“Assim como os atletas não podem vencer sem uma combinação sofisticada de estratégia, forma, atitude, tática e velocidade, a engenharia de desempenho requer uma boa coleção de métricas e ferramentas para entregar os resultados de negócios desejados”.– Todd DeCapua
Introdução:
Ao passar dos anos, a adoção de aprendizado de máquina para conduzir decisões de negócios aumentou exponencialmente. De acordo com a Forbes, Projeta-se que o ML cresça para $ 30.6 bilhões para 2024 e não é surpreendente ver a miríade de soluções de ML personalizadas invadindo o mercado que atendem a necessidades específicas de negócios. A facilidade de disponibilidade de recursos de computação, infraestrutura e automação em nuvem acelerou ainda mais.
A tendência atual de aproveitar os poderes do ML nos negócios levou cientistas e engenheiros de dados a projetar soluções / serviços inovadores e um desses serviços foi Model As A Service (MaaS). Usamos muitos desses serviços sem o conhecimento de como foram criados ou veiculados na web, alguns exemplos incluem visualização de dados, reconhecimento facial, processamento de linguagem natural, análise preditiva e muito mais. Em resumo, MaaS encapsula todos os dados complexos, treinamento e avaliação de modelo, implementação, etc., e permite que os clientes os consumam para seu propósito.
Por mais simples que pareça usar esses serviços, existem muitos desafios na criação de tal serviço, por exemplo: Como mantemos o serviço? Como podemos garantir que a precisão do nosso modelo não diminua com o tempo? etc. Como acontece com qualquer serviço ou aplicativo, um fator importante a considerar é a carga ou tráfego que um serviço / API pode controlar para garantir seu tempo de atividade. O melhor recurso da API é ter um ótimo desempenho e a única maneira de testar isso é pressionando a API para ver como ela responde. Este é o teste de carga.
Neste blog, não veremos apenas como este serviço é construído, mas também como testar a carga de serviço para planejar os requisitos de hardware / infraestrutura no ambiente de produção. Tentaremos alcançá-lo na seguinte ordem:
- Crie uma API simples com FastAPI
- Construir um modelo de classificação em Python
- Envolva o modelo com FastAPI
- Teste a API com o cliente Postman
- Teste de carga com Locust
Comecemos !!
Criação de uma API web simples usando FastAPI:
O código a seguir mostra a implementação básica do FastAPI. O código é usado para criar uma API web simples que, ao receber um determinado bilhete, produz uma saída específica. Aqui está a divisão do código:
- Carregue as bibliotecas
- Crie um objeto de aplicativo
- Crie uma rota com @ app.get ()
- Escreva uma função do controlador que tenha um host e um número de porta definidos
de importação fastapi FastAPI, Solicitar
de digitar import Dict
from pydantic import BaseModel
importar uvicórnio
importar numpy como np
importar picles
importar pandas como pd
importar json
app = FastAPI()
@ app.get("/")
async def root():
Retorna {"mensagem": "Construído com FastAPI"}
if __name__ == '__main__':
uvicorn.run(aplicativo, host ="127.0.0.1", porta = 8000)
Uma vez executado, você pode navegar para o navegador com o url: http: // localhost: 8000 e observe o resultado que, neste caso, será ‘ Construído com FastAPI ‘
Criação de uma API a partir de um modelo de ML usando FastAPI:
Agora que você tem uma ideia clara do FastAPI, vamos ver como você pode encapsular um modelo de aprendizado de máquina (desenvolvido em Python) em uma API em Python. Vou usar o conjunto de dados (diagnóstico) Câncer de Mama em Wisconsin. O objetivo deste projeto de ML é prever se uma pessoa tem um tumor benigno ou maligno. usarei VSCode como meu editor e observe que testaremos nosso serviço com Carteiro Cliente. Estas são as etapas que seguiremos.
- Vamos primeiro construir nosso modelo de classificação: KNeighboursClassifier ()
- Construir nosso arquivo de servidor que terá lógica para API no FlastAPI estrutura.
- Finalmente, vamos testar nosso serviço com Carteiro
Paso 1: Modelo de classificação
Um modelo de classificação simples com o processo padrão de carregamento de dados, dividir dados em trem / prova, seguido pela construção do modelo e salvando o modelo no formato de decapagem para a unidade. Não vou entrar em detalhes da construção da maquete, já que o artigo é sobre teste de carga.
importar pandas como pd
importar numpy como np
de sklearn.model_selection import train_test_split
de sklearn.neighbors import KNeighboursClassifier
import joblib, salmoura
importar os
importar yaml
# pasta para carregar o arquivo de configuração
CONFIG_PATH = "../Configs"
# Função para carregar o arquivo de configuração yaml
def load_config(config_name):
"""[A função pega o arquivo de configuração yaml como entrada e carrega o arquivo de configuração]
Args:
config_name ([yaml]): [A função leva a configuração do yaml como entrada]
Devoluções:
[fragmento]: [Retorna a configuração]
"""
com aberto(os.path.join(CONFIG_PATH, config_name)) como arquivo:
config = yaml.safe_load(Arquivo)
retornar configuração
config = load_config("config.yaml")
#caminho para o conjunto de dados
filename = "../../Data / breast-cancer-wisconsin.csv"
#Carregar dados
data = pd.read_csv(nome do arquivo)
#substituir "?" com -99999
data = data.replace('?', -99999)
# drop id coluna
data = data.drop(config["drop_columns"], eixo = 1)
# Defina X (variáveis independentes) e y (variável de destino)
X = np.array(data.drop(config["target_name"], 1))
y = np.array(dados[config["target_name"]])
X_train, X_test, y_train, y_test = train_test_split(
X, e, test_size = config["test_size"], random_state = config["random_state"]
)
# chame nosso classificador e ajuste nossos dados
classifier = KNeighborsClassifier(
n_neighs = config["n_neighs"],
pesos = configuração["pesos"],
algoritmo = configuração["algoritmo"],
leaf_size = config["tamanho_da_folha"],
p = config["p"],
metric = config["métrica"],
n_jobs = config["n_jobs"],
)
# treinando o classificador
classifier.fit(X_train, y_train)
# teste nosso classificador
resultado = classifier.score(X_test, y_test)
imprimir("A pontuação de precisão é. {:.1f}".formato(resultado))
# Salvando modelo no disco
pickle.dump(classificador, abrir('../../FastAPI//Models/KNN_model.pkl','wb'))
Você pode acessar o código completo em Github
Paso 2: compilar a API com FastAPI:
Vamos nos basear no exemplo básico que fizemos na seção anterior.
Carregue as bibliotecas:
de importação fastapi FastAPI, Solicitar de digitar import Dict from pydantic import BaseModel importar uvicórnio importar numpy como np importar picles importar pandas como pd importar json
Carregue o modelo KNN salvo e escreva uma função de roteamento para retornar o Json:
app = FastAPI()
@ app.get("/")
async def root():
Retorna {"mensagem": "Olá Mundo"}
# Carregue o modelo
# model = pickle.load(abrir('../Models/KNN_model.pkl','rb'))
model = pickle.load(abrir('../Models/KNN_model.pkl','rb'))
@ app.post('/prever')
def pred(corpo: dict):
"""[resumo]
Args:
corpo (dict): [O método pred considera a resposta como entrada que está no formato Json e retorna o valor previsto do modelo salvo.]
Devoluções:
[Json]: [A função pred retorna o valor previsto]
"""
# Obtenha os dados da solicitação POST.
data = body
varList = []
para val em data.values():
varList.append(val)
# Faça previsões a partir do modelo salvo
prediction = model.predict([varList])
# Extraia o valor
output = prediction[0]
#retorna a saída no formato json
Retorna {'A previsão é': saída}
# 5. Execute a API com uvicorn
# Será executado em http://127.0.0.1:8000
if __name__ == '__main__':
"""[A API será executada no host local na porta 8000]
"""
uvicorn.run(aplicativo, host ="127.0.0.1", porta = 8000)
Você pode acessar o código completo em Github.
Usando Cliente Postman:
Em nossa seção anterior, criamos uma API simples em que pressionando o http: // localhost: 8000 no navegador, recebemos uma mensagem de saída “Construído com FastAPI”. Isso é bom, desde que a saída seja mais simples e uma entrada do usuário ou do sistema seja esperada. Mas estamos construindo um modelo como serviço no qual enviamos dados como entrada para o modelo prever.. Em tal caso, precisaremos de uma maneira melhor e mais fácil de testá-lo. Usaremos carteiro para testar nossa API.
- Execute o arquivo server.py
- Abra o cliente Postman e preencha os detalhes relevantes destacados abaixo e clique no botão enviar.
- Veja o resultado na seção de respostas abaixo.
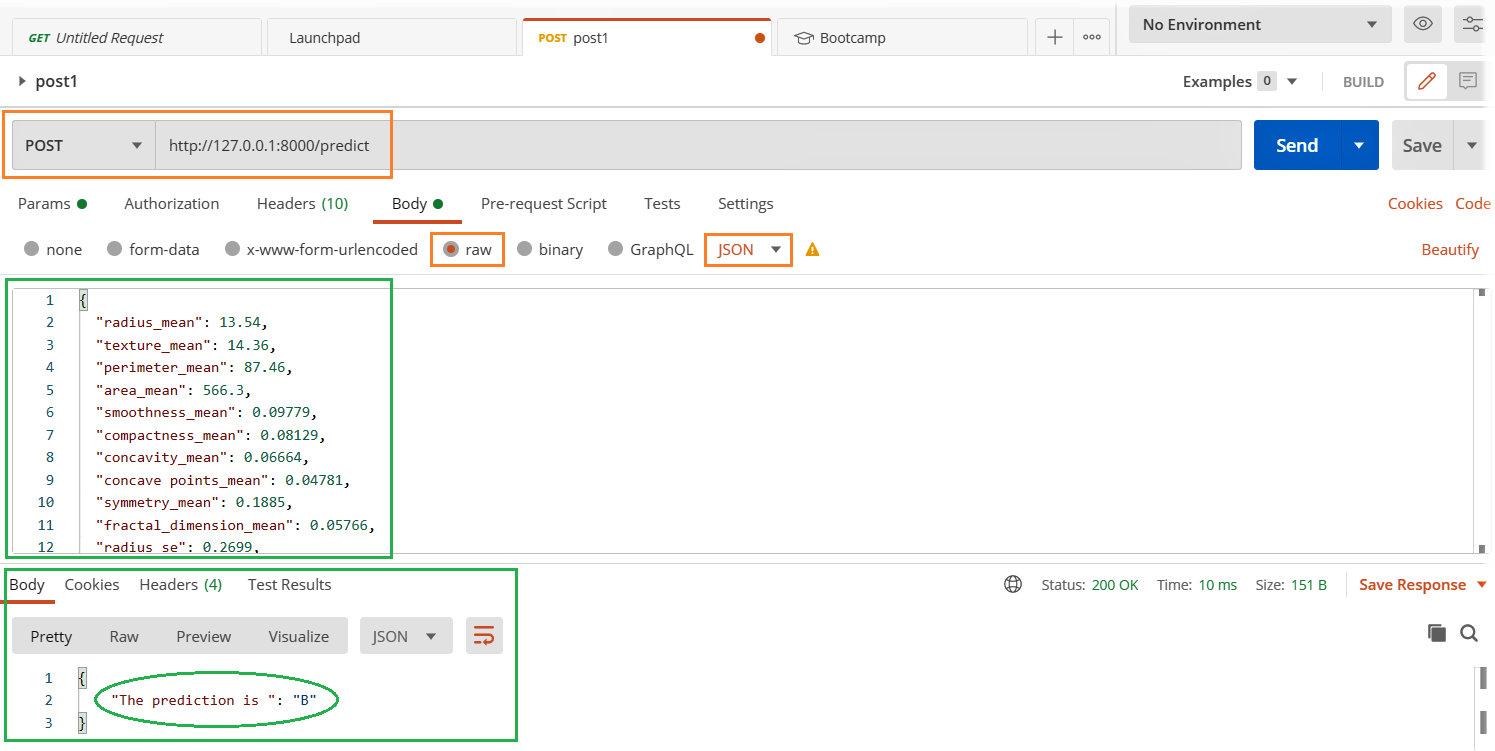
Seus aplicativos e serviços estão estáveis sob carga máxima??
Hora de carregar o teste:
Exploraremos a biblioteca Locust para testes de carga e a maneira mais fácil de instalar Langosta isto é
pip install locust
Vamos criar um perf.py arquivo com o seguinte código. Eu me referi ao código Começo rápido página de lagosta
tempo de importação
importar json
from Locust import HttpUser, tarefa, entre
classe QuickstartUser(HttpUser):
wait_time = between(1, 3)
@tarefa(1)
def testFlask(auto):
carga = {
"radius_mean": 13.54,
"texture_mean": 14.36,
......
......
"fractal_dimension_worst": 0.07259}
myheaders = {'Tipo de conteúdo': 'application / json', 'Aceitar': 'application / json'}
self.client.post("/prever", data = json.dumps(carga), headers = myheaders)
Acesse o arquivo de código completo em Github
Comece a lagosta: Navegue até o diretório perf.py e execute o seguinte código.
locust -f perf.py
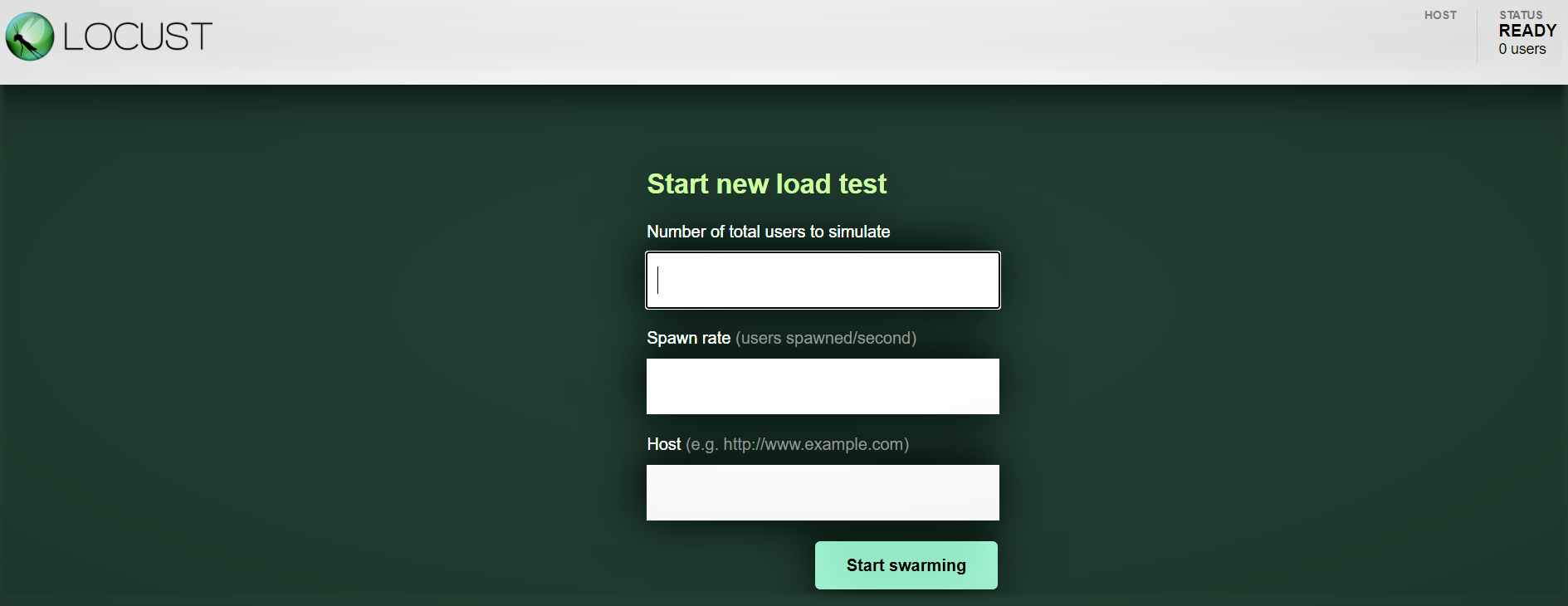
Interfaz web Locust:
Depois de iniciar o Locust com o comando acima, navegue para um navegador e aponte para http: // localhost: 8089. Você deve ver a seguinte página:
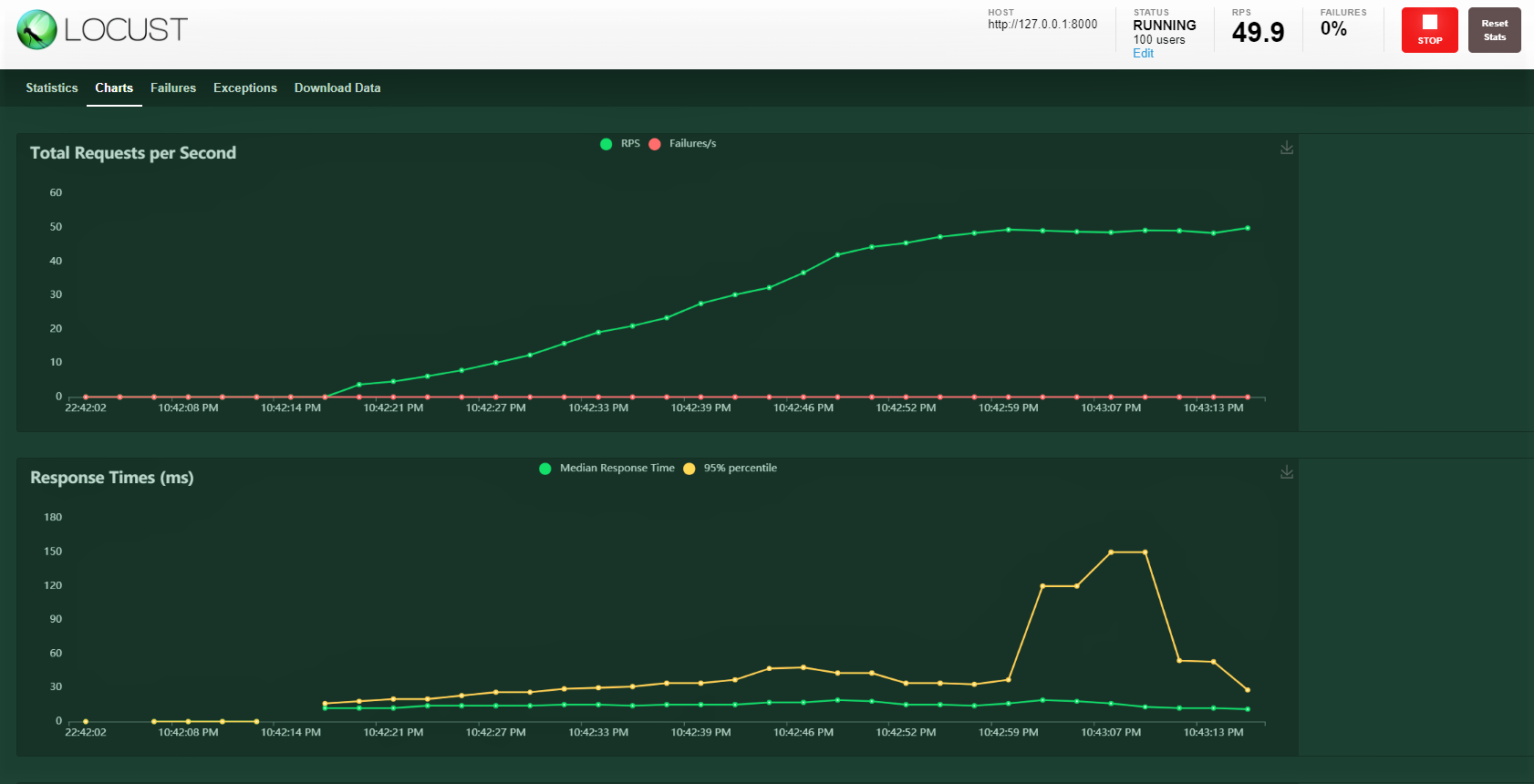
Vamos tentar com 100 Comercial, relação de geração 3 seu anfitrião: http: 127.0.0.1: 8000 onde nossa API está rodando. Você pode ver a seguinte tela. Você pode ver o aumento da carga ao longo do tempo e o tempo de resposta, uma representação gráfica mostra o tempo médio e outras métricas.
Observação: certifique-se de que server.py esteja rodando.

conclusão:
Cobrimos muito neste blog, de construir um modelo, fechando com um FastAPI, a prova de serviço com o carteiro e por fim a realização de um teste de carga com 100 usuários simulados acessando nosso serviço com uma carga gradualmente crescente. Conseguimos monitorar como o serviço está respondendo.
Na maioria das vezes, existem SLAs de nível empresarial que devem ser cumpridos, quer dizer, mantenha um certo limite para um tempo de resposta como 30ms ou 20ms. Se os SLAs não forem cumpridos, existem potenciais implicações financeiras dependendo do contrato ou da perda de clientes, porque eles não receberam o serviço com rapidez suficiente.
Um teste de carga nos ajuda a entender os pontos máximos e potenciais de falha. Mais tarde, podemos planejar uma ação proativa, aumentando nossa capacidade de hardware e, se o serviço for implantado no tipo de configuração Kubernetes, configure-o para aumentar o número de pods com o aumento da carga.
Boa aprendizagem !!!!
Você pode se conectar comigo – Linkedin
Você pode encontrar o código para referência: Github
Referências
https://docs.locust.io/en/stable/quickstart.html
https://fastapi.tiangolo.com/
https://unsplash.com/
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





