Este artigo foi publicado como parte do Data Science Blogathon.
Introdução
E nós aprendemos ao longo do caminho.
As empresas, de forma similar, aplicar seu aprendizado anterior à tomada de decisões relacionadas a operações e novas iniciativas, por exemplo, relacionado à classificação do cliente, produtos, etc. Porém, aqui fica um pouco mais complexo, pois existem várias partes interessadas envolvidas. O que mais, as decisões devem ser precisas devido ao seu impacto mais amplo.
Com a evolução da tecnologia digital, humanos desenvolveram múltiplos ativos; máquinas são uma delas. Temos aprendido (e nós continuamos) usar máquinas para analisar dados usando estatísticas para gerar informações úteis para auxiliar na tomada de decisões e previsões.
Máquinas não fazem mágica com dados, eles aplicam estatísticas simples.
Neste contexto, Vamos revisar alguns algoritmos de aprendizado de máquina comumente usados para classificação e tentar entender como eles funcionam e se comparam entre si. Mas primeiro, vamos entender alguns conceitos relacionados.
Conceitos básicos
o aprendizagem supervisionadaO aprendizado supervisionado é uma abordagem de aprendizado de máquina em que um modelo é treinado usando um conjunto de dados rotulados. Cada entrada no conjunto de dados está associada a uma saída conhecida, permitindo que o modelo aprenda a prever resultados para novas entradas. Este método é amplamente utilizado em aplicações como classificação de imagens, Reconhecimento de fala e previsão de tendências, destacando sua importância em... se define como la categoría de análisis de datos donde el resultado objetivo es conocido o etiquetado, por exemplo, se o cliente ou clientes compraram um produto ou não. Porém, quando a intenção é agrupá-los com base no que todos compraram, então se torna não supervisionado. Isso pode ser feito para explorar a relação entre os clientes e o que eles compram.
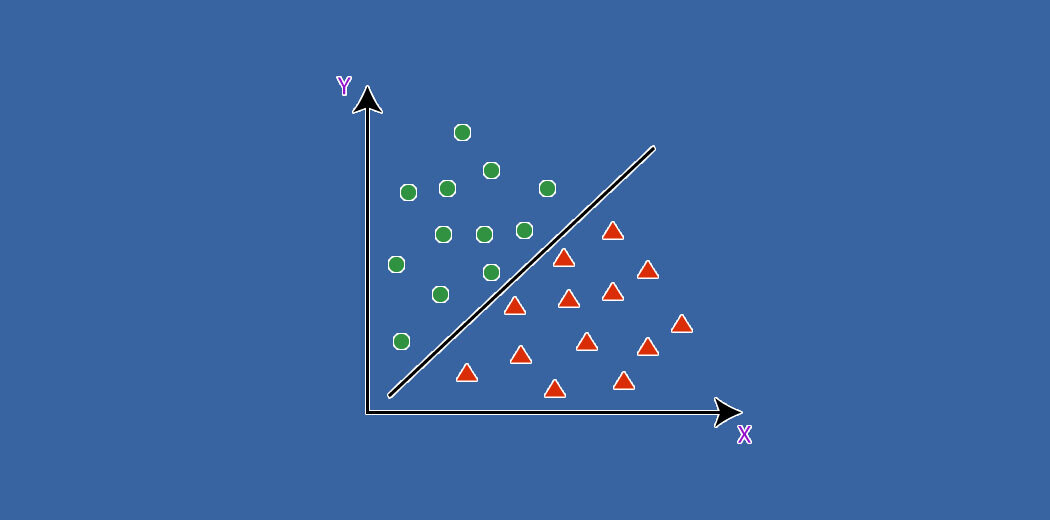
Tanto a classificação quanto a regressão pertencem à aprendizagem supervisionada, mas o primeiro se aplica quando o resultado é finito, enquanto o último é para infinitos valores de resultados possíveis (por exemplo, prever o valor em dólares da compra).
La distribución normal es la conocida distribución en forma de campana de una variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... contínuo. Esta é uma extensão natural dos valores que um parâmetro normalmente assume.
Uma vez que os preditores podem ter diferentes intervalos de valores, por exemplo, peso humano pode ser de até 150 (kg), mas a altura típica é apenas até 6 (tortas); valores precisam de escala (em torno da respectiva média) para torná-los comparáveis.
Colinearidade é quando dois ou mais preditores estão relacionados, quer dizer, seus valores se movem juntos.
Outliers são valores excepcionais de um preditor, Pode ser verdade ou não.
Regressão logística
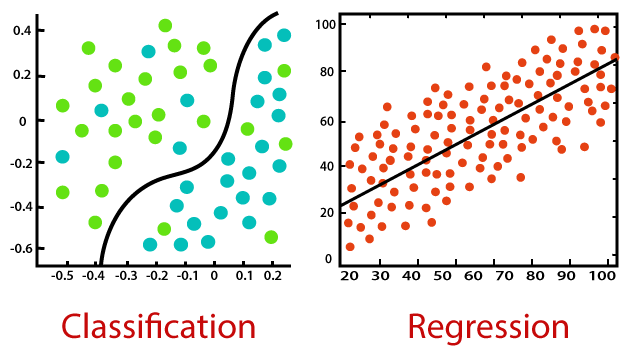
A regressão logística usa o poder da regressão para realizar a classificação e tem feito isso muito bem por várias décadas., para ficar entre os modelos mais populares. Um dos principais motivos do sucesso do modelo é seu poder de explicabilidade, quer dizer, apontar a contribuição de preditores individuais, quantitativamente.
Ao contrário da regressão que usa mínimos quadrados, o modelo usa a probabilidade máxima para ajustar uma curva sigmóide na distribuição da variável alvo.
Dada a suscetibilidade do modelo à multicolinearidade, aplicá-lo passo a passo acaba sendo uma abordagem melhor para finalizar os preditores escolhidos do modelo.
O algoritmo é uma escolha popular em muitas tarefas de processamento de linguagem natural, por exemplo, detecção de fala tóxica, classificação de tópicos, etc.
Redes neurais artificiais
Redes neurais artificiais (ANN), assim chamados porque tentam imitar o cérebro humano, são adequados para conjuntos de dados grandes e complexos. Sua estrutura é composta por camadas de nós intermediários (semelhantes aos neurônios) que são mapeados juntos para as várias entradas e a saída de destino.
É um algoritmo de autoaprendizagem, uma vez que começa com um mapeamento inicial (aleatória) e, a partir de então, Iterativamente, sintoniza automaticamente os pesos relacionados para fazer o ajuste fino da saída desejada para todos os registros. Las múltiples capas brindan una capacidad de aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde... para poder extraer características de nivel superior de los datos sin procesar.
O algoritmo fornece alta precisão de previsão, mas é necessário dimensionar características numéricas. Tem amplas aplicações em campos futuros, incluindo visão computacional, PNL, reconhecimento de voz, etc.

Floresta aleatória
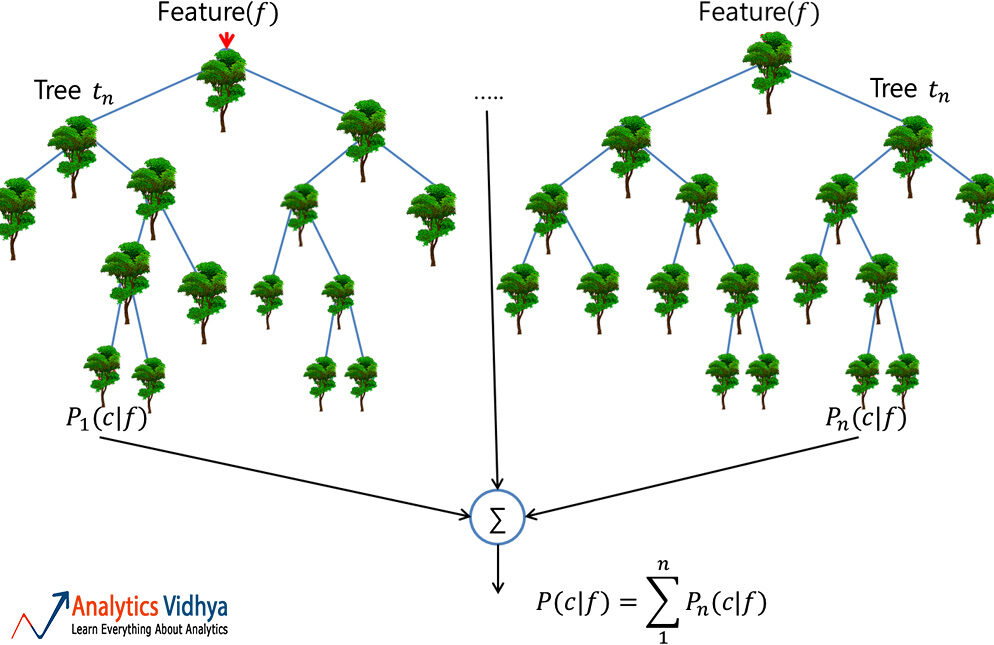
Uma floresta aleatória é um conjunto confiável de múltiplas árvores de decisão (o CART); embora mais populares para classificação do que aplicativos de regressão. Aqui, árvores individuais são construídas por ensacamento (quer dizer, agregação de bootstraps que nada mais são do que conjuntos de dados de fluxo múltiplos criados por amostragem de registro com substituição) e dividir usando menos recursos. A floresta diversa resultante de árvores não correlacionadas exibe variação reduzida; portanto, é mais robusto para mudanças de dados e move sua precisão de previsão para novos dados.
Porém, o algoritmo não funciona bem para conjuntos de dados com muitos outliers, algo que precisa ser resolvido antes de construir o modelo.
Possui ampla aplicação nas áreas financeiras, varejista, aeronáutica e muitos outros.
Bayes ingenuo
Embora possamos não perceber isso, Este é o algoritmo mais comumente usado para filtrar e-mails de spam!!
Aplique o que é conhecido como probabilidade posterior usando o Teorema de Bayes para categorizar dados não estruturados. E ao fazer isso, ingenuamente assume que os preditores são independentes, o que pode não ser verdade.
El modelo funciona bien con un pequeño conjunto de datos de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina...., desde que todas as classes do preditor categórico estejam presentes.
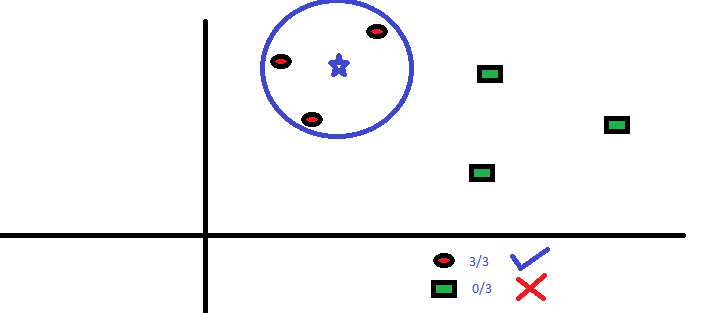
KNN
O algoritmo vizinho K-Nemost (KNN) prevê com base no número especificado (k) dos pontos de dados vizinhos mais próximos. Aqui, o pré-processamento de dados é significativo, pois afeta diretamente as medições de distância. Diferente de outros, o modelo não tem fórmula matemática, nem habilidade descritiva.
Aqui, o parâmetro 'k’ deve ser escolhido sabiamente; uma vez que um valor inferior ao ideal leva a um viés, enquanto um valor mais alto afeta a precisão da previsão.
É um modelo simples e bastante preciso, preferido principalmente para conjuntos de dados menores, devido aos enormes cálculos envolvidos em preditores contínuos.
Em um nível simples, KNN pode ser usado em um ambiente preditivo bivariado, por exemplo, altura e peso, para determinar o sexo dado uma amostra.
Juntando tudo
O desempenho de um modelo depende principalmente da natureza dos dados. Uma vez que os conjuntos de dados de negócios têm vários preditores e são complexos, é difícil identificar um algoritmo que sempre funciona bem. Portanto, a prática usual é tentar vários modelos e encontrar o certo.
Como uma comparação de alto nível, los aspectos más destacados que se encuentran generalmente para cada uno de los algoritmos anteriores se anotan a continuación en algunos parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... comunes; para servir como um instantâneo de referência rápida.
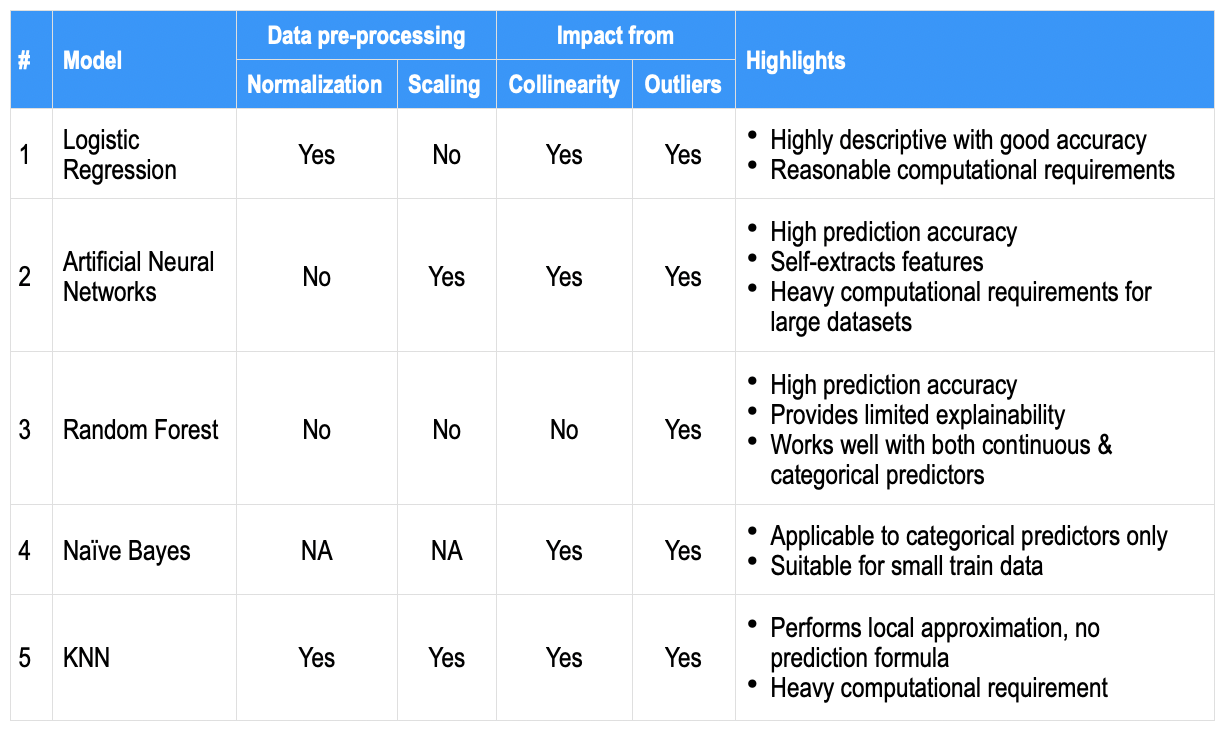
O que mais, existem múltiplas alavancas, por exemplo, balanceamento de dados, imputação, validação cruzada, definido entre algoritmos, maior conjunto de dados de trem, etc. mais ajuste de hiperparâmetro de modelo, que pode ser usado para obter precisão. Embora a precisão da previsão possa ser a mais desejável, as empresas também procuram preditores proeminentes que contribuem (quer dizer, um modelo descritivo ou sua explicabilidade resultante).
Finalmente, o aprendizado de máquina permite que os humanos decidam quantitativamente, prever e olhar além do óbvio, embora às vezes também em aspectos previamente desconhecidos.





