Este artigo foi publicado como parte do Data Science Blogathon
Introdução
Limpeza de dados é o processo de análise de dados para encontrar valores incorretos, corrompido e ausente e removê-los para torná-los adequados para entrada para análise de dados e vários algoritmos de aprendizado de máquina.
É a etapa principal e fundamental realizada antes que qualquer análise dos dados possa ser realizada.. Não existem regras definidas a seguir para a limpeza de dados. Depende totalmente da qualidade do conjunto de dados e do nível de precisão a ser alcançado.
Razões para corrupção de dados:
- Os dados são coletados de várias fontes estruturadas e não estruturadas e, em seguida, combinados, levando a valores duplicados e incorretamente rotulados.
- Diferentes definições de dicionário de dados para dados armazenados em vários locais.
- Erro de entrada manual / erros tipográficos.
- Capitalização errada.
- Categorias: / classes erradas.
Qualidade de dados
A qualidade dos dados é de extrema importância para a análise. Existem vários critérios de qualidade que precisam ser verificados:

Atributos de qualidade de dados

- Eu completo: Definido como a porcentagem de entradas que são concluídas no conjunto de dados. A porcentagem de valores ausentes no conjunto de dados é um bom indicador da qualidade do conjunto de dados..
- Precisão: É definido como o mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... onde as entradas no conjunto de dados estão próximas de seus valores reais.
- Uniformidade: Definido como a extensão em que os dados são especificados usando a mesma unidade de medida.
- Consistência: É definido como a extensão em que os dados são consistentes no mesmo conjunto de dados e em vários conjuntos de dados.
- Validade: É definido como o grau em que os dados estão em conformidade com as restrições aplicadas pelas regras de negócios. Existem várias limitações:

Relatório de Perfil de Dados
Perfil de dados é o processo de explorar nossos dados e encontrar informações a partir deles. O Pandas Profiling Report é a maneira mais rápida de extrair informações abrangentes sobre o seu conjunto de dados. A primeira etapa para a limpeza de dados é realizar uma análise exploratória de dados.
Como usar o perfil dos pandas:
Paso 1: O primeiro passo é instalar o pacote de perfis pandas usando o comando pip:
pip install pandas-profilingPaso 2: Carregue o conjunto de dados usando o pandas:
import pandas as pddf = pd.read_csv(r"C:UsersDellDesktopDatasethousing.csv")
Paso 3: Leia as primeiras cinco linhas:
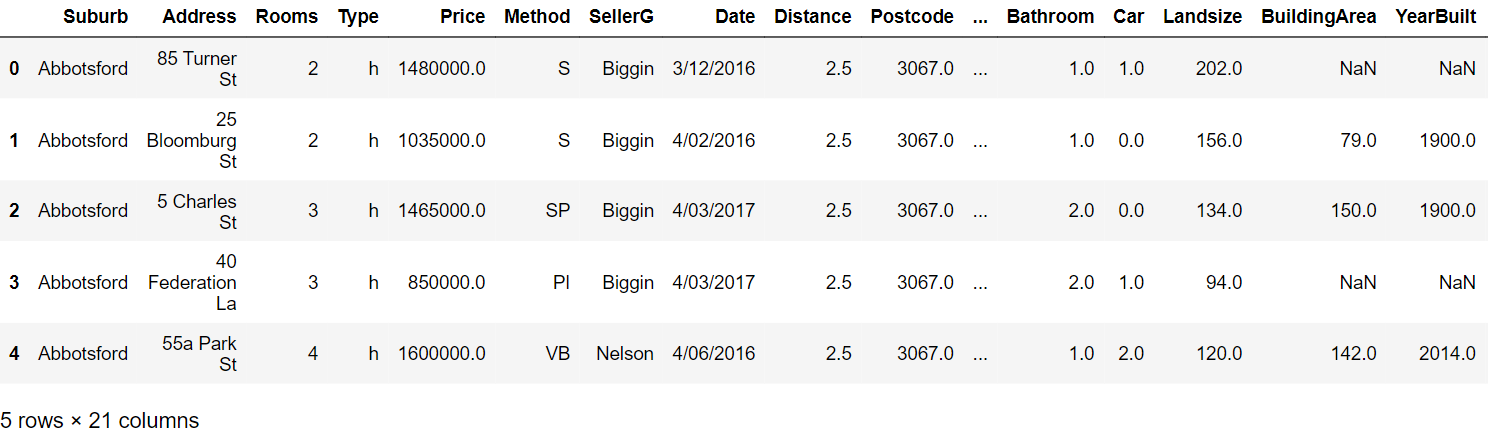
Paso 4: Gere o relatório de criação de perfil com os seguintes comandos:
from pandas_profiling importar ProfileReportprof = ProfileReport(df)prof.to_file(output_file="output.html")
Relatório de criação de perfil:
O relatório de criação de perfil consiste em cinco partes: descrição geral, variáveis, interações, correlação e valores ausentes.
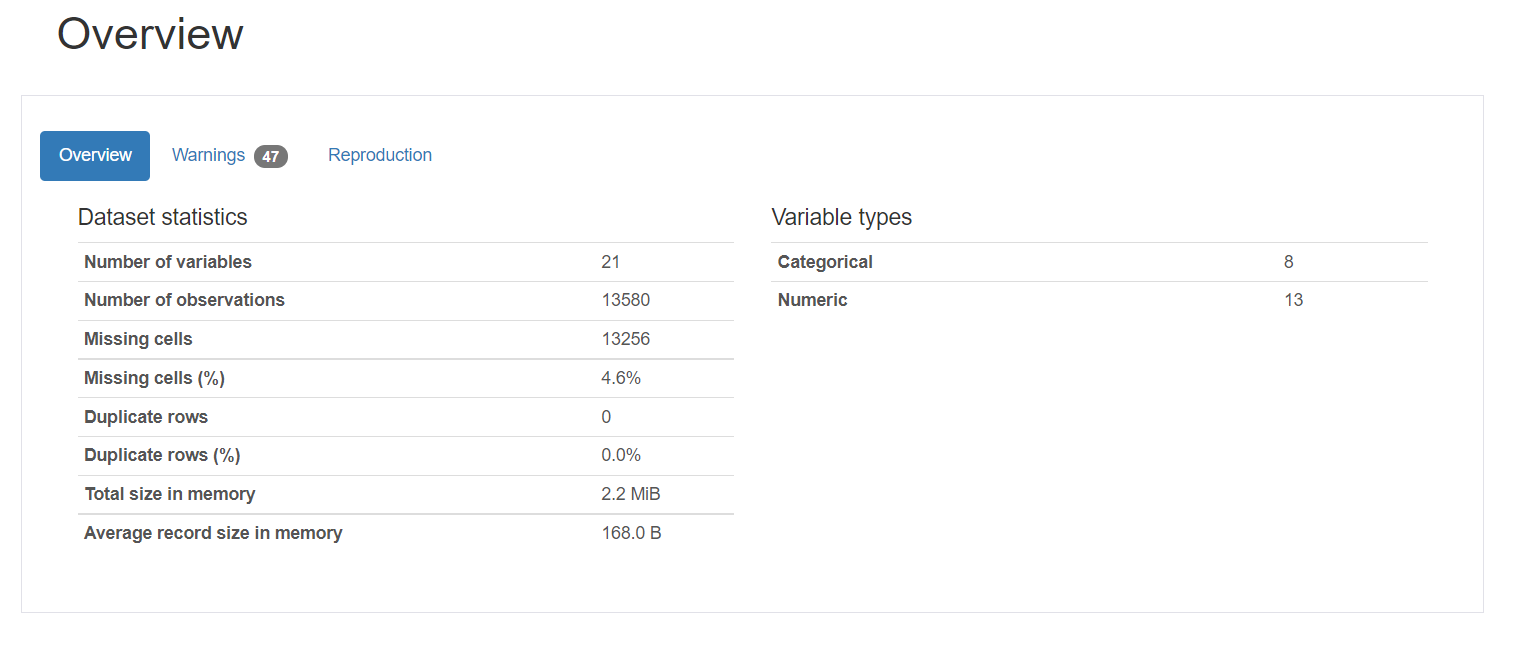
1. Visão geral fornece estatísticas gerais sobre o número de variáveis, o número de observações, os valores ausentes, duplicatas e o número de variáveis categóricas e numéricas.
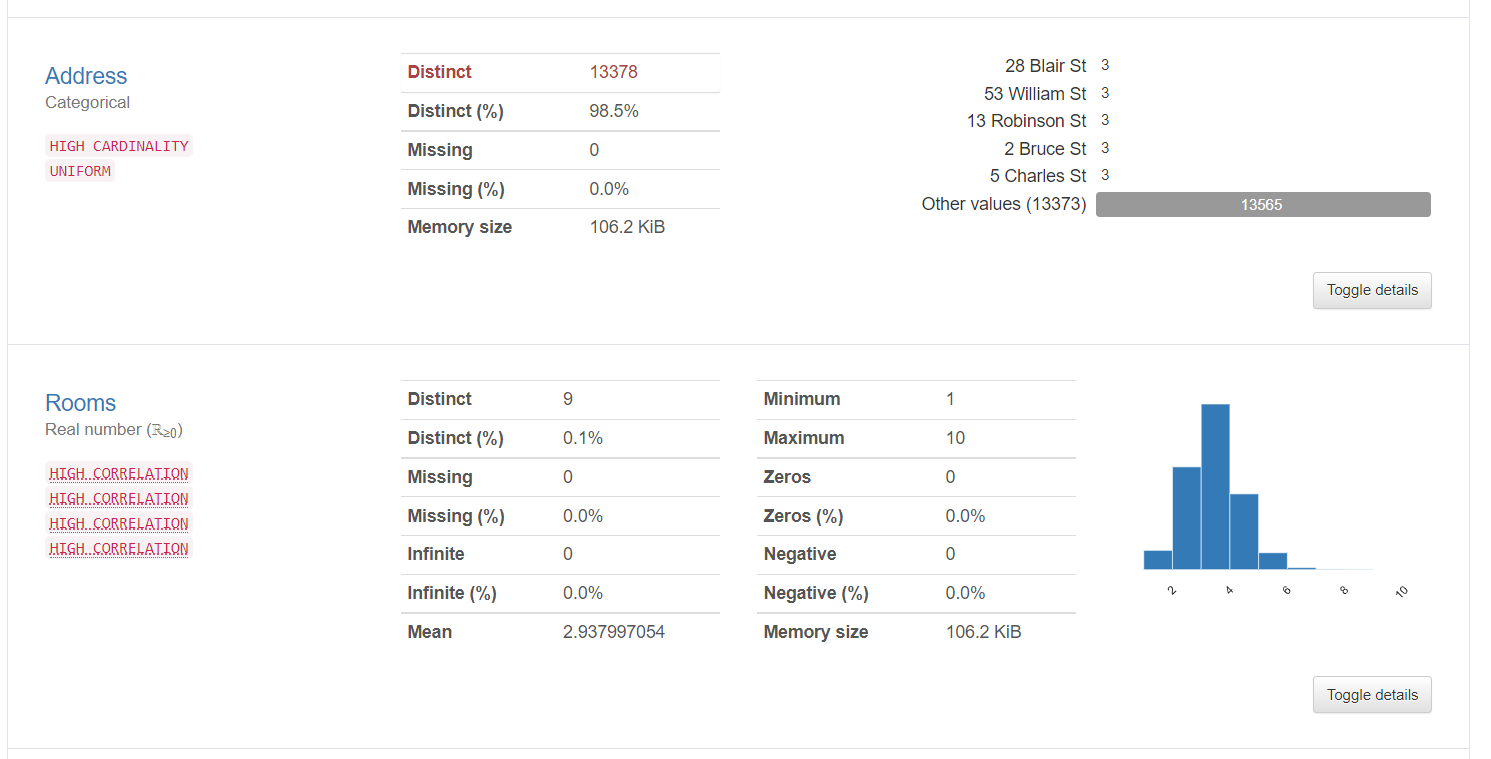
2. As informações do variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... fornece informações detalhadas sobre os diferentes valores, os valores ausentes, a média, a medianaA mediana é uma medida estatística que representa o valor central de um conjunto de dados ordenados. Para calculá-lo, Os dados são organizados do menor para o maior e o número no meio é identificado. Se houver um número par de observações, Os dois valores principais são calculados em média. Este indicador é especialmente útil em distribuições assimétricas, uma vez que não é afetado por valores extremos...., etc. Aqui estão as estatísticas sobre uma variável categórica e uma variável numérica:
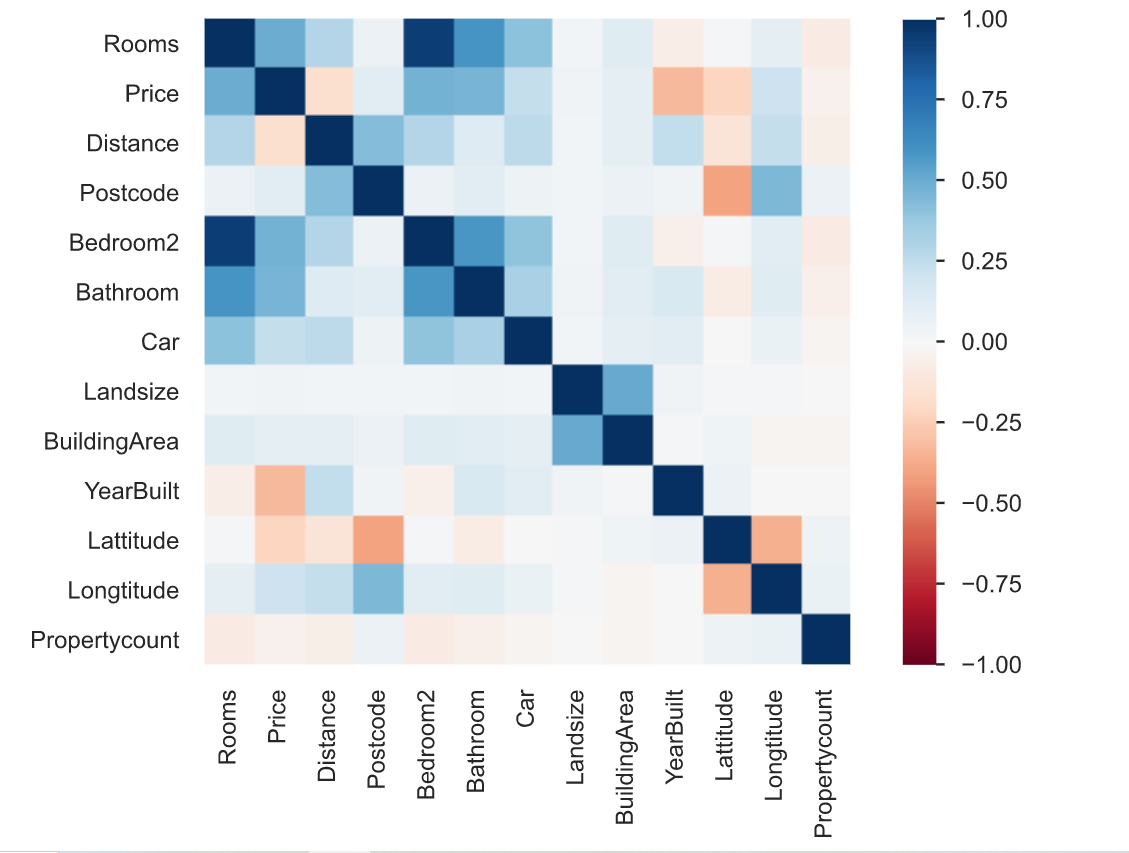
3. A correlação é definida como o grau em que duas variáveis estão relacionadas entre si. O relatório de criação de perfil descreve a correlação de diferentes variáveis entre si na forma de um mapa de calor.
Interações: esta parte do relatório mostra as interações das variáveis entre si. Você pode selecionar qualquer variável nos respectivos eixos.
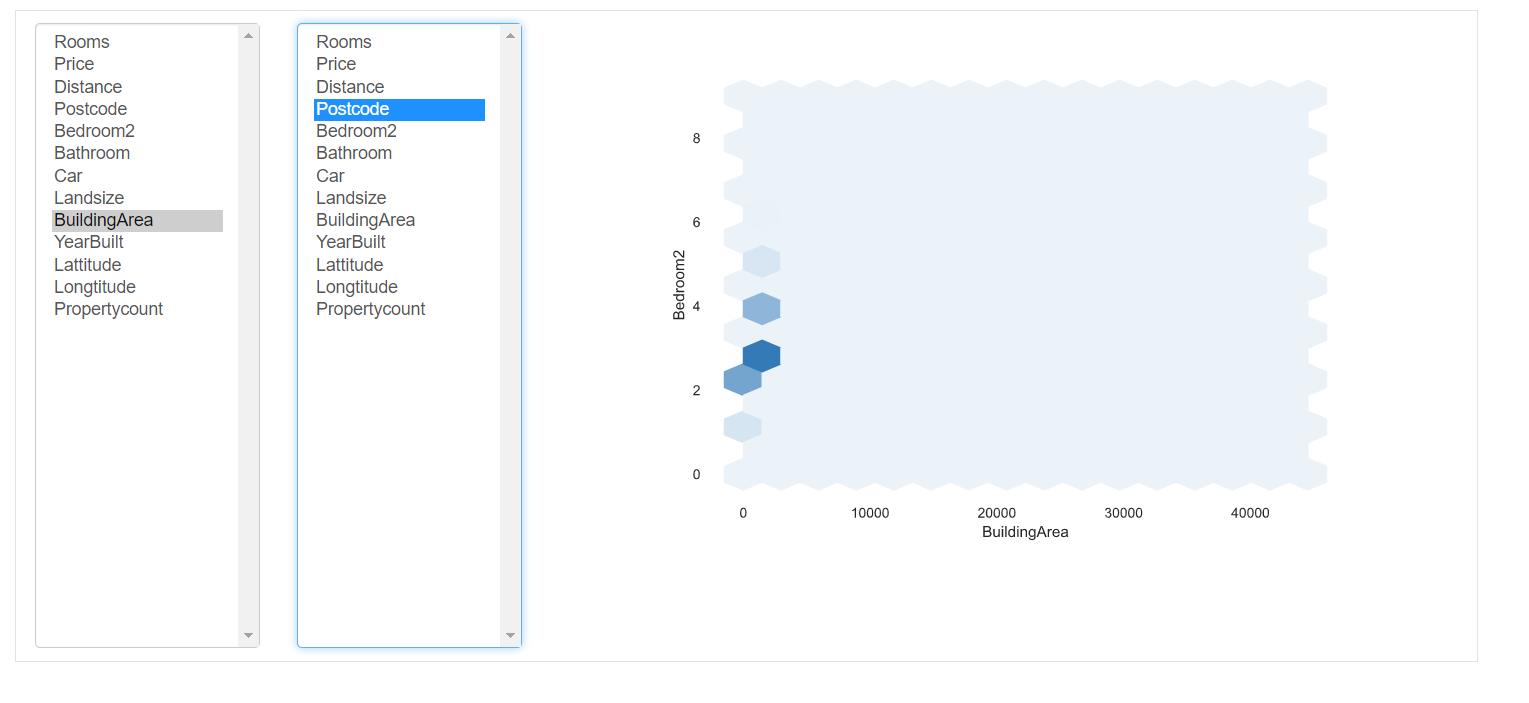
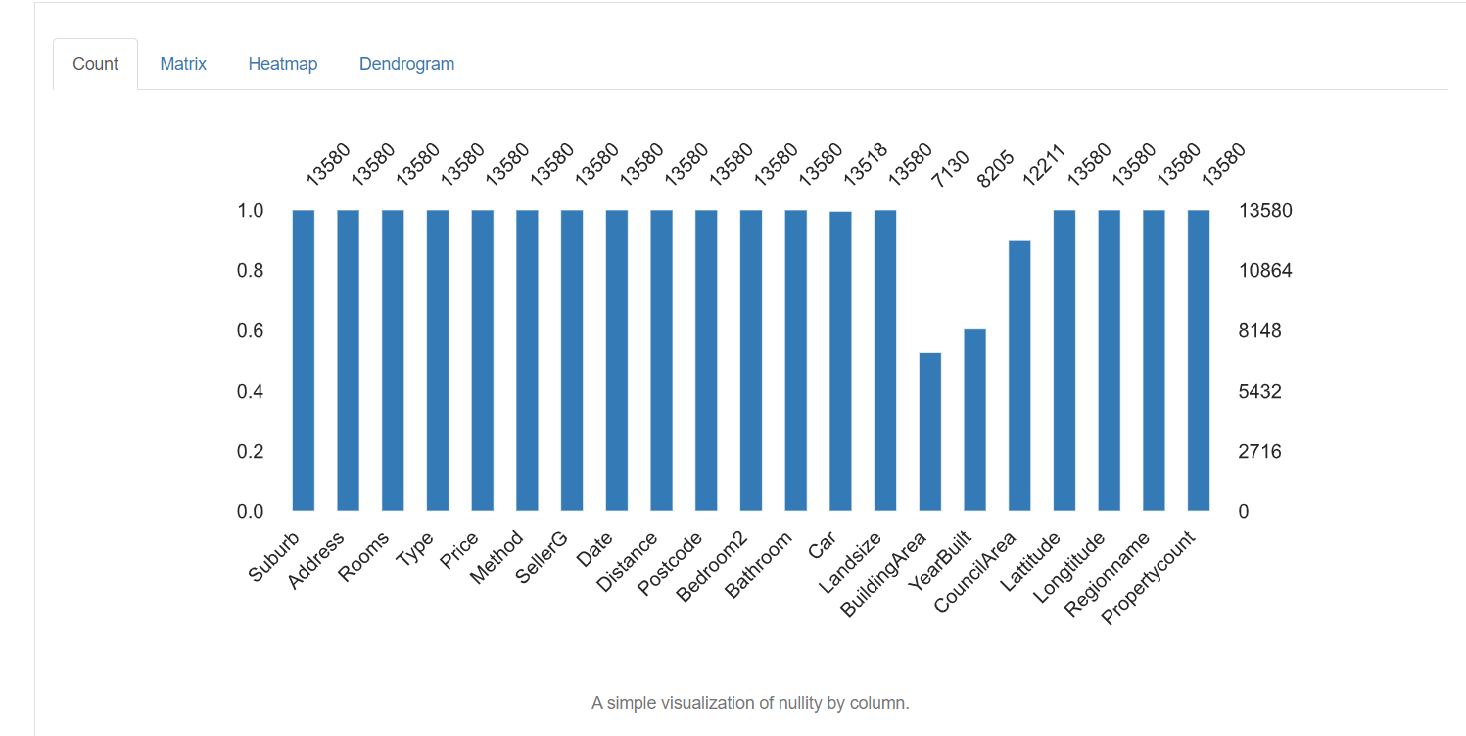
5. Valores ausentes: representa o número de valores ausentes em cada coluna.
Técnicas de limpeza de dados
Agora temos conhecimento detalhado sobre os dados ausentes, valores incorretos e categorias erradas no conjunto de dados. Agora veremos algumas das técnicas usadas para limpar dados. Depende totalmente da qualidade do conjunto de dados, os resultados a serem obtidos de como você lida com seus dados. Algumas das técnicas são as seguintes:
Tratamento de valores ausentes:
Lidar com valores ausentes é a etapa mais importante na limpeza de dados. A primeira pergunta a se fazer é por que os dados estão faltando?? Faltando apenas porque o operador de entrada de dados não registrou ou foi deixado vazio intencionalmente? Você também pode revisar a documentação para encontrar o motivo para o mesmo.
Existem diferentes maneiras de lidar com esses valores ausentes:
1. Elimine os valores ausentes: A maneira mais fácil de lidar com eles é apenas remover todas as linhas que contêm valores ausentes. Se você não quiser descobrir por que os valores estão faltando e você só tem uma pequena porcentagem de valores faltantes, você pode removê-los usando o seguinte comando:
Porém, não é aconselhável porque todos os dados são importantes e têm grande importância para os resultados gerais. Em geral, a porcentagem de entradas que faltam em uma determinada coluna é alta. Então desistir não é uma boa opção.
2. Imputação: Imputação é o processo de substituição de valores nulos / perdido por algum valor. Para colunas numéricas, uma opção é substituir cada entrada em falta na coluna pelo valor médio ou pelo valor mediano. Outra opção pode ser gerar números aleatórios entre um intervalo de valores adequados para a coluna. O intervalo pode ser entre a média e o desvio padrão da coluna. Você pode simplesmente importar um imputador do pacote scikit-learn e realizar a imputação da seguinte forma:
from sklearn.impute import SimpleImputer
#Imputation
my_imputer = SimpleImputer()
imputed_df = pd.DataFrame(my_imputer.fit_transform(df))Tratamento de duplicatas:
As linhas duplicadas geralmente ocorrem quando os dados são combinados de várias fontes. Às vezes, replica. Um problema comum é quando os usuários têm o mesmo número de identificação ou o formulário foi enviado duas vezes.
A solução para essas tuplas duplicadas é simplesmente removê-las. Você pode usar a função única () para descobrir os valores únicos presentes na coluna e, em seguida, decidir quais valores precisam ser removidos.
Codificação:
A codificação de caracteres é definida como o conjunto de regras definidas para o mapeamento um-para-um de strings de bytes binários brutos para strings de texto legíveis por humanos. Várias codificações estão disponíveis: ASCII, utf-8, US-ASCII, utf-16, utf-32, etc.
Você pode notar que alguns dos campos de caracteres de texto têm padrões irregulares e irreconhecíveis. Isso ocorre porque utf-8 é a codificação Python padrão. Todo o código está em utf-8. Portanto, quando os dados vêm de várias fontes estruturadas e não estruturadas e são mantidos em um lugar comum, padrões irregulares são observados no texto.
A solução para o problema acima é primeiro descobrir a codificação de caracteres do arquivo com a ajuda do módulo chardet em Python da seguinte forma:
import chardetwith open("C:/Users/Desktop/Dataset/housing.csv",'rb') as rawdata:result = chardet.detect(rawdata.read(10000))# check what the character encoding might beprint(result)
Depois de encontrar o tipo de codificação, se diferente de utf-8, salve o arquivo usando codificação “utf-8” usando o seguinte comando.
df.to_csv("C:/Users/Desktop/Dataset/housing.csv")Dimensionamento e padronizaçãoA padronização é um processo fundamental em várias disciplinas, que busca estabelecer padrões e critérios uniformes para melhorar a qualidade e a eficiência. Em contextos como engenharia, Educação e administração, A padronização facilita a comparação, Interoperabilidade e compreensão mútua. Ao implementar normas, a coesão é promovida e os recursos são otimizados, que contribui para o desenvolvimento sustentável e a melhoria contínua dos processos....
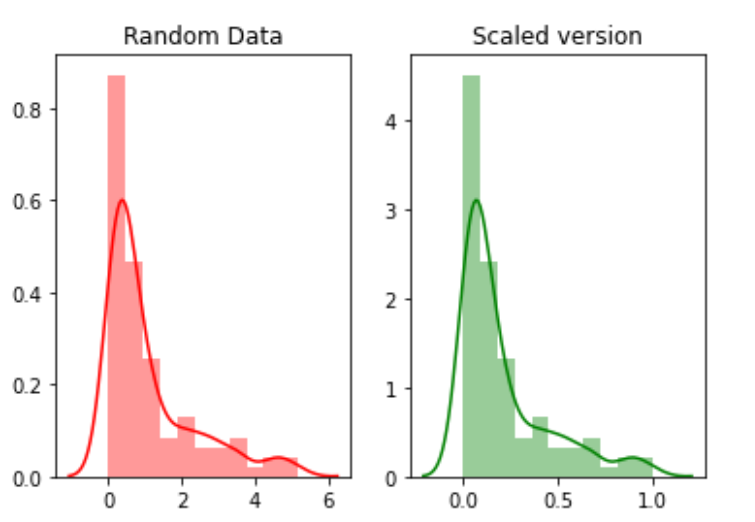
Escala refere-se a transformar o intervalo de dados e alterá-lo para algum outro intervalo de valores. Isso é benéfico quando queremos comparar diferentes atributos na mesma base.. Um exemplo útil pode ser a conversão de moeda.
Por exemplo, nós vamos criar 100 pontos aleatórios de uma distribuição exponencial e, em seguida, vamos representá-los. Finalmente, vamos convertê-los para uma versão em escala usando o pacote python mlxtend.
# for min_max scalingfrom mlxtend.preprocessing import minmax_scaling# plotting packagesimport seaborn as snsimport matplotlib.pyplot as plt
Agora escalando os valores:
random_data = np.random.exponential(size=100)# mix-max scale the data between 0 and 1scaled_version = minmax_scaling(random_data, columns=[0])
Finalmente, traçando as duas versões.
A normalização se refere à mudança da distribuição dos dados para que possa representar uma curva em sino onde os valores dos atributos são igualmente distribuídos na média. O valor da média e da mediana é o mesmo. Este tipo de distribuição também é chamado de distribuição Gaussiana.. É necessário para os algoritmos de aprendizado de máquina que assumem que os dados são normalmente distribuídos.
Agora, vamos normalizar os dados usando a função boxcox:
from scipy import statsnormalized_data = stats.boxcox(random_data)# plot both together to comparefig,ax=plt.subplots(1,2)sns.distplot(random_data, ax=ax[0],color="pink")ax[0].set_title("Random Data")sns.distplot(normalized_data[0], ax=ax[1],color="purple")ax[1].set_title("Normalized data")
Tratamento de data
O campo de data é um atributo importante que precisa ser tratado durante a limpeza de dados. Existem vários formatos diferentes nos quais os dados podem ser inseridos no conjunto de dados. Portanto, padronizar a coluna de data é uma tarefa crítica. Algumas pessoas podem ter tratado a data como uma coluna de string, outros como uma coluna DateTime. Quando o conjunto de dados é combinado de fontes diferentes, isso pode criar um problema para análise.
A solução é encontrar primeiro o tipo de coluna de data usando o seguinte comando.
df['Encontro'].tipo d
Se o tipo de coluna for diferente de DateTime, converta-o para DateTime usando o seguinte comando:
import datetimedf['Date_parsed'] = pd.to_datetime(df['Date'], format="%m/%d/%y")
Lidando com problemas de entrada de dados inconsistentes
Há um grande número de entradas inconsistentes que não podem ser encontradas manualmente ou por cálculos diretos. Por exemplo, se a mesma entrada está escrita em maiúsculas ou minúsculas ou uma mistura de maiúsculas e minúsculas. Então, esta entrada deve ser padronizada em toda a coluna.
Uma solução é converter todas as entradas de uma coluna em minúsculas e cortar o espaço extra de cada entrada. Isso pode ser revertido mais tarde, quando a análise for concluída.
# convert to lower casedf['ReginonName'] = df['ReginonName'].str.lower()# remove trailing white spacesdf['ReginonName'] = df['ReginonName'].str.strip()
Outra solução é usar a correspondência difusa para descobrir quais strings na coluna estão mais próximas umas das outras e então substituir todas essas entradas por um determinado limite pela entrada inicial.
Em primeiro lugar, vamos descobrir os nomes únicos das regiões:
region = df['Regionname'].unique()Em seguida, calculamos as pontuações usando correspondência aproximada:
import fuzzywuzzyfromfuzzywuzzy import processregions=fuzzywuzzy.process.extract("WesternVictoria",region,limit=10,scorer=fuzzywuzy.fuzz.token_sort_ratio)

Validando o processo.
Assim que o processo de limpeza de dados for concluído, é importante verificar e validar se as alterações feitas não impediram as restrições colocadas no conjunto de dados.
E finalmente, … Não precisa dizer,
Obrigado pela leitura!
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





