Matriz de confusão: Não tão confuso!
Você já passou por uma situação em que esperava que seu modelo de aprendizado de máquina funcionasse muito bem?, mas retornou baixa precisão? Você fez todo o trabalho duro, então, Onde o modelo de classificação deu errado? Como você pode corrigir isso?
Existem muitas alternativas para medir o desempenho do seu modelo de classificação, mas nenhum resistiu ao teste do tempo como a matriz de confusão. Nos ajuda a examinar como nosso modelo funcionava, onde deu errado e nos oferece um guia para corrigir nosso caminho.

Neste post, vamos explorar como uma matriz de confusão fornece uma visão holística do desempenho do seu modelo. E ao contrário de seu nome, você notará que uma matriz de confusão é um conceito bastante simples, mas poderoso. Então, vamos desvendar o mistério em torno da matriz de confusão!!

Aprendendo as cordas na área de aprendizado de máquina? Esses cursos irão ajudá-lo a seguir seu caminho:
Isso é o que vamos cobrir:
- O que é uma matriz de confusão?
- Verdadeiro positivo
- Verdadeiro negativo
- Falso positivo: erro de tipo 1
- Falso negativo – Erro de digitação 2
- Por que você precisa de uma matriz de confusão?
- Precisão vs recuperação
- Pontuação F1
- Matriz de confusão no Scikit-learn
- Matriz de confusão para classificação de várias classes
O que é uma matriz de confusão?
A pergunta de um milhão de dólares: o que é, depois de tudo, uma matriz de confusão?
Uma matriz de confusão é uma matriz N x N usada para examinar o desempenho de um modelo de classificação., onde N é o número de classes alvo. A matriz compara os valores alvo reais com aqueles previstos pelo modelo de aprendizado de máquina. Isso nos dá uma visão holística do desempenho do nosso modelo de classificação e dos tipos de erros que ele está cometendo..
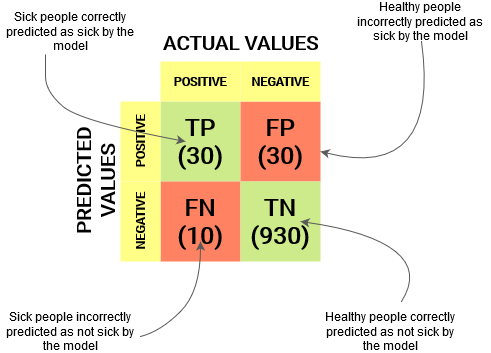
Para um obstáculo de classificação binária, teríamos uma matriz de 2 x 2 como mostrado abaixo com 4 valores:
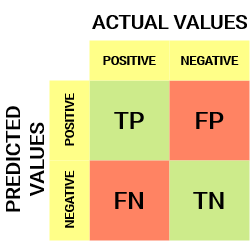
Vamos decifrar a matriz:
- o variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... tem dois valores: Positivo o Negativo
- a colunas representar o valores atuais da variável alvo
- a filas representar o valores preditos da variável alvo
Mas espera, O que é tp, FP, FN e TN aqui? Essa é a parte crucial de uma matriz de confusão.. Vamos entender cada termo abaixo.
Entenda o verdadeiro positivo, o verdadeiro negativo, o falso positivo e o falso negativo em uma matriz de confusão
Verdadeiro positivo (TP)
- O valor previsto corresponde ao valor real
- O valor verdadeiro era positivo e o modelo previu um valor positivo.
Verdadeiro negativo (TN)
- O valor previsto corresponde ao valor real
- O valor verdadeiro era negativo e o modelo previu um valor negativo.
Falso positivo (FP): erro de tipo 1
- O valor previsto foi falsamente previsto
- O valor real era negativo, mas o modelo previu um valor positivo
- Também conhecido como Erro de digitação 1
Falso negativo (FN): erro de tipo 2
- O valor previsto foi falsamente previsto
- O valor real era positivo, mas o modelo previu um valor negativo
- Também conhecido como Erro de digitação 2
Deixe-me dar um exemplo para conhecer melhor isso. Suponha que temos um conjunto de dados de classificação com 1000 Os pontos de dados. Colocamos um classificador nele e obtemos a próxima matriz de confusão:
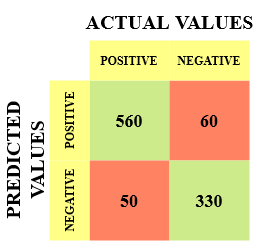
Os diferentes valores da matriz de confusão seriam os seguintes:
- Verdadeiro positivo (TP) = 560; o que significa que 560 pontos de dados de classe positivos foram classificados corretamente pelo modelo
- Verdadeiro negativo (TN) = 330; o que significa que 330 os pontos de dados negativos da classe foram classificados corretamente pelo modelo
- Falso positivo (FP) = 60; o que significa que o modelo classificado incorretamente 60 pontos de dados da classe negativa como pertencentes à classe positiva
- Falso negativo (FN) = 50; o que significa que o modelo classificado incorretamente 50 pontos de dados da classe positiva como pertencentes à classe negativa
Este acabou sendo um classificador bastante decente para nosso conjunto de dados, considerando o número relativamente maior de valores positivos e negativos verdadeiros..
Lembre-se de erros de tipo 1 e tipo 2. Os entrevistadores adoram perguntar a diferença entre esses dois!! Você pode se preparar melhor para tudo isso em nosso Curso Online de Aprendizado de Máquina
Por que precisamos de uma matriz de confusão?
Antes de responder a esta pergunta, Vamos pensar em um obstáculo de classificação hipotético.
Suponha que você queira prever quantas pessoas estão infectadas com um vírus contagioso antes de mostrarem os sintomas e isolá-las da população saudável. (Algo ainda soa? 😷). Os dois valores da nossa variável de destino seriam: Doente e Não Doente.
Agora, você deve se perguntar: Por que precisamos de uma matriz de confusão quando temos nosso amigo para todos os climas: precisão? Nós vamos, vamos ver onde a precisão falha.
Nosso conjunto de dados é um exemplo de conjunto de dados desequilibrado. Existem 947 pontos de dados para a classe negativa e 3 pontos de dados para a classe positiva. É assim que vamos calcular a precisão: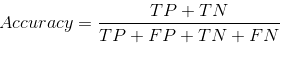
Vamos ver como nosso modelo funcionou:
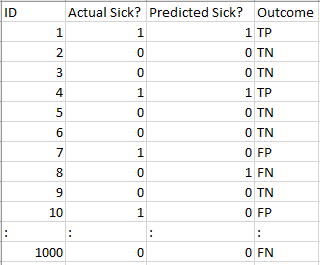
Os valores totais dos resultados são:
TP = 30, TN = 930, FP = 30, FN = 10
Então, a precisão do nosso modelo acaba sendo:
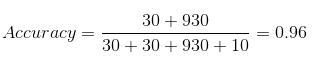
96%! Nada mal!
Mas você está dando uma ideia errada sobre o resultado. Pense nisso.
Nosso modelo diz “Eu posso prever pessoas doentes o 96% do tempo”. Apesar disto, está fazendo o oposto. Você está prevendo pessoas que não ficarão doentes com um 96% precisão enquanto os doentes espalham o vírus!
Você acha que esta é uma métrica correta para o nosso modelo, dada a gravidade do problema? Não deveríamos medir quantos casos positivos podemos prever corretamente para impedir a propagação do vírus contagioso?? Ou talvez, de casos previstos corretamente, Quantos são casos positivos para verificar a confiabilidade do nosso modelo?
É aqui que encontramos o conceito duplo de Precisão e Recuperação..
Precisão vs. recuperação
A precisão nos diz quantos dos casos previstos corretamente foram verdadeiramente positivos.
A seguir, explica como calcular a precisão:
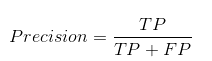
Isso determinaria se nosso modelo é confiável ou não..
A recordação nos diz quantos dos casos positivos reais fomos capazes de prever corretamente com nosso modelo.
E é assim que podemos calcular o recall:
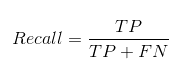
Podemos calcular facilmente a precisão e a recuperação do nosso modelo, inserindo os valores nas questões acima:
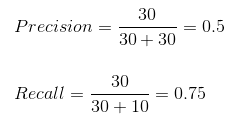
o 50% dos casos previstos corretamente acabaram sendo casos positivos. Enquanto nosso modelo previu com sucesso o 75% dos positivos. Impressionante!
A precisão é uma métrica útil nos casos em que falsos positivos são uma preocupação maior do que falsos negativos.
A precisão é essencial em sistemas de recomendação de música ou vídeo, sites de comércio eletrônico, etc. Resultados incorretos podem levar à perda de clientes e ser prejudiciais para a empresa.
A recuperação é uma métrica útil nos casos em que o falso negativo supera o falso positivo.
A recuperação é essencial em casos médicos em que não importa se disparamos um alarme falso, Mas os casos realmente positivos não devem passar despercebidos!!
Em nosso exemplo, O recall seria uma medida melhor, porque não queremos descarregar acidentalmente uma pessoa infectada e deixá-la se misturar com a população saudável, espalhando assim o vírus contagioso.. Agora você pode entender por que a precisão era uma métrica ruim para nosso modelo.
Mas haverá casos em que não haverá uma distinção clara entre se a precisão é mais importante ou se a recuperação. O que devemos fazer nesses casos? Nós os combinamos!
Pontuação F1
Na prática, quando tentamos aumentar a precisão do nosso modelo, a recuperação diminui e vice-versa. A pontuação F1 captura ambas as tendências em um único valor:
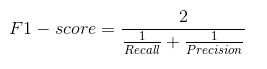
A pontuação F1 é uma média harmônica de precisão e recall, então dá uma ideia combinada sobre essas duas métricas. É máximo quando a precisão é igual a recuperação.
Mas há um problema aqui. A interpretabilidade da pontuação F1 é pobre. Isso significa que não sabemos o que está maximizando nosso classificador: Precisão ou lembre-se? Então, nós o usamos em combinação com outras métricas de avaliação que nos dão uma imagem completa do resultado.
Matriz de confusão usando scikit-learn em Python
Voce ja conhece a teoria, agora vamos colocar em prática. Vamos codificar uma matriz de confusão com a biblioteca Scikit-learn (Claro) e Python.

Sklearn tem duas grandes funções: matriz de confusão() e classificação_report ().
- Sklearn matriz de confusão() retorna os valores da matriz de confusão. Apesar disto, o resultado é ligeiramente diferente do que estudamos até agora. Considere as linhas como valores reais e as colunas como valores previstos. O resto do conceito permanece o mesmo.
- Sklearn classificação_report () gera precisão, recuperação e pontuação f1 para cada classe-alvo. Ao mesmo tempo disso, também tem alguns valores extras: micro média, macro média, e média ponderada
Mirco Average é a precisão / Recuperação / pontuação f1 calculada para todas as classes.
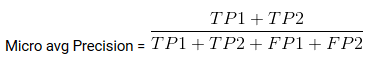
Macro media é a precisão média / Eu lembro / pontuação f1.
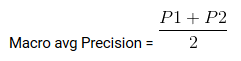
Peso médio é apenas a média ponderada de precisão / Recuperação / pontuação f1.
Matriz de confusão para classificação de várias classes
Como uma matriz de confusão funcionaria para um obstáculo de classificação de várias classes?? Nós vamos, Não coça a cabeça! Vamos dar uma olhada nisso aqui..
Vamos desenhar uma matriz de confusão para um obstáculo multiclasse onde temos que prever se uma pessoa ama o Facebook, Instagram o Snapchat. A matriz de confusão seria uma matriz de 3 x 3 como esta:
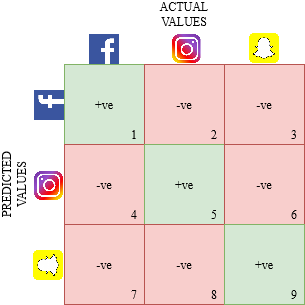
O verdadeiro positivo, verdadeiro negativo, Os falsos positivos e os falsos negativos de cada classe seriam calculados somando os valores das células da seguinte forma:
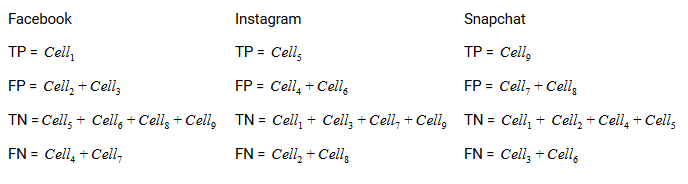
Isso é tudo! Você está pronto para decifrar qualquer matriz de confusão N x N!!
Notas finais
E de repente, a matriz de confusão não é mais tão confusa! Esta postagem deve fornecer uma base sólida sobre como interpretar e usar uma matriz de confusão para algoritmos de classificação em aprendizado de máquina..
Em breve publicaremos um post sobre a curva AUC-ROC e continuaremos nossa discussão lá. Até a próxima, não perca a esperança em seu modelo de classificação, Você pode estar usando a métrica de avaliação errada!





