Este artigo passou por uma série de mudanças!!
Eu estava inicialmente escrevendo sobre um tópico diferente (relacionado con la analíticaAnalytics refere-se ao processo de coleta, Meça e analise dados para obter insights valiosos que facilitam a tomada de decisões. Em vários campos, como negócio, Saúde e esporte, A análise pode identificar padrões e tendências, Otimize processos e melhore resultados. O uso de ferramentas avançadas e técnicas estatísticas é essencial para transformar dados em conhecimento aplicável e estratégico....). Eu estava quase terminando de escrever. Eu tinha investido aproximadamente 2 horas e escreveu um artigo médio. Se eu tivesse feito isso ao vivo, Eu teria feito bem! Mas algo em mim me impediu de fazê-lo viver. Só não fiquei satisfeito com o resultado. O artigo não transmite como me sinto sobre 2015 e como o DataPeaker pode ser útil para a sua aprendizagem analítica neste ano.
Então, Coloquei aquele artigo no lixo e comecei a repensar qual tópico faria justiça. Isso é o que eu terminei: deixe-me escrever artigos e guias incríveis sobre o que foi meu maior aprendizado em 2014: Biblioteca Scikit-learn ou sklearn em Python. Esse foi meu maior aprendizado, porque agora é a ferramenta que uso para qualquer projeto de aprendizado de máquina em que trabalho.
A criação desses artigos não seria imensamente útil para os leitores do blog, também me desafiaria a escrever sobre algo que ainda sou relativamente novo. Eu também adoraria ouvir de você sobre o mesmo: Qual foi o seu maior aprendizado em 2014 e você gostaria de compartilhar com os leitores deste blog?
O que é scikit-learn ou sklearn?
Scikit-learn é provavelmente a biblioteca mais útil para aprendizado de máquina em Python. A biblioteca sklearn contém muitas ferramentas eficientes para aprendizado de máquina e modelagem estatística, que incluem classificação, regressão, agrupamento e redução de dimensionalidade.
Observe que sklearn é usado para criar modelos de aprendizado de máquina. Não deve ser usado para ler os dados, manipulá-los e resumi-los. Existem bibliotecas melhores para isso (por exemplo, NumPy, Pandas, etc.)
![]()
Componentes de scikit-learn:
O Scikit-learn vem carregado com muitos recursos. Aqui estão alguns deles para ajudá-lo a entender a propagação:
- Algoritmos de aprendizagem supervisionadaO aprendizado supervisionado é uma abordagem de aprendizado de máquina em que um modelo é treinado usando um conjunto de dados rotulados. Cada entrada no conjunto de dados está associada a uma saída conhecida, permitindo que o modelo aprenda a prever resultados para novas entradas. Este método é amplamente utilizado em aplicações como classificação de imagens, Reconhecimento de fala e previsão de tendências, destacando sua importância em...: Pense em qualquer algoritmo de aprendizado de máquina supervisionado que você já ouviu falar e há uma boa chance de fazer parte do scikit-learn. De modelos lineares generalizados (por exemplo, regressão linear), apoiar máquinas de vetor (SVM), árvores de decisão e métodos bayesianos, todos eles fazem parte da caixa de ferramentas do scikit-learn. A disseminação de algoritmos de aprendizado de máquina é uma das principais razões para o alto uso do scikit-learn. Comecei a usar o scikit para resolver problemas de aprendizagem supervisionada e também o recomendaria para pessoas novas no scikit / aprendizado de máquina.
- Validação cruzada: Existem vários métodos para verificar a precisão dos modelos monitorados em dados invisíveis usando sklearn.
- Algoritmos de aprendizagem não supervisionados: Novamente, há uma grande variedade de algoritmos de aprendizado de máquina em oferta, da piscina, análise fatorial, análise de componente principal para redes neurais não supervisionadas.
- Vários conjuntos de dados de brinquedos: Isso foi útil ao aprender scikit-learn. Eu aprendi SAS usando vários conjuntos de dados acadêmicos (por exemplo, o conjunto de dados IRIS, o conjunto de dados de preços de imóveis em Boston). Tê-los à mão enquanto aprendia uma nova biblioteca ajudou muito..
- Extração de recursos: Scikit-aprenda a extrair recursos de imagens e texto (por exemplo, saco de palavras)
Comunidade / organizações que usam o scikit-learn:
Uma das principais razões por trás do uso de ferramentas de código aberto é a grande comunidade que possui. O mesmo vale para sklearn também. Existem cerca de 35 colaboradores do scikit-learn até o momento, o mais notável é Andreas Mueller (PS Andy folha de referências do aprendizado de máquina é uma das melhores visualizações para entender o espectro de algoritmos de aprendizado de máquina).
Existem várias organizações como o Evernote, Inria e AWeber mostrados em página inicial do scikit learn como usuários. Mas eu realmente acho que o uso real é muito mais.
Além dessas comunidades, existem várias reuniões ao redor do mundo. Havia também um Concurso de conhecimento Kaggle, que terminou recentemente, mas ainda pode ser um dos melhores lugares para começar a brincar com a biblioteca.
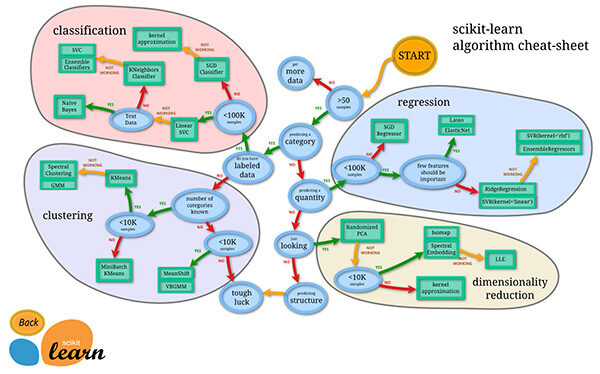
Folha de referências do aprendizado de máquina: consulte la imagen original para obtener una mejor resoluçãoo "resolução" refere-se à capacidade de tomar decisões firmes e atingir metas estabelecidas. Em contextos pessoais e profissionais, Envolve a definição de metas claras e o desenvolvimento de um plano de ação para alcançá-las. A resolução é fundamental para o crescimento pessoal e o sucesso em várias áreas da vida, pois permite superar obstáculos e manter o foco no que realmente importa....
Exemplo rápido:
Agora que você entende o ecossistema em alto nível, deixe-me ilustrar o uso de sklearn com um exemplo. A ideia é simplesmente ilustrar a simplicidade de uso do sklearn. Veremos vários algoritmos e as melhores maneiras de usá-los em um dos artigos a seguir..
Vamos construir uma regressão logística no conjunto de dados IRIS:
Paso 1: importar as bibliotecas relevantes e ler o conjunto de dados
importar numpy como np
importar matplotlib como plt
de conjuntos de dados de importação sklearn
de métricas de importação do sklearn
de sklearn.linear_model import LogisticRegression
Importamos todas as bibliotecas. A seguir, lemos o conjunto de dados:
conjunto de dados = conjuntos de datos.load_iris ()
Paso 2: Entenda o conjunto de dados olhando para distribuições e diagramas
Estou pulando esses passos por enquanto.. você pode ler este artigo se você quiser aprender análise exploratória.
Paso 3: construir um modelo de regressão logística no conjunto de dados e fazer previsões
model.fit (conjunto de dadosuma "conjunto de dados" ou conjunto de dados é uma coleção estruturada de informações, que pode ser usado para análise estatística, Aprendizado de máquina ou pesquisa. Os conjuntos de dados podem incluir variáveis numéricas, categórico ou textual, e sua qualidade é crucial para resultados confiáveis. Seu uso se estende a várias disciplinas, como remédio, Economia e Ciências Sociais, facilitando a tomada de decisão informada e o desenvolvimento de modelos preditivos.....dados, dataset.target)
esperado = dataset.target
previsto = modelo.prever (dataset.data)
Paso 4: Imprima a matriz de confusão
imprimir (metrics.classification_report (esperado, Previsto))
imprimir (metrics.confusion_matrix (esperado, Previsto))
Notas finais:
Esta foi uma visão geral de uma das bibliotecas de aprendizado de máquina mais poderosas e versáteis do Python. Foi também o maior aprendizado que tive em 2014. Qual foi o seu maior aprendizado em 2014? Compartilhe com o grupo por meio dos comentários abaixo.
Você está animado para aprender e usar o Scikit-learn?? Em caso afirmativo, fique ligado nos artigos restantes desta série.
Um rápido lembrete: se você ainda não fez check-out Discutir Vidhya Analítico porém, você deveria fazer isso agora. Os usuários estão aderindo rapidamente, então pegue o nome de usuário que quiser antes que outra pessoa o pegue.





