Quantos algoritmos de impulso você conhece?
Você pode citar pelo menos dois algoritmos de impulso em aprendizado de máquina?
Os algoritmos de impulso existem há anos e, porém, só recentemente eles se tornaram populares na comunidade de aprendizado de máquina. Mas, Por que esses algoritmos de impulso se tornaram tão populares?
Um dos principais motivos para o aumento na adoção de algoritmos de impulso são as competências de aprendizado de máquina. Os algoritmos de impulso fornecem superpoderes aos modelos de aprendizado de máquina para melhorar sua precisão de previsão. Uma rápida olhada nas competições Kaggle e DataHack Hackatones é evidência suficiente – Os algoritmos de impulso são extremamente populares!
Em poucas palavras, algoritmos de momentum muitas vezes superam modelos mais simples, como regressão logística e Árvores de decisão. De fato, A maioria de nossos finalistas da plataforma DataHack usa um algoritmo de impulso ou uma combinação de vários algoritmos de impulso.

Neste artigo, Apresentarei quatro algoritmos de boost populares que você pode usar em seu próximo aprendizado de máquina hackathon o proyecto.
4 Gerar algoritmos no aprendizado de máquina
- Máquina de aumento de gradienteGradiente é um termo usado em vários campos, como matemática e ciência da computação, descrever uma variação contínua de valores. Na matemática, refere-se à taxa de variação de uma função, enquanto em design gráfico, Aplica-se à transição de cores. Esse conceito é essencial para entender fenômenos como otimização em algoritmos e representação visual de dados, permitindo uma melhor interpretação e análise em... (GBM)
- Máquina de aumento de gradiente extremo (XGBM)
- LightGBM
- CatBoost
Introdução rápida ao Boosting (O que é Boosting?)
Imagine este cenário:
Você criou um modelo de regressão linear que oferece uma precisão decente do 77% no conjunto de dados de validação. A seguir, decide expandir seu portfólio criando um modelo de k-vizinho mais próximo (KNN) e um árvore de decisão modelo no mesmo conjunto de dados. Esses modelos deram uma precisão do 62% e ele 89% no conjunto de validação, respectivamente.
É óbvio que os três modelos funcionam de maneiras completamente diferentes.. Por exemplo, o modelo de regressão linear tenta capturar relacionamentos lineares nos dados, enquanto o modelo de árvore de decisão tenta capturar a não linearidade nos dados.
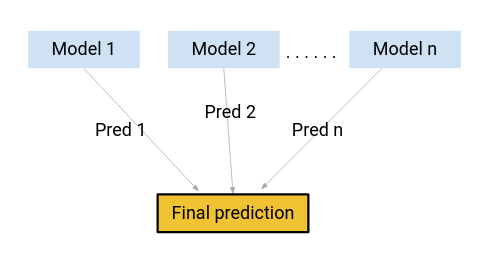
Que tal se, em vez de usar qualquer um desses modelos para fazer as previsões finais, usamos uma combinação de todos esses modelos?
Estou pensando em uma média das previsões desses modelos. Fazendo isso, poderíamos capturar mais informações dos dados, verdade?
Essa é principalmente a ideia por trás do aprendizado juntos.. E de onde vem o desejo?
O impulso é uma das técnicas utilizadas pelo conceito de aprendizagem conjunta. Um algoritmo de impulso combina vários modelos simples (também conhecido como alunos fracos ou estimadores de linha de base) para gerar o resultado final.
Veremos alguns dos algoritmos de momentum importantes neste artigo..
1. Máquina de aumento de gradiente (GBM)
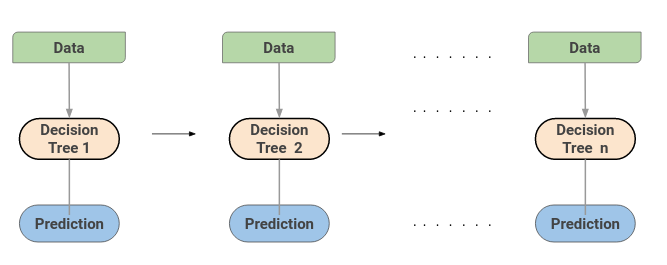
Uma máquina de aumento de gradiente ou GBM combina as previsões de várias árvores de decisão para gerar as previsões finais. Observe que todos os alunos fracos em uma máquina de aumento de gradiente são árvores de decisão.
Mas se usarmos o mesmo algoritmo, Como é melhor usar cem árvores de decisão do que usar uma única árvore de decisão? Como diferentes árvores de decisão capturam diferentes sinais / informação de dados?
Aqui está o truque: nós em cada árvore de decisão tomam um subconjunto diferente de características para selecionar a melhor divisão. Isso significa que as árvores individuais não são todas iguais e, portanto, pode capturar sinais diferentes dos dados.
O que mais, cada nova árvore leva em consideração os erros ou erros cometidos pelas árvores anteriores. Portanto, cada árvore de decisão sucessiva é baseada nos erros das árvores anteriores. É assim que as árvores em um algoritmo de máquina de aumento de gradiente são construídas sequencialmente.
Aqui está um artigo que explica o processo de ajuste de hiperparâmetros para o algoritmo GBM:
2. Máquina de aumento de gradiente extremo (XGBM)
Extreme Gradient Boosting ou XGBoost é outro algoritmo de aumento popular. De fato, O XGBoost é simplesmente uma versão improvisada do algoritmo GBM!! O procedimento de trabalho do XGBoost é o mesmo do GBM. Árvores no XGBoost são construídas sequencialmente, tentando consertar os erros das árvores acima.
Aqui está um artigo que explica intuitivamente a matemática por trás do XGBoost e também implementa o XGBoost em Python:

Mas existem certos recursos que tornam o XGBoost um pouco melhor do que o GBM:
- Um dos pontos mais importantes é que o XGBM implementa pré-processamento paralelo (a nivel de nóO Nodo é uma plataforma digital que facilita a conexão entre profissionais e empresas em busca de talentos. Através de um sistema intuitivo, permite que os usuários criem perfis, Compartilhar experiências e acessar oportunidades de trabalho. Seu foco em colaboração e networking torna o Nodo uma ferramenta valiosa para quem deseja expandir sua rede profissional e encontrar projetos que se alinhem com suas habilidades e objetivos....) o que o torna mais rápido do que GBM.
- XGBoost también incluye una variedad de técnicas de regularizaçãoA regularização é um processo administrativo que busca formalizar a situação de pessoas ou entidades que atuam fora do marco legal. Esse procedimento é essencial para garantir direitos e deveres, bem como promover a inclusão social e econômica. Em muitos países, A regularização é aplicada em contextos migratórios, Trabalhista e Tributário, permitindo que aqueles que estão em situação irregular tenham acesso a benefícios e se protejam de possíveis sanções.... que reducen el sobreajuste y mejoran el rendimiento general. Você pode selecionar a técnica de regularização definindo os hiperparâmetros do algoritmo XGBoost
Obtenga información sobre los diferentes hiperparámetros de XGBoost y cómo juegan un papel en el proceso de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... del modelo aquí:
O que mais, se você estiver usando o algoritmo XGBM, você não precisa se preocupar em imputar valores ausentes em seu conjunto de dados. O modelo XGBM pode lidar com valores ausentes por conta própria. Durante o processo de treinamento, o modelo aprende se os valores ausentes devem estar no nó direito ou esquerdo.
3. LightGBM
O algoritmo de aumento de LightGBM está se tornando mais popular a cada dia devido à sua velocidade e eficiência. LightGBM pode lidar com grandes quantidades de dados com facilidade. Mas observe que este algoritmo não funciona bem com um pequeno número de pontos de dados.
Vamos parar um momento para entender por que isso acontece..
Árvores em LightGBM têm crescimento de folhas, em vez de crescimento nivelado. Depois da primeira divisão, a próxima divisão é feita apenas no nó folha que tem a maior perda delta.
Considere o exemplo que ilustrei na imagem a seguir:
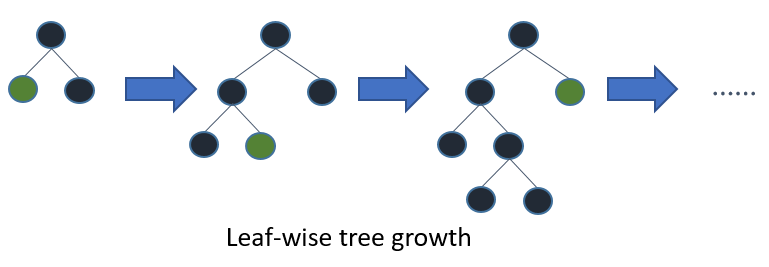
Depois da primeira divisão, o nó esquerdo teve uma perda maior e é selecionado para a próxima divisão. Agora, nós temos três nós de folha e o nó de folha do meio teve a maior perda. A divisão do algoritmo LightGBM por folhas permite que você trabalhe com grandes conjuntos de dados.
Para acelerar o processo de treinamento, LightGBM utiliza un método basado en histogramasHistogramas são representações gráficas que mostram a distribuição de um conjunto de dados. Eles são construídos dividindo o intervalo de valores em intervalos, o "Caixas", e contando quantos dados caem em cada intervalo. Essa visualização permite identificar padrões, tendências e variabilidade de dados de forma eficaz, facilitando a análise estatística e a tomada de decisões informadas em várias disciplinas.... para seleccionar la mejor división. Para cualquier variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... contínuo, em vez de usar os valores individuais, estes são divididos em recipientes ou baldes. Isso acelera o processo de treinamento e reduz o uso de memória..
Aqui está um excelente artigo comparando os algoritmos LightGBM e XGBoost:
4. CatBoost
Como o nome sugere, CatBoost é um algoritmo de impulso que pode lidar com variáveis categóricas em dados. A maioria dos algoritmos de aprendizado de máquina não funciona com strings ou categorias nos dados. Portanto, converter variáveis categóricas em valores numéricos é uma etapa essencial de pré-processamento.
CatBoost pode lidar internamente com variáveis categóricas nos dados. Essas variáveis são transformadas em numéricas usando várias estatísticas em combinações de características.
Se você quiser entender a matemática por trás de como essas categorias são convertidas em números, você pode ler este artigo:

Outra razão pela qual CatBoost é amplamente utilizado é que funciona bem com o conjunto padrão de hiperparâmetros. Portanto, como usuário, não precisamos perder muito tempo ajustando os hiperparâmetros.
Aqui está um artigo que implementa CatBoost em um desafio de aprendizado de máquina:
Notas finais
Neste artigo, Cobrimos os fundamentos da aprendizagem em conjunto e discutimos o 4 tipos de algoritmos de reforço. Você está interessado em aprender sobre outros métodos de aprendizagem conjunta?? Você deve consultar o seguinte artigo:
Com quais outros algoritmos de impulso você trabalhou? Você teve sucesso com esses algoritmos de impulso? Compartilhe suas idéias e experiências comigo na seção de comentários abaixo..





