Introdução
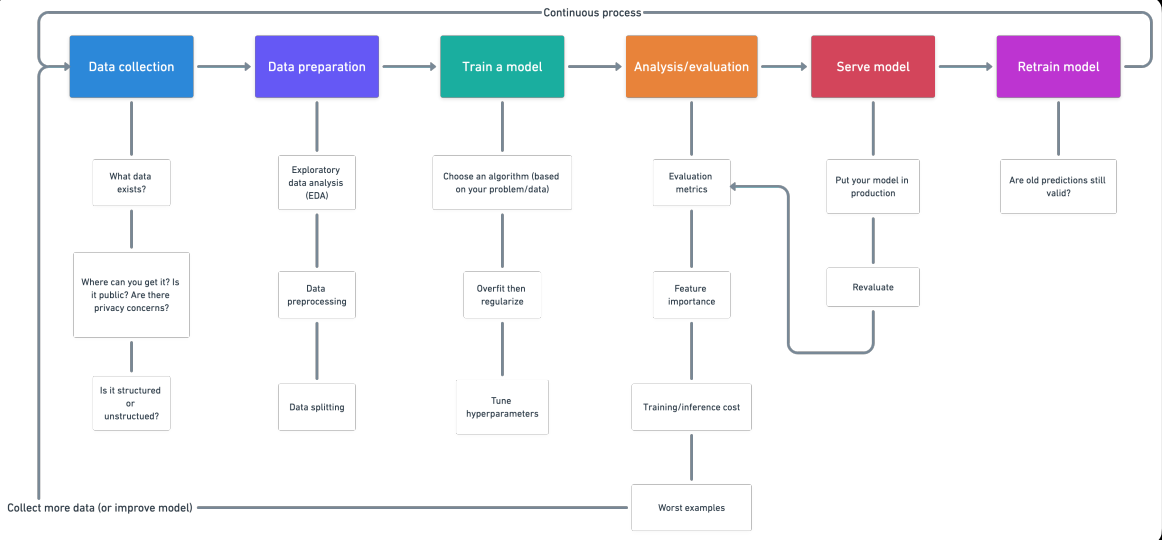
1. Coleta de dados
- ¿Qué tipo de problema estamos tratando de resolver?
- ¿Qué fuentes de datos ya existen?
- ¿Qué problemas de privacidad existen?
- ¿Son públicos los datos?
- ¿Dónde debemos almacenar los archivos?
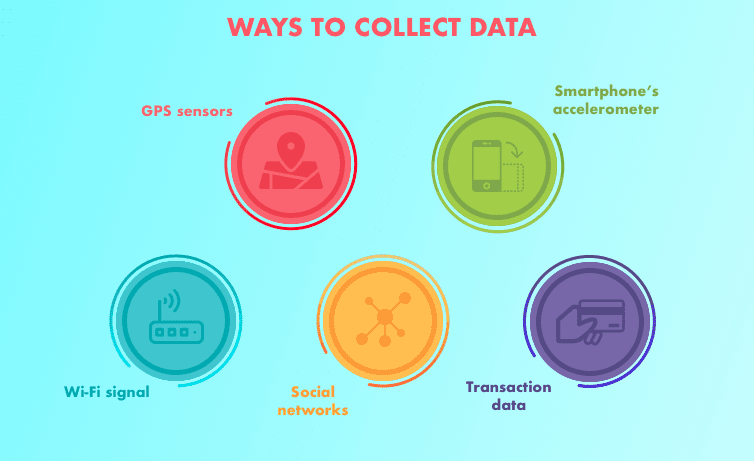
- Dados estruturados: aparecen en formato tabulado (estilo de filas y columnas, como lo que encontraría en una hoja de cálculo de Excel). Contiene diferentes tipos de datos, por exemplo, series de tiempo numéricas, categóricas.
- · Nominal / categórico – Una cosa u otra (mutuamente excluyentes). Por exemplo, para las básculas de automóviles, el color es una categoría. Un automóvil puede ser azul pero no blanco. No importa un pedido.
- Numérico: Cualquier valor continuo donde la diferencia entre ellos importa. Por exemplo, al vender casas, $ 107,850 é mais que $ 56,400.
- Ordinal: Datos que tienen orden pero se desconoce la distancia entre valores. Por exemplo, una pregunta como, ¿cómo calificaría su salud del 1 al 5? 1 siendo pobre, 5 saludable. Puede responder 1, 2, 3, 4, 5, pero la distancia entre cada valor no significa necesariamente que una respuesta de 5 sea cinco veces más buena que una respuesta de 1. Séries TemporaisUma série temporal é um conjunto de dados coletados ou medidos em momentos sucessivos, geralmente em intervalos de tempo regulares. Esse tipo de análise permite identificar padrões, Tendências e ciclos nos dados ao longo do tempo. Sua aplicação é ampla, abrangendo áreas como economia, Meteorologia e saúde pública, facilitando a previsão e a tomada de decisões com base em informações históricas....: datos a lo largo del tiempo. Por exemplo, los valores históricos de venta de las topadoras de 2012 uma 2018.
- Séries Temporais: Datos a lo largo del tiempo. Por exemplo, los valores históricos de venta de las topadoras de 2012 uma 2018.
- Dados não estruturados: Datos sin estructura rígida (imagens, vídeo, voz, Talvez uma analogia melhor seria
texto de idioma)
2. Preparação de dados
- Análise exploratória de dados (EDA), aprender sobre los datos con los que está trabajando
- ¿Cuáles son las variables de características (entrada) e o variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... de destino (Saída)? Por exemplo, para predecir una enfermedad cardíaca, las variables características pueden ser la edad, el peso, la frecuencia cardíaca promedio y el nivel de actividad física de una persona. Y la variable objetivo será si tienen o no una enfermedad.
- ¿Qué tipo de tienes? Series temporales estructuradas, no estructuradas, numéricas. ¿Faltan valores? En caso de que los elimine o los complete, la función de imputación.
- ¿Dónde están los valores atípicos? Cuantos de ellos hay? ¿Por qué están ellos ahí? ¿Hay alguna pregunta que pueda hacerle a un experto en el dominio sobre los datos? Por exemplo, ¿podría un médico especialista en enfermedades cardíacas arrojar algo de luz sobre su conjunto de datos de enfermedades cardíacas?
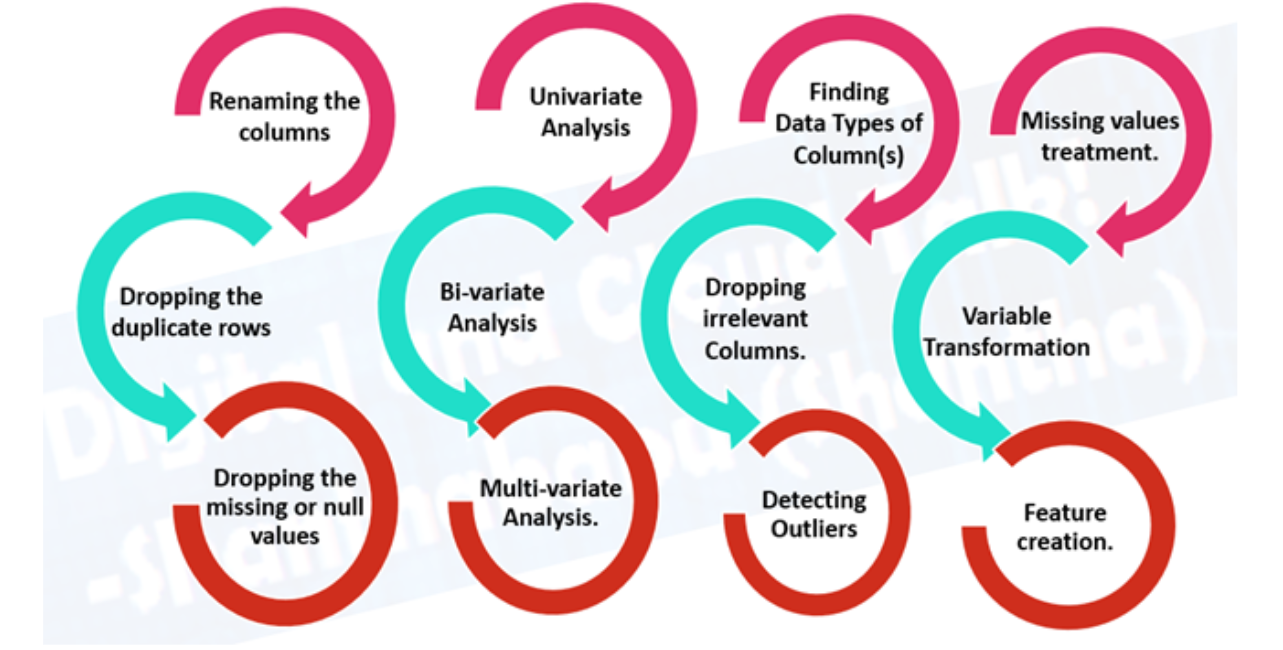
- Pré-processamento de dados, preparación de sus datos para modelarlos.
- Función de imputación: completar los valores faltantes (un modelo de aprendizaje automático no puede aprender
en datos que no están ahí)
- Imputación única: Llenar con media, una mediana de la columna.
- Múltiples imputaciones: Modele otros valores perdidos y con lo que encuentre su modelo.
- KNN (k vecinos más cercanos): Complete los datos con un valor de otro ejemplo que sea similar.
- Muchos más, como la imputación aleatoria, la última observación llevada adelante (para series de tiempo), la ventana móvil y las más frecuentes.
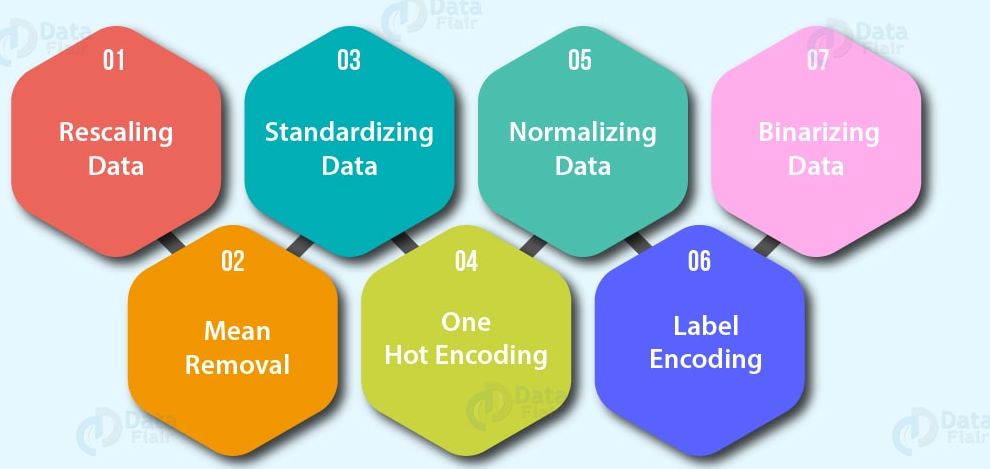
- Codificación de funciones (convertir valores en números). Un modelo de aprendizaje automático
requiere que todos los valores sean numéricos)
- Uma codificação quente: Convierta todos los valores únicos en listas de ceros y unos donde el valor objetivo es 1 y el resto son ceros. Por exemplo, cuando un automóvil colorea verde, vermelho, azul, verde, el futuro del color del automóvil se representaría como [1, 0, e 0] y una roja seria [0, 1, e 0].
- Codificador de etiquetas: Convierta las etiquetas en valores numéricos distintos. Por exemplo, si sus variables objetivo son animales diferentes, como perro, gato, pájaro, estos podrían convertirse en 0, 1 e 2, respectivamente.
- Codificación de incrustación: Aprenda una representación entre todos los diferentes puntos de datos. Por exemplo, un modelo de lenguaje es una representación de cómo diferentes palabras se relacionan entre sí. La incrustación también está cada vez más disponible para datos estructurados (tabulares).
- NormalizaçãoA padronização é um processo fundamental em várias disciplinas, que busca estabelecer padrões e critérios uniformes para melhorar a qualidade e a eficiência. Em contextos como engenharia, Educação e administração, A padronização facilita a comparação, Interoperabilidade e compreensão mútua. Ao implementar normas, a coesão é promovida e os recursos são otimizados, que contribui para o desenvolvimento sustentável e a melhoria contínua dos processos.... de funciones (escalado) o estandarización: Cuando las variables numéricas están en diferentes escalas (por exemplo, el número_de_bathroom está entre 1 e 5 y el tamaño_of_land entre 500 e 20000 pés quadrados), algunos algoritmos de aprendizaje automático no funcionan muy bien. El escalado y la estandarización ayudan a solucionar este problema.
- Engenharia de funções: transformar los datos en una representación (potencialmente) más significativa al agregar conocimiento del dominio
- Descomponer
- Discretização: convertir grupos grandes en grupos más pequeños
- Funciones de cruce e interacción: combinación de dos o más funciones
- Las características del indicador: usar otras partes de los datos para indicar algo potencialmente significativo
- Seleção de recursos: seleccionando
las características más valiosas de su conjunto de datos para modelar. Potencialmente reduciendo el tiempo de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... y sobreajuste (menos datos generales y menos datos redundantes para entrenar) y mejorando la precisión.
- Redução de dimensionalidade: Un método común de reducción de dimensionalidad, PCA o análisis de componentes principales toma una gran cantidad de dimensiones (caracteristicas) y usa álgebra lineal para reducirlas a menos dimensiones. Por exemplo, supongamos que tiene 10 funciones numéricas, podría ejecutar PCA para reducirlo a 3.
- Importancia de la función (modelado posterior): Ajuste un modelo a un conjunto de datos, luego inspeccione qué características fueron más importantes para los resultados, elimine las menos importantes.
- Métodos de envoltura como los algoritmos genéticos y la eliminación de características recursivas implican crear grandes subconjuntos de opciones de características y luego eliminar las que no importan.
- Hacer frente a los desequilibrios: ¿Sus datos tienen 10,000 ejemplos de una clase pero solo 100 ejemplos de otra?
- Recopile más datos (si puede)
- Utilice el paquete scikit-learn-contrib imbalanced- aprender
- Utilice SMOTE: técnica sintética de sobremuestreo de minorías. Crea muestras sintéticas de tu clase menor para intentar nivelar el campo de juego.
- Un artículo útil para mirar es “Aprendiendo de los datos desequilibrados”.
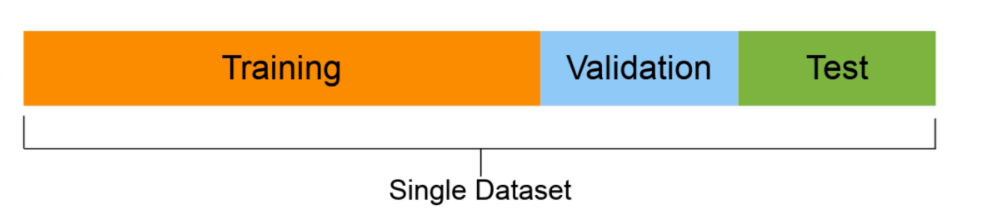
- Conjunto de entrenamiento (geralmente 70-80% dos dados): el modelo aprende sobre esto.
- Conjunto de validación (normalmente del 10 al 15% dos dados): los hiperparámetros del modelo se ajustan a este
- Conjunto de prueba (normalmente entre el 10% e ele 15% dos dados): el rendimiento final de los modelos se evalúa sobre esta base. Si lo ha hecho bien, es de esperar que los resultados del conjunto de prueba den una buena indicación de cómo debería funcionar el modelo en el mundo real. No utilice este conjunto de datos para ajustar el modelo.
3. Entrene el modelo sobre los datos (3 Passos: elija un algoritmo, ajustar o modelo, reduzca el ajuste con regularizaçãoA regularização é um processo administrativo que busca formalizar a situação de pessoas ou entidades que atuam fora do marco legal. Esse procedimento é essencial para garantir direitos e deveres, bem como promover a inclusão social e econômica. Em muitos países, A regularização é aplicada em contextos migratórios, Trabalhista e Tributário, permitindo que aqueles que estão em situação irregular tenham acesso a benefícios e se protejam de possíveis sanções....)
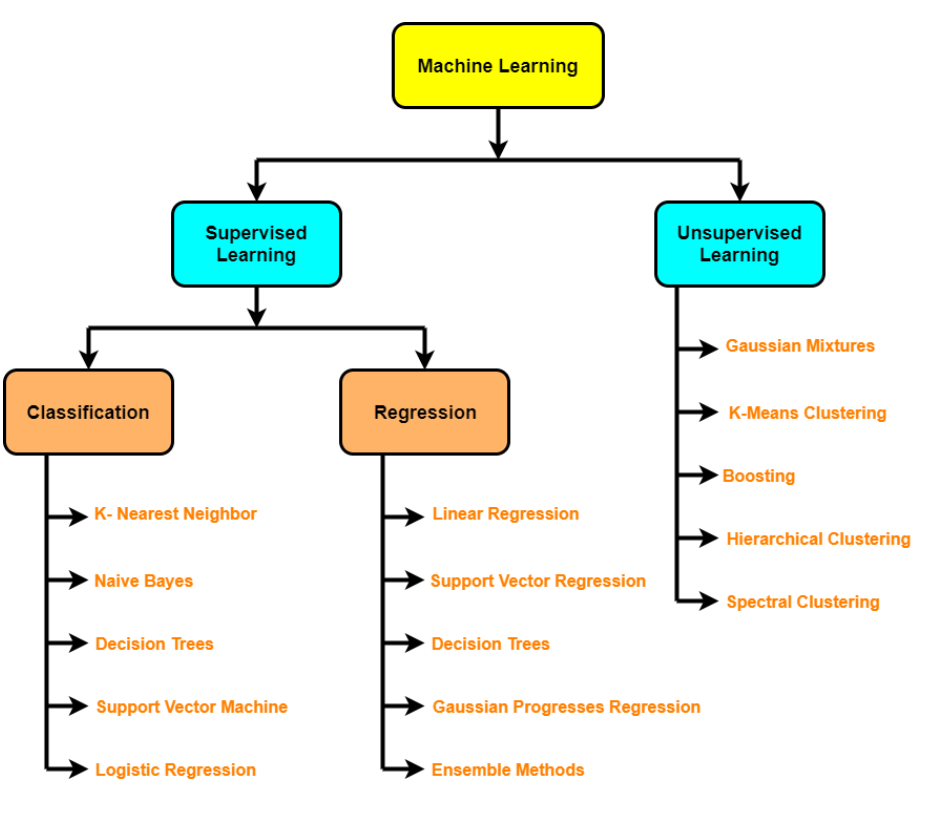
- Algoritmos supervisados: regressão linear, Regressão logística, KNN, SVM, árbol de decisiones y bosques aleatorios, AdaBoost / Gradient Boosting Machine (impulso)
- Algoritmos no supervisados: agrupamentoo "agrupamento" É um conceito que se refere à organização de elementos ou indivíduos em grupos com características ou objetivos comuns. Este processo é usado em várias disciplinas, incluindo psicologia, Educação e biologia, para facilitar a análise e compreensão de comportamentos ou fenômenos. No campo educacional, por exemplo, O agrupamento pode melhorar a interação e o aprendizado entre os alunos, incentivando o trabalho.., redução de dimensionalidade (PCA, O desempenho é exibido como gráficos de dispersão e caixa, t-SNE), detecção de anomalia
- Aprendizaje por lotes
- Aprender en línea
- Aprendizagem de transferência
- Aprendizaje activo
- conjunto
- Desajuste – ocurre cuando su modelo no funciona tan bien como le gustaría en sus datos. Intente entrenar para un modelo más largo o más avanzado.
- Sobreajuste– ocurre cuando la pérdida de validación comienza a aumentar o cuando el modelo funciona mejor en el conjunto de entrenamiento que en el de prueba.
- Regularização: una colección de tecnologías para prevenir / reducir el sobreajuste (por exemplo, L1, L2, Abandono, Parada anticipada, Aumento de dados, Normalización de lotes)
- Ajuste de hiperparâmetros – Ejecute un montón de experimentos con diferentes configuraciones y vea cuál funciona mejor
4. Análise / Avaliação
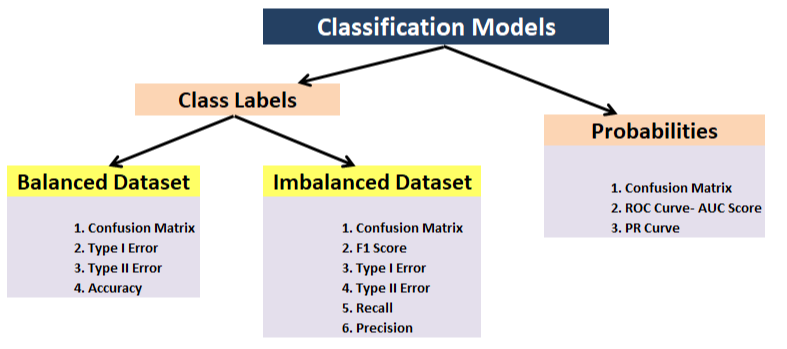
- Classificação: precisão, precisão, Recuperação, F1, matriz de confusão, precisión media media (detecção de objeto)
- Regressão – MSE, MUITO DE, R ^ 2
- Métrica basada en tareas: por exemplo, para el automóvil autónomo, es posible que desee saber el número de desconexiones
- Importância do recurso
- Treinamento / tiempo de inferencia / custo
- ¿Qué pasa si la herramienta: cómo se compara mi modelo con otros modelos?
- Ejemplos menos seguros: ¿en qué se equivoca el modelo?
- Compensación de sesgo / variância
5. Modelo de servicio (implementación de un modelo)
- Pon el modelo en Produção y mira como te va.
- Instrumentos que puede utilizar: TensorFlow Servinf, PyTorch Serving, Google AI Platform, Sagemaker
- MLOps: donde la ingeniería de software se encuentra con el aprendizaje automático, esencialmente toda la tecnología requerida en torno a un modelo de aprendizaje automático para que funcione en producción

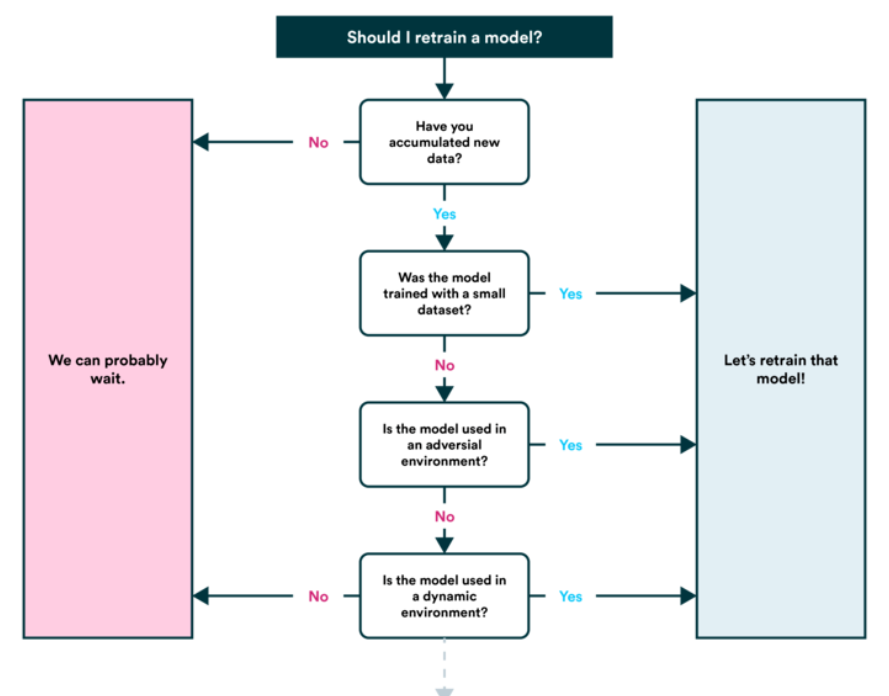
6. Volver a entrenar modelo
- Vea cómo funciona el modelo después de la publicación (o antes de la publicación) en función de varias métricas de evaluación y vuelva a consultar los pasos anteriores según sea necesario (lembrar, el aprendizaje automático es muy experimental, por lo que aquí es donde querrá realizar un seguimiento de sus datos y experimentos.
- También encontrará que las predicciones de su modelo comienzan a ‘envejecer’ (generalmente no en un estilo elegante) o ‘derivar’, como cuando las fuentes de datos cambian o se actualizan (nuevo hardware, etc.). Aquí es cuando querrás volver a entrenarlo.
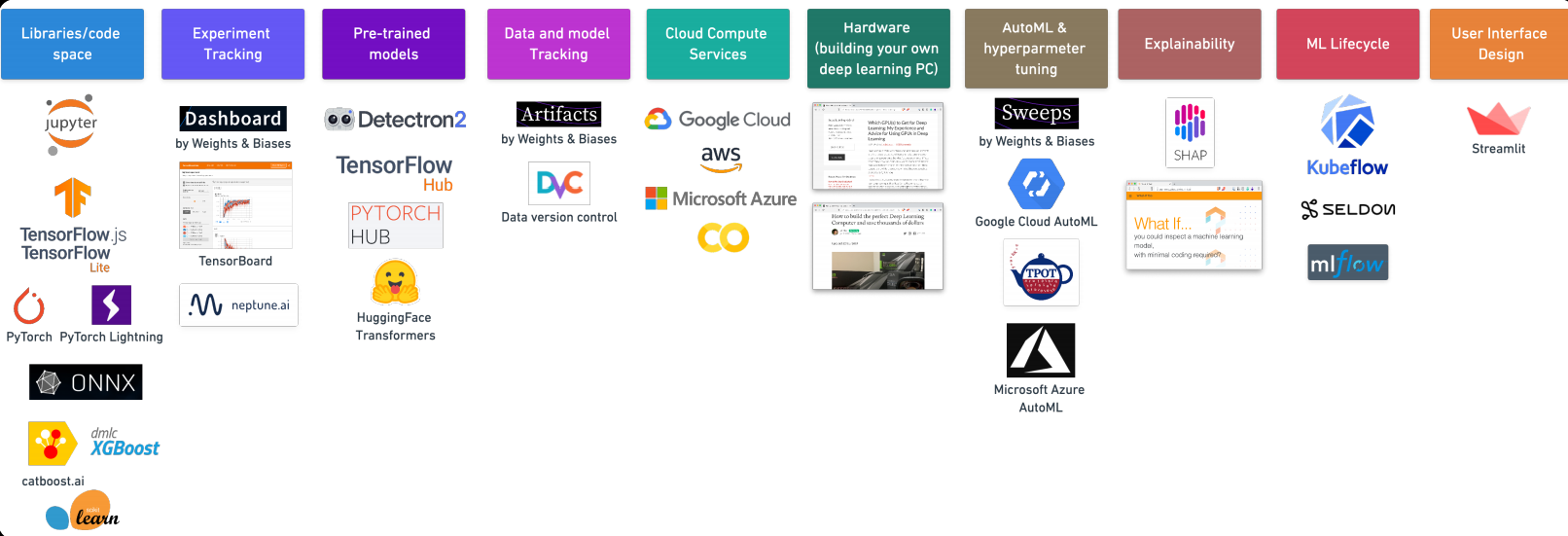
7. Herramientas de aprendizaje automático
Obrigado por ler isso. se você gosta deste item, Compartilhe com seus amigos. Em caso de alguma sugestão / dúvida, Comente abaixo.
Identificação de e-mail: [e-mail protegido]
Me siga no LinkedIn: LinkedIn
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





