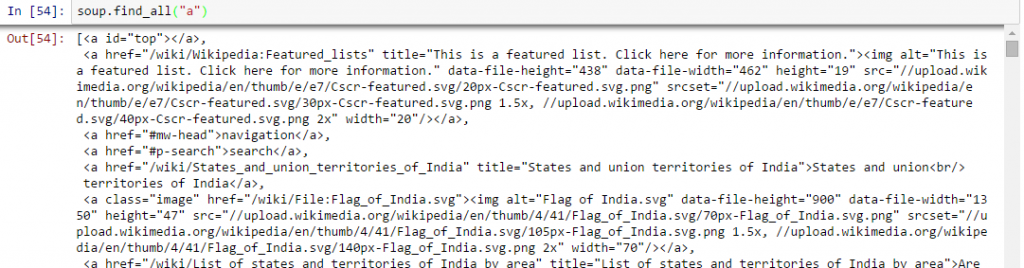
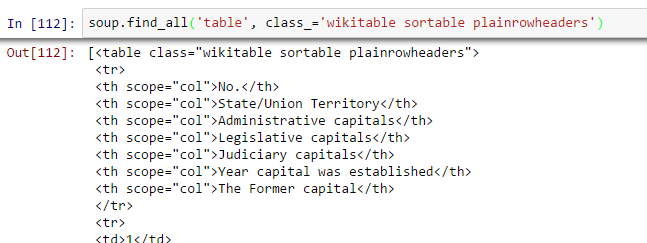 Acima de, somos capazes de identificar a mesa certa.
Acima de, somos capazes de identificar a mesa certa.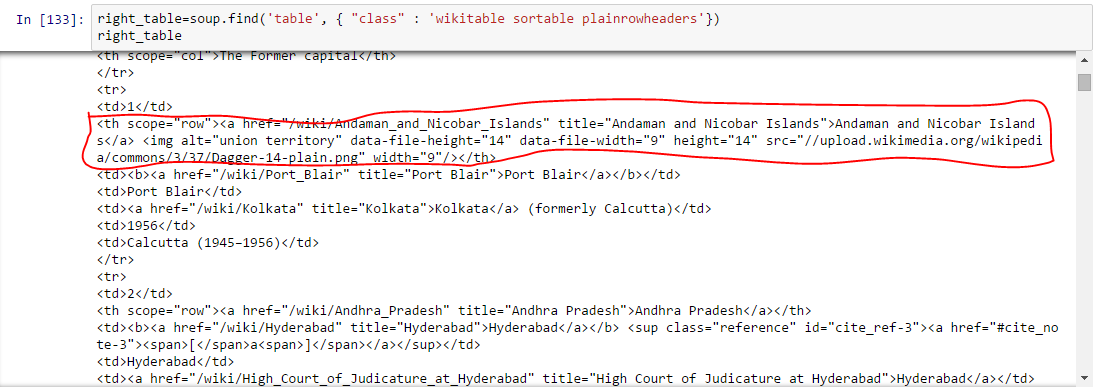 Acima, você pode notar que o segundo elemento de
Acima, você pode notar que o segundo elemento de