Introdução
Python é uma das línguas mais amadas no mundo da ciência de dados e aprendizado de máquina. É fácil de aprender e fornece um monte de bibliotecas e pacotes e tem uma boa comunidade de desenvolvedores. Bibliotecas e pacotes Python são um grupo de módulos que facilita nossas vidas. Há mais de 137,000 Bibliotecas Python e 198,826 Pacotes Python preparados para facilitar a experiência de programação comum dos engenheiros. Essas bibliotecas e pacotes estão planejados para uma variedade de correções avançadas.
Como um entusiasta da ciência de dados, Já vi pessoas que sempre falam sobre algumas bibliotecas famosas, como pandas de manipulação de dados e NumPy, para visualização de dados matplotlib, nascido do mar, plotly e muitos mais, para modelar scikit-learn, TensorFlow, etc. Neste artigo eu não vou cobrir essas bibliotecas porque já existem toneladas de blogs disponíveis, ver meu artigo sobre as bibliotecas Python mais usadas aqui. Mas em seu artigo, Vou cobrir algumas joias escondidas de bibliotecas Python que são desconhecidas do mundo da ciência de dados. Aqui estão algumas bibliotecas importantes que você pode verificar em 2021.

Essas bibliotecas incluem funcionalidades como lidar com valores perdidos de forma organizada, lidar emojis, converter números em ints e carros alegóricos, ferramentas de inteligência de visualização, modelagem série temporal e muito mais. Abrange uma ampla gama de tópicos, do processamento de linguagem natural à visualização de dados e séries tempormais. Então vamos começar.
Tabela de conteúdo
- Missingo
- Emot
- Bambulib
- ppscore
- AutoViz
- Numerador
- PyFlux
- Texto flash
Missingo
Os conjuntos de dados do mundo real geralmente contêm muitos valores ausentes e nulos. Isso pode ser devido a uma série de razões, como vazamento de dados, dados não estão disponíveis, etc. As vezes, é muito irritante para lidar com este tipo de dados confusos. Esses dados confusos exigem atenção especial antes de serem alimentados em algoritmos de aprendizado de máquina., uma vez que esses algoritmos não lidam com os valores perdidos.
Precisamos de uma abordagem melhor para gerenciar esses valores perdidos. Aí vem a magia da biblioteca Python chamada ausente. Isso nos ajuda a tou lidar com valores perdidos com a ajuda de visualizações de dados de uma maneira muito melhor. Isso é baseado em matplotlib. A partir de abril 2021, tem quatro tipos de gráficos para entender a distribuição de dados perdidos, a saber, a gráfico de barrasO gráfico de barras é uma representação visual de dados que usa barras retangulares para mostrar comparações entre diferentes categorias. Cada barra representa um valor e seu comprimento é proporcional a ele. Esse tipo de gráfico é útil para visualizar e analisar tendências, facilitar a interpretação de informações quantitativas. É amplamente utilizado em várias disciplinas, como estatísticas, Marketing e pesquisa, devido à sua simplicidade e eficácia..... mapa de caloruma "mapa de calor" é uma representação gráfica que usa cores para mostrar a densidade de dados em uma área específica. Comumente usado em análise de dados, Estudos de marketing e comportamentais, Esse tipo de visualização permite identificar padrões e tendências rapidamente. Através de variações cromáticas, Os mapas de calor facilitam a interpretação de grandes volumes de informações, ajudando a tomar decisões informadas...., matriz e dendrograma. Então vamos começar.
Instalação
pip instalar missingo
Importando a biblioteca
importação missingo como msns
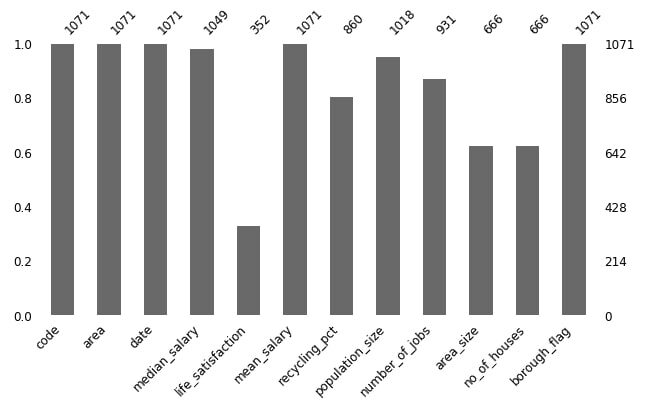
No gráfico de barras abaixo, você pode ver o número de valores perdidos em cada coluna:
Para mais informacao, consulte a documentação oficial: Ligação
Emot
Emojis são muito comuns em bate-papos. Quando se trata de tarefas de processamento de linguagem natural, é muito tedioso para lidar com emojis. Aqui vem uma biblioteca muito útil para se livrar de emoticons de dados de texto. É uma famosa biblioteca Python que é muito útil quando temos que lidar com Emoji e Emoticons. Funciona bem com Python 2 e Python 3. Pega uma sequência como entrada e retorna uma lista de dicionários. Então vamos começar.
Instalação
pip instalar emot
Importando a biblioteca
importação emot
Código
import emot
text = "Eu amo píton 👨 :-)"
emot.emoji(texto)
[{'valor': '👨', 'quer dizer': ':homem:', 'localização': [14, 14], 'bandeira': Verdade}]
emot.emoticons(texto)
{'valor': [':-)'], 'localização': [[16, 19]], 'quer dizer': ['Rosto feliz sorridente'], 'bandeira': Verdade}

Para mais informacao, consulte a documentação oficial: Ligação
Bambulib
Analisar e visualizar informações é a interação mais significativa e demorada. Precisamos gastar muito tempo pesquisando inequivocamente qual é o problema aqui e o que você está tentando dizer.. Usamos vários tipos de bibliotecas Python para visualizar os exemplos e esquisitices no conjunto de dados para ficar confortável com o conjunto de dados..
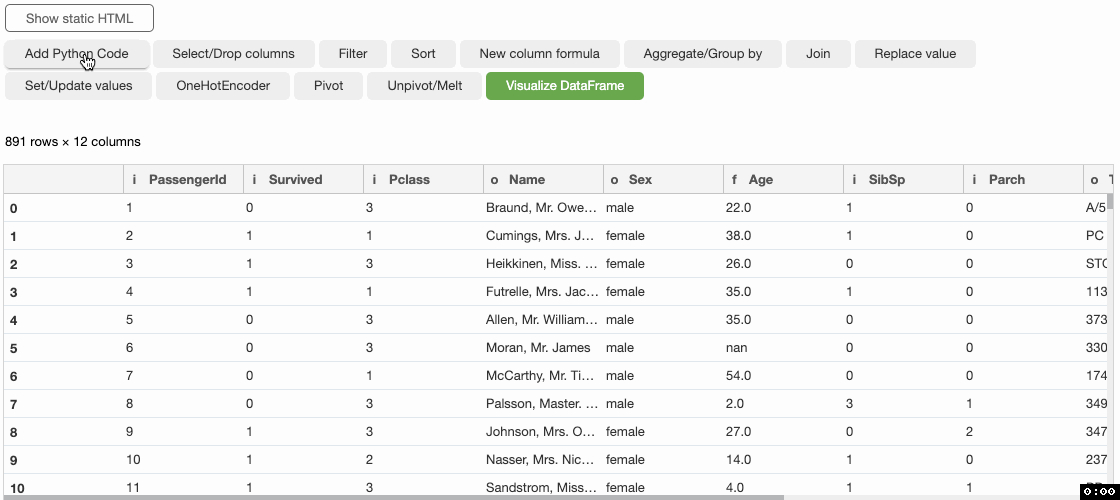
Bamboolib é GUI para pandas de dataframe que permite que qualquer pessoa trabalhe com python em Jupyter Notebook ou JupyterLab. Bamboolib é uma biblioteca profundamente inteligente e amplamente apoiada para examinar, imaginar e controlar informações.
De fato, mesmo uma pessoa sem uma base de programação pode usá-la para extrair pedaços de conhecimento de informações., desde nenhuma experiência de codificação necessária. Bamboolib não é de código aberto, o que implica que você deve comprar bamboolib para usá-lo, mas oferece uma forma preliminar gratuita de 14 dias para você investigá-lo completamente e perceber como ele pode ser muito valioso para você.
Instalação
pip instalar bambulib
Importando a biblioteca
importação bamboolib

Para mais informacao, consulte a documentação oficial: Ligação
Ppscore
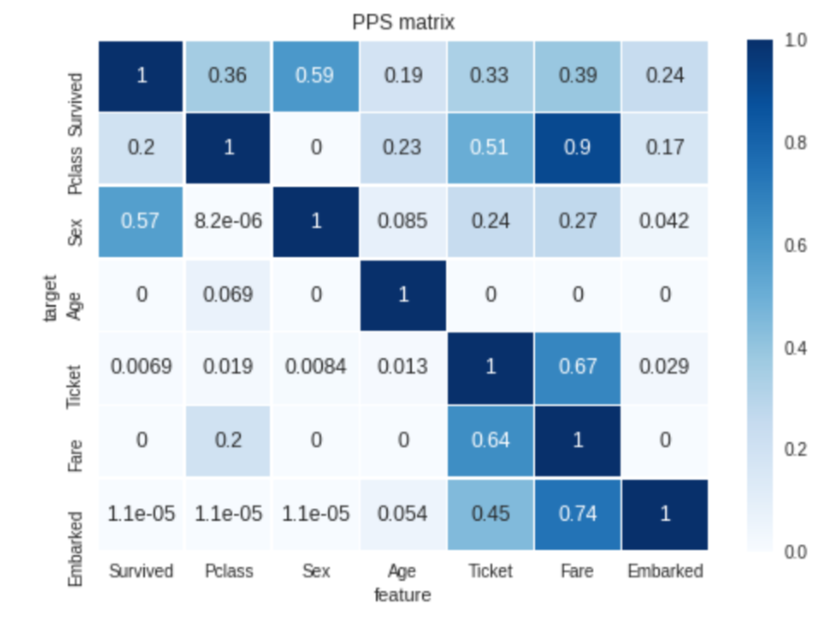
Ppscore completo é Preditivo Power Score. Esta biblioteca Python é feita por desenvolvedores bamboolib. O Score de Potência Preditiva é uma alternativa à matriz de correlação. Esta pontuação é assimétrica e pode detectar relações lineares ou não lineares entre duas colunas em nosso conjunto de dados. Então vamos começar com esta biblioteca..
Instalação
pip instalar ppscore
Importando a biblioteca
importação ppscore
Para mais informacao, consulte a documentação oficial: Ligação
AutoViz
É a biblioteca Python mais subestimada já usada para realizar análise de dados exploratórios. Esta biblioteca exibe automaticamente qualquer tipo de conjunto de dados, incluindo também grandes conjuntos de dados. Bonito Visualizações podem ser desenhadas com um único código.. Você só precisa fornecer seu arquivo de dados (Txt, JSONJSON, o Notação de objeto JavaScript, É um formato leve de troca de dados que é fácil para os humanos lerem e escreverem, e fácil para as máquinas analisarem e gerarem. É comumente usado em aplicativos da web para enviar e receber informações entre um servidor e um cliente. Sua estrutura é baseada em pares de valores-chave, tornando-o versátil e amplamente adotado no desenvolvimento de software.. o CSV) e irá exibi-lo automaticamente. Basta carregar seus dados e o AutoViz fornecerá automaticamente os gráficos certos que ajudarão você a obter insights em questão de segundos. Então vamos começar.

Instalação
pip instalar autoviz
Importando a biblioteca
importação autoviz
Para mais informacao, consulte a documentação oficial: Ligação
Numerador
É um módulo Python muito interessante para processamento de palavras. Isso converte números de linguagem natural em flutuadores e ints. Este é um módulo muito útil em tarefas de processamento de linguagem natural. Para
exemplo, se você converter '42’ sobre 42, 'bilhões e um’ sobre 1000000001
etc. Então vamos começar.
Instalação
pip instalar numerizer
Importando a biblioteca
de numerizer importação numerize
Código
numerize('quarenta e dois')
'42'
numerize('um bilhão e um')
'1000000001'
Para mais informacao, consulte a documentação oficial: Ligação
PyFlux
A pesquisa em séries temporizadas é, sem dúvida, o problema mais experimentado na área de aprendizado de máquina.. PyFlux é uma biblioteca de código aberto em Python que trabalhou inequivocamente para trabalhar com problemas de séries temporâneais. A biblioteca tem um grupo brilhante de modelos de layout em tempo atual que incluem, mas não estão restritos aos modelos ARIMA, GARCH e VAR. Portanto, PyFlux oferece uma forma probabilística de lidar com a visualização da disposição do tempo. Então vamos começar.
Instalação
pip instalar pyflux
Importando a biblioteca
importação pyflux
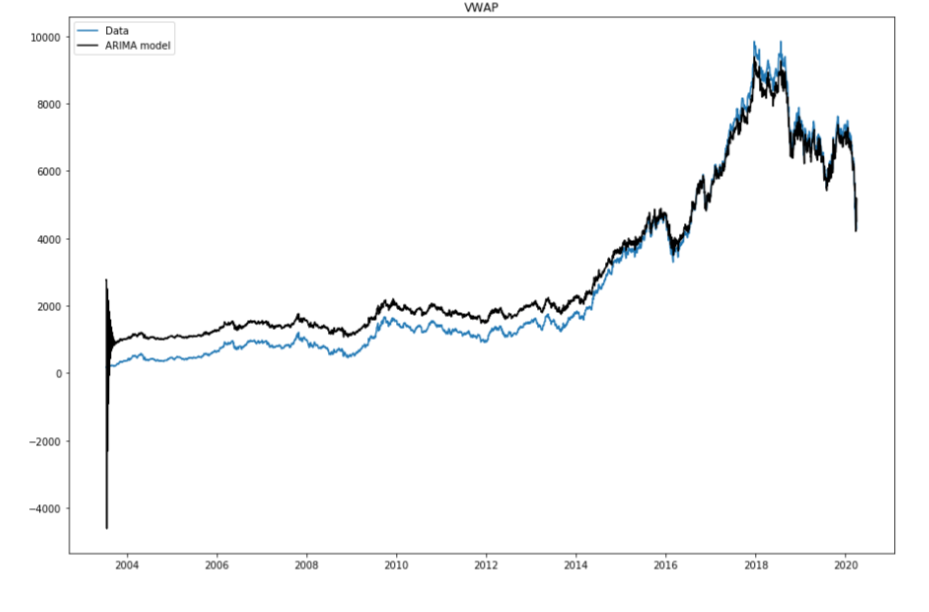
Para mais informacao, consulte a documentação oficial: Ligação
FlashText
FlashText é uma biblioteca Python feita explicitamente pesquisar na substituição de palavras em um registro. Atualmente, o funcionamento do flashtext é que ele requer uma palavra ou um resumo de palavras e uma sequência. as palavras que o flashtext chama palavras-chave são examinadas ou substituídas na sequência.
Vamos ver informações sobre como o FlashText funciona. No momento em que as palavras-chave são passadas para o FlashText para pesquisar ou personificar, são salvos como uma estrutura de dados Trie que é produtiva em mapeamentos de recuperação. Então vamos começar.
Instalação
pip instalar flashtext
Importando a biblioteca
texto flash de importação
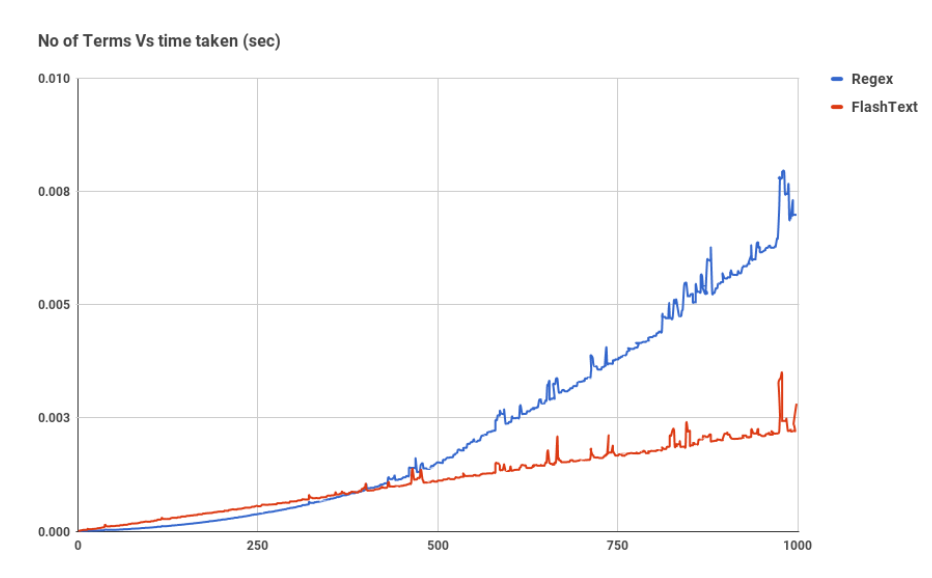
Olhando:
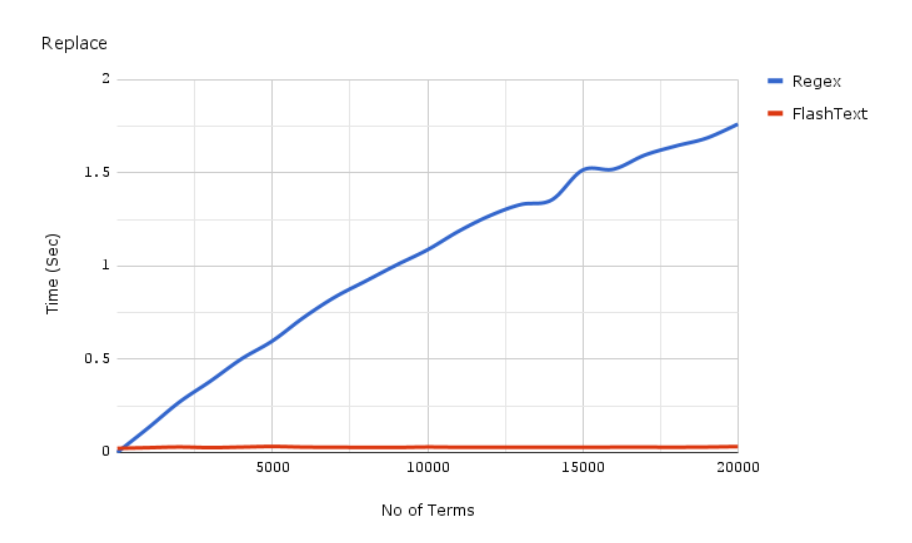
Substituição:
Para mais informacao, consulte a documentação oficial: Ligação
Nota final
Você pode verificar meus artigos aqui: Artigos
Obrigado por ler este artigo e por sua paciência.. Deixe-me na seção de comentários sobre comentários. Compartilhe este artigo, isso me motivará a escrever mais blogs para a comunidade de ciência de dados.
Identificação de e-mail: gakshay1210@ gmail.com
Me siga no LinkedIn: LinkedIn
Os meios de comunicação mostrados neste artigo sobre pacotes Python não são de propriedade do DataPeaker e são usados a critério do autor.





