Visão geral
- Entenda o Spark Streaming e como ele funciona.
- Saiba mais sobre o Windows no Spark Streaming com um exemplo.
Introdução
De acordo com a IBM, a 60% de todas as informações sensoriais perde valor em alguns milissegundos se não for acionado. Levando em consideração que o mercado de Big Data e analytics atingiu o $ 125 bilhões e uma grande parte disso será atribuído à IoT no futuro, incapacidade de aproveitar informações em tempo real resultará em bilhões de dólares em perdas.
Exemplos de algumas dessas aplicações incluem uma empresa de telecomunicações, que calcula quantos de seus usuários usaram o WhatsApp nos últimos 30 minutos, um varejista que rastreia o número de pessoas que disseram coisas positivas sobre seus produtos hoje nas redes sociais, ou uma agência de aplicação da lei procurando um suspeito usando dados de tráfego CCTV.
Esta es la razón principal por la que los sistemas de procesamiento de flujos como Spark Streaming definirán el futuro de la analíticaAnalytics refere-se ao processo de coleta, Meça e analise dados para obter insights valiosos que facilitam a tomada de decisões. Em vários campos, como negócio, Saúde e esporte, A análise pode identificar padrões e tendências, Otimize processos e melhore resultados. O uso de ferramentas avançadas e técnicas estatísticas é essencial para transformar dados em conhecimento aplicável e estratégico.... em tempo real. Há também uma necessidade crescente de analisar os dados em repouso e os dados em movimento para alimentar os aplicativos., o que torna sistemas como o Spark, eles podem fazer ambos, seja ainda mais atraente e poderoso. É um sistema para todas as temporadas de Big Data.
Você aprenderá como o Spark Streaming não mantém apenas a familiar Spark API intacta, senão que também, underhood, usa RDD para armazenamento e tolerância a falhas. Isso permite que os profissionais do Spark entrem no mundo do streaming desde o início.. Com aquilo em mente, vamos direto ao assunto.
Introducción a Spark Streaming | de Harshit Agarwal | Metade
Tabela de conteúdo
- Apache SparkO Apache Spark é um mecanismo de processamento de dados de código aberto que permite a análise de grandes volumes de informações de forma rápida e eficiente. Seu design é baseado na memória, que otimiza o desempenho em comparação com outras ferramentas de processamento em lote. O Spark é amplamente utilizado em aplicativos de big data, Aprendizado de máquina e análise em tempo real, graças à sua facilidade de uso e...
- Ecossistema Apache Spark
- Spark Streaming: DStreams
- Spark Streaming: contexto de transmissão
- Exemplo: contagem de palavras
- Spark Streaming: Janela
- Uma janela baseada em: contagem de palavras
- uma (mais eficiente) baseado em janela: contagem de palavras
- Spark Streaming: operações de saída
Apache Spark
Apache Spark é um mecanismo de computação unificado e um conjunto de bibliotecas para processamento paralelo de dados em clusters de computador. No momento em que escrevo este artigo, Spark é o motor de código aberto mais desenvolvido para esta tarefa, tornando-o uma ferramenta padrão para qualquer desenvolvedor ou cientista de dados interessado em big data.
Spark oferece suporte a várias linguagens de programação amplamente utilizadas (Pitão, Java, Escala y R), inclui bibliotecas para várias tarefas, desde SQL a streaming e aprendizado de máquina, e corre em qualquer lugar, desde una computadora portátil hasta un cachoUm cluster é um conjunto de empresas e organizações interconectadas que operam no mesmo setor ou área geográfica, e que colaboram para melhorar sua competitividade. Esses agrupamentos permitem o compartilhamento de recursos, Conhecimentos e tecnologias, Promover a inovação e o crescimento económico. Os clusters podem abranger uma variedade de setores, Da tecnologia à agricultura, e são fundamentais para o desenvolvimento regional e a criação de empregos.... de miles de servidores. Isso o torna um sistema fácil de começar e escalar para processamento de big data ou escala incrivelmente grande.. Abaixo estão alguns dos recursos do Spark:
-
Motor rápido e de uso geral para processamento de dados em grande escala
-
O Spark pode dar suporte de maneira eficiente mais tipos de cálculos
-
Pode ler / escreva para qualquer sistema compatível com Hadoop (por exemplo, HDFSHDFS, o Sistema de Arquivos Distribuído Hadoop, É uma infraestrutura essencial para armazenar grandes volumes de dados. Projetado para ser executado em hardware comum, O HDFS permite a distribuição de dados em vários nós, garantindo alta disponibilidade e tolerância a falhas. Sua arquitetura é baseada em um modelo mestre-escravo, onde um nó mestre gerencia o sistema e os nós escravos armazenam os dados, facilitando o processamento eficiente de informações..)
- Velocidade: armazenamento de dados na memória para consultas iterativas muito rápidas
-
el sistema también es más eficiente que MapReduceO MapReduce é um modelo de programação projetado para processar e gerar grandes conjuntos de dados com eficiência. Desenvolvido pelo Google, Essa abordagem divide o trabalho em tarefas menores, que são distribuídos entre vários nós em um cluster. Cada nó processa sua parte e, em seguida, os resultados são combinados. Esse método permite dimensionar aplicativos e lidar com grandes volumes de informações, sendo fundamental no mundo do Big Data.... para aplicaciones complejas que se ejecutan en el disco
-
até 40 vezes mais rápido que o Hadoop
-
Ingerir dados de muitas fontes: Kafka, Twitter, HDFS, sockets TCP
-
Os resultados podem ser enviados para sistemas de arquivos, bases de dados, painéis ao vivo, mas não só
-

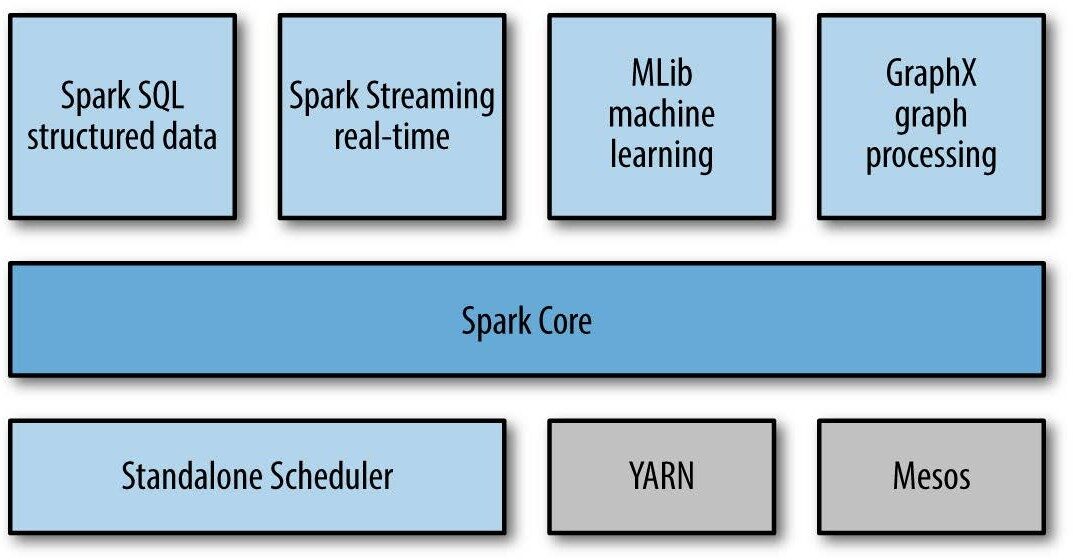
Ecossistema Apache Spark
A seguir estão os componentes do ecossistema Apache Spark:
- Spark Core: funcionalidade básica do Spark (agendamento de tarefas, gerenciamento de memória, recuperação de falha, interação de sistemas de armazenamento).
-
Spark SQL: pacote para trabalhar com dados estruturados consultados por meio de SQL e HiveQL
-
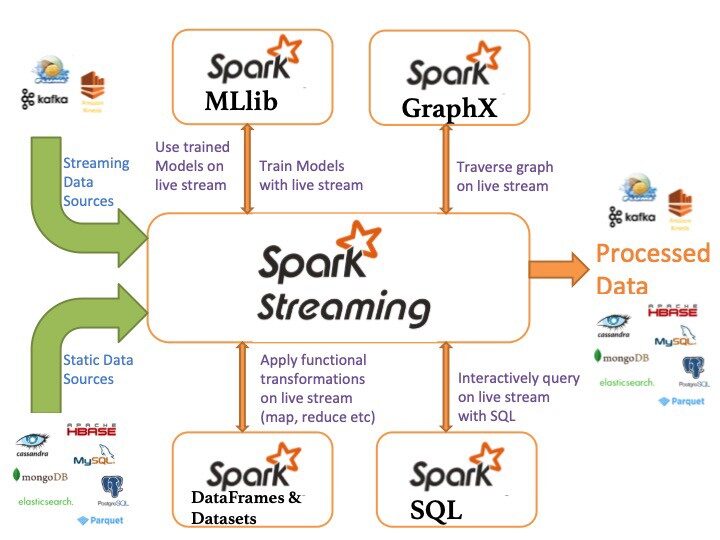
Spark Streaming: um componente que permite o processamento de fluxos de dados ao vivo (por exemplo, arquivos de log, mensagens de atualização de status)
- MLLib: MLLib é uma biblioteca de aprendizado de máquina como Mahout. Ele é construído no Spark e tem a capacidade de oferecer suporte a muitos algoritmos de aprendizado de máquina.
- GraphX: Para gráficos e cálculos gráficos, Spark tem seu próprio mecanismo de cálculo gráfico, chamado GraphX. É semelhante a outras ferramentas ou bancos de dados de processamento gráfico amplamente usados, como Neo4j, Giraffe e muitos outros bancos de dados gráficos distribuídos.
Spark Streaming: abstrações
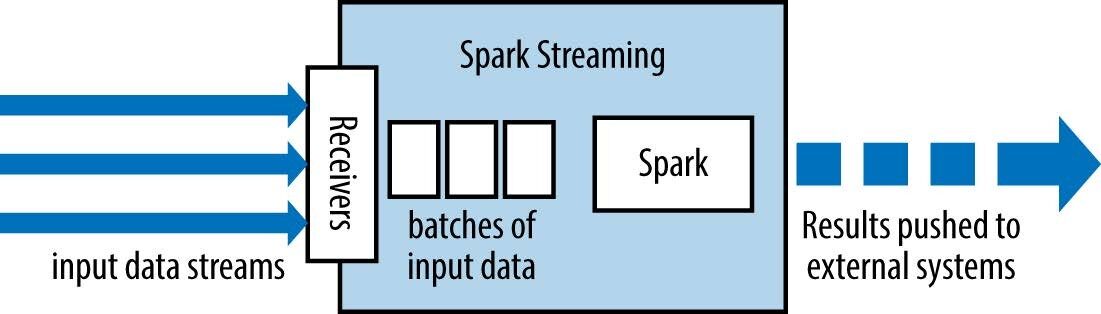
Spark Streaming tem um arquitetura de microlote Como segue:
-
trata a transmissão como uma série de lotes de dados
-
Novos lotes são criados em intervalos de tempo regulares.
-
o tamanho dos intervalos de tempo é chamado lote intervalo
-
o intervalo do lote é geralmente entre 500 ms e vários segundos
O valor de redução de cada janela é calculado de forma incremental.
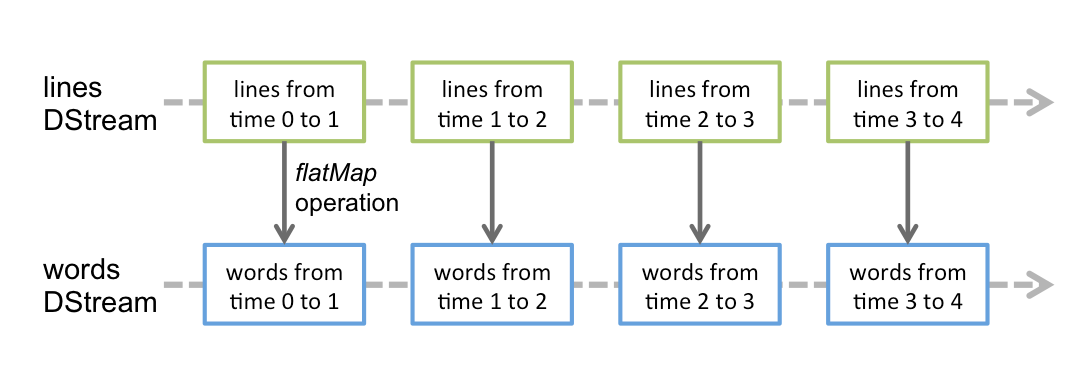
Sequência discretizada (DStream)
Corrente discretizada o DStream é a abstração básica fornecida pelo Spark Streaming. Representa um fluxo contínuo de dados, o fluxo de dados de entrada recebido da fonte ou o fluxo de dados processado gerado pela transformação do fluxo de entrada. Internamente, um DStream é representado por uma série contínua de RDDs, que é a abstração do Spark de um conjunto de dados distribuído e imutável (Assistir Guia de programação do Spark para mais detalhes). Cada RDD em um DStream contém dados de um determinado intervalo.
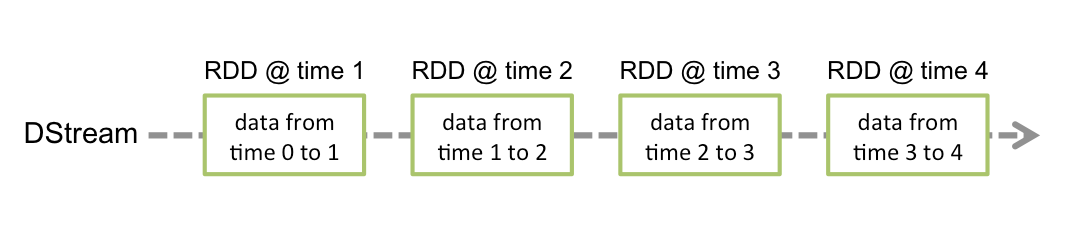
- As transformações RDD são calculadas pelo motor Spark
-
As operações DStream escondem a maioria desses detalhes
-
Qualquer operação aplicada em um DStream se traduz em operações nos RDDs subjacentes.
-
O valor de redução de cada janela é calculado de forma incremental.
Spark Streaming: contexto de transmissão
É o principal ponto de entrada para a funcionalidade Spark Streaming. Fornece métodos usados para criar DStreams de várias fontes de entrada. O Streaming Spark pode ser criado fornecendo um URL mestre do Spark e o nome do aplicativo, ou de uma configuração org.apache.spark.SparkConf, o from un org.apache.spark.SparkContext existente. O SparkContext associado pode ser acessado usando context.sparkContext.
Depois de criar e transformar DStreams, a computação em streaming pode ser iniciada e interrompida usando context.start() e, respectivamente. context.awaitTermination() permite que o thread atual aguarde o término do contexto por stop() ou para uma exceção.
Para executar um aplicativo SparkStreaming, precisamos definir StreamingContext. SparkContext é especializado em aplicativos de streaming.
O contexto de streaming em Java pode ser definido como segue:
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, batchInterval);
Onde:
-
Maestro é um URL de cluster Spark, Mesos o FIOYARN es un gestor de paquetes para JavaScript que permite la instalación y gestión eficiente de dependencias en proyectos de desarrollo. Desarrollado por Facebook, se caracteriza por su rapidez y seguridad en comparación con otros gestores. YARN utiliza un sistema de caché para optimizar las instalaciones y proporciona un archivo de bloqueo para garantizar la consistencia de las versiones de las dependencias en diferentes entornos de desarrollo....; para executar seu código no modo local, usar “local[K]"Onde K> = 2 representa paralelismo
-
nome do aplicativo é o nome do seu aplicativo
-
intervalo de lote intervalo de tempo (em segundos) de cada lote
Uma vez construído, oferecem dois tipos de operações:
Alguns exemplos são: mapa (), filtro () y minimizeByKey ()
-
-
transformações com estado: usa dados de lotes anteriores para calcular os resultados do lote atual. Inclui janelas deslizantes, monitoramento de status ao longo do tempo, etc.
-
Observe que um contexto de streaming pode ser iniciado apenas uma vez e deve ser iniciado depois de configurarmos todos os DStreams e operações de saída.
Fontes de dados básicas
As fontes de dados básicas do Spark Streaming estão listadas abaixo:
- Fluxos de arquivos: Usado para ler dados de arquivos em qualquer sistema de arquivos compatível com HDFS API (quer dizer, HDFS, S3, NFS, etc.), você pode criar um DStream como:
... = streamingContext.fileStream<...>(diretório);
- Streams com base em receptores personalizados: DStreams podem ser criados com streams de dados recebidos por meio de receptores personalizados, estendendo a classe Receiver
... = streamingContext.queueStream(queueOfRDDs)
- Fila RDD como fluxo: Para testar um aplicativo Spark Streaming com dados de teste, você também pode criar um DStream baseado em uma fila RDD, usando
... = streamingContext.queueStream(queueOfRDDs)
A maioria das transformações tem a mesma sintaxe aplicada a RDDs
-
Transformação
Senso
Mapa (função)
Retorna um novo DStream passando cada elemento do DStream de origem por meio de uma função func.
flatMap (função)
Semelhante ao mapa, mas cada elemento de entrada pode ser atribuído a 0 ou mais elementos de saída.
filtro (função)
Retorne um novo DStream selecionando apenas os registros do DStream de origem onde func retorna verdadeiro.
União (otherStream)
Retorna um novo DStream que contém a união dos elementos da fonte DStream e otherDStream.
Junte (outro fluxo)
Ao chamar dois DStreams de pares (K, V) e (K, C), retorna um novo DStream de (K, (V, C)) pares com todos os pares de elementos para cada chave.
Exemplo: contagem de palavras
SparkConf sparkConf = novo SparkConf()
.setMaster("local[2]").setAppName("Contagem de palavras");
JavaStreamingContext ssc = ...
JavaReceiverInputDStream<Fragmento> linhas = ssc.socketTextStream( ... );
JavadStream<Fragmento> palavras = linhas.flatMap(...);
JavaPairdStream<Fragmento, Inteiro> wordCounts = words
.mapToPair(s -> novo Tuple2<>(s, 1))
.reduzirByKey((i1, i2) -> i1 + i2);
wordCounts.print();
Spark Streaming: Janela
A função de janela mais simples é uma janela, que permite criar um novo DStream, calculado aplicando los parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... de ventana al antiguo DStream. você pode usar qualquer uma das operações dstream no novo fluxo, para que você tenha toda a flexibilidade que você quer.
Cálculos em janelas permitem que você aplique transformações em uma janela de dados deslizante. Qualquer operação de janela precisa especificar dois parâmetros:
- janela Longas
- A duração da janela em segundos.
- Deslizante intervalo
- O intervalo em que a operação da janela é realizada em segundos.
- esses parâmetros devem ser múltiplos do intervalo do lote.
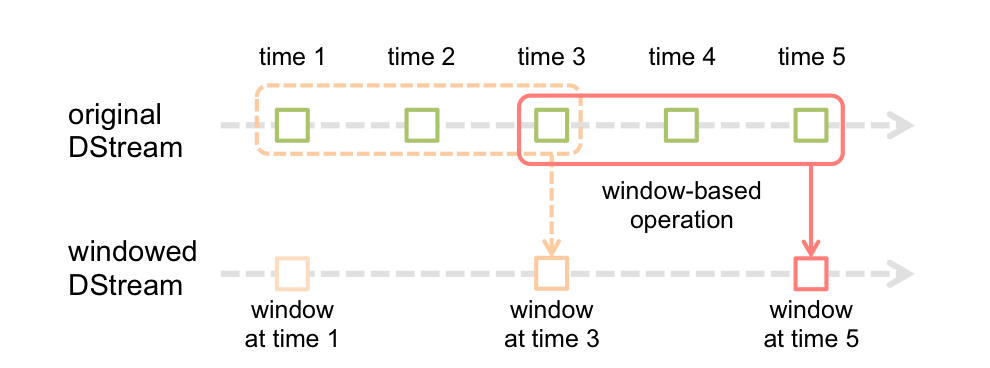
janela(janelaLength, slideInterval)
Retorna um novo DStream calculado com base em lotes na janela.
...
JavaStreamingContext ssc = ...
JavaReceiverInputDStream<Fragmento> linhas = ...
JavadStream<Fragmento> linesInWindow =
lines.window(WINDOW_SIZE, SLIDING_INTERVAL);
JavaPairdStream<Fragmento, Inteiro> wordCounts = linhasInWindow.flatMap(SPLIT_LINE)
.mapToPair(s -> novo Tuple2<>(s, 1))
.reduzirByKey((i1, i2) -> i1 + i2);
- reduzirByWindow (função, InvFunc, janelaLength, slideInterval)
- Retorna uma nova sequência de um único item, criado adicionando elementos na sequência durante um intervalo deslizante usando função (que deve ser associativo).
- O valor de redução de cada janela é calculado de forma incremental.
- reduzirByKeyAndWindow (função, InvFunc, janelaLength, slideInterval)
- Ao chamar um DStream de (K, V) Pares, retorna um novo DStream de (K, V) pares onde os valores para cada tecla são adicionados usando a função de redução dada função sobre lotes em uma janela deslizante.
Para realizar essas transformações, precisamos definir um diretório de pontos de verificação
À base de janelas: contagem de palavras
...
JavaPairdStream<Fragmento, Inteiro> wordCountPairs = ssc.socketTextStream(...)
.flatMap(x -> Arrays.asList(ESPAÇO.split(x)).Iterador())
.mapToPair(s -> novo Tuple2<>(s, 1));
JavaPairdStream<Fragmento, Inteiro> wordCounts = wordCountPairs
.reduceByKeyAndWindow((i1, i2) -> i1 + i2, WINDOW_SIZE, SLIDING_INTERVAL);
wordCounts.print();
wordCounts.foreachRDD(novo SaveAsLocalFile());
uma (mais eficiente) baseado em janela: contagem de palavras
Em uma versão mais eficiente, o valor de redução de cada janela é calculado incrementalmente.
note que os pontos de verificação devem ser habilitados para usar esta operação.
... ssc.checkpoint(LOCAL_CHECKPOINT_DIR); ... JavaPairdStream<Fragmento, Inteiro> wordCounts = wordCountPairs.reduceByKeyAndWindow( (i1, i2) -> i1 + i2, (i1, i2) -> i1 - i2, WINDOW_SIZE, SLIDING_INTERVAL);
Spark Streaming: operações de saída
Las operaciones de salida permiten que los datos de DStream se envíen a sistemas externos como una base de dadosUm banco de dados é um conjunto organizado de informações que permite armazenar, Gerencie e recupere dados com eficiência. Usado em várias aplicações, De sistemas corporativos a plataformas online, Os bancos de dados podem ser relacionais ou não relacionais. O design adequado é fundamental para otimizar o desempenho e garantir a integridade das informações, facilitando assim a tomada de decisão informada em diferentes contextos.... o un sistema de archivos
-
Operação de saída
Senso
Imprimir()
Imprime los primeros diez elementos de cada lote de datos en un DStream en el nóO Nodo é uma plataforma digital que facilita a conexão entre profissionais e empresas em busca de talentos. Através de um sistema intuitivo, permite que os usuários criem perfis, Compartilhar experiências e acessar oportunidades de trabalho. Seu foco em colaboração e networking torna o Nodo uma ferramenta valiosa para quem deseja expandir sua rede profissional e encontrar projetos que se alinhem com suas habilidades e objetivos.... del controlador que ejecuta la aplicación.
saveAsTextFiles (prefixo, [sufixo])
Salve o conteúdo deste DStream como arquivos de texto. O nome do arquivo em cada intervalo de lote é gerado com base no prefixo.
saveAsHadoopFiles (prefixo, [sufixo])
Salve o conteúdo deste DStream como arquivos Hadoop.
saveAsObjectFiles (prefixo, [sufixo])
Salve o conteúdo deste DStream como SequenceFiles de objetos Java serializados.
foreachRDD (função)
Operador de saída genérico que aplica uma função, função, a cada RDD gerado a partir da sequência.
Referências online
• Documentação do Spark
• Documentação do Spark
conclusão
Deve ficar claro que Spark Streaming apresenta uma maneira poderosa de escrever aplicativos de streaming. Pegar um trabalho em lote que você já está executando e convertê-lo em um trabalho de streaming com quase nenhuma alteração de código é simples e extremamente útil do ponto de vista da engenharia se você precisar que esse trabalho interaja intimamente com o resto do seu aplicativo de processamento..
Eu recomendo que você consulte os seguintes recursos de engenharia de dados para melhorar seu conhecimento:
Se você gostou do artigo, deixe um comentário na seção de comentários abaixo.





