Este post fue hecho público como parte del Blogatón de ciencia de datos
Introducción
Python es un lenguaje de programación fácil de aprender, lo que lo convierte en la opción preferida por los principiantes en ciencia de datos, análisis de datos y aprendizaje automático. Además cuenta con una gran comunidad de estudiantes en línea y excelentes bibliotecas centradas en datos.
Con tantos datos que se generan, es esencial que los datos que usamos para aplicaciones de ciencia de datos como el aprendizaje automático y el modelado predictivo estén limpios. Pero, ¿qué entendemos por datos limpios? ¿Y qué ensucia los datos en primer lugar?
Los datos sucios simplemente significan datos erróneos. La duplicación de registros, los datos incompletos o desactualizados y el análisis incorrecto pueden ensuciar los datos. Estos datos deben limpiarse. La limpieza de datos (o limpieza de datos) se refiere al procedimiento de «limpiar» estos datos sucios, identificando errores en los datos y después rectificándolos.
La limpieza de datos es un paso importante en un proyecto de aprendizaje automático, y cubriremos algunas técnicas básicas de limpieza de datos (en Python) en este post.
Limpieza de datos en Python
Aprenderemos más sobre la limpieza de datos en Python con la ayuda de un conjunto de datos de muestra. Usaremos el Conjunto de datos de vivienda rusa en Kaggle.
Comenzaremos importando las bibliotecas imprescindibles.
# import libraries import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline
Descargue los datos y después léalos en un Pandas DataFrame usando la función read_csv () y especificando la ruta del archivo. Posteriormente, use el atributo de forma para verificar el número de filas y columnas en el conjunto de datos. El código para esto es el siguiente:
df = pd.read_csv('housing_data.csv')
df.shape
El conjunto de datos tiene 30 471 filas y 292 columnas.
Ahora separaremos las columnas numéricas de las columnas categóricas.
# select numerical columns df_numeric = df.select_dtypes(include=[np.number]) numeric_cols = df_numeric.columns.values # select non-numeric columns df_non_numeric = df.select_dtypes(exclude=[np.number]) non_numeric_cols = df_non_numeric.columns.values
Ahora hemos terminado con los pasos preliminares. Ahora podemos pasar a la limpieza de datos. Comenzaremos identificando columnas que contienen valores faltantes e intentaremos corregirlos.
Valores faltantes
Comenzaremos calculando el porcentaje de valores que faltan en cada columna y después almacenando esta información en un DataFrame.
# % of values missing in each column
values_list = list()
cols_list = list()
for col in df.columns:
pct_missing = np.mean(df[col].isnull())*100
cols_list.append(col)
values_list.append(pct_missing)
pct_missing_df = pd.DataFrame()
pct_missing_df['col'] = cols_list
pct_missing_df['pct_missing'] = values_list
El DataFrame pct_missing_df ahora contiene el porcentaje de valores perdidos en cada columna junto con los nombres de las columnas.
Además podemos crear una imagen a partir de esta información para una mejor comprensión usando el siguiente código:
pct_missing_df.loc[pct_missing_df.pct_missing > 0].plot(kind='bar', figsize=(12,8)) plt.show()
El resultado después de la ejecución de la línea de código anterior debería verse así:
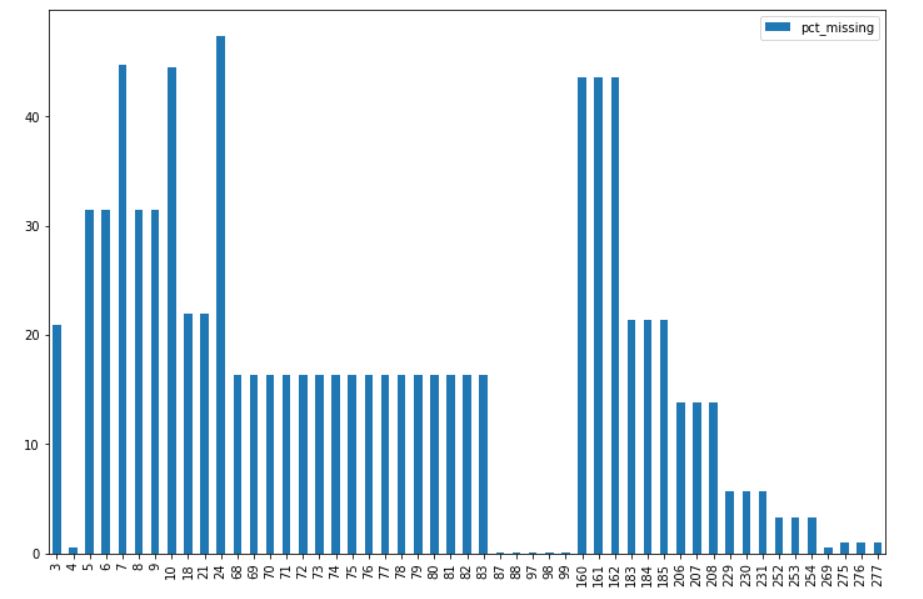
Es claro que a algunas columnas les faltan muy pocos valores, mientras que a otras columnas les falta un porcentaje sustancial de valores. Ahora arreglaremos estos valores faltantes.
Hay varias formas en las que podemos corregir estos valores perdidos. Algunos de ellos son»
Observaciones de caída
Una forma podría ser descartar aquellas observaciones que contengan algún valor nulo para cualquiera de las columnas. Esto funcionará cuando el porcentaje de valores perdidos en cada columna sea muy inferior. Eliminaremos las observaciones que contengan nulos en aquellas columnas que tengan menos del 0,5% de nulos. Estas columnas serían metro_min_walk, metro_km_walk, railroad_station_walk_km, railroad_station_walk_min e ID_railroad_station_walk.
less_missing_values_cols_list = list(pct_missing_df.loc[(pct_missing_df.pct_missing < 0.5) & (pct_missing_df.pct_missing > 0), 'col'].values) df.dropna(subset=less_missing_values_cols_list, inplace=True)
Esto reducirá la cantidad de registros en nuestro conjunto de datos a 30,446 registros.
Borrar columnas (funciones)
Otra manera de abordar los valores perdidos en un conjunto de datos sería borrar aquellas columnas o características que tengan un porcentaje significativo de valores perdidos. Estas columnas no contienen mucha información y se pueden borrar por completo del conjunto de datos. En nuestro caso, eliminemos todas aquellas columnas a las que les faltan más del 40% de valores. Estas columnas serían build_year, state, hospital_beds_raion, cafe_sum_500_min_price_avg, cafe_sum_500_max_price_avg y cafe_avg_price_500.
# dropping columns with more than 40% null values _40_pct_missing_cols_list = list(pct_missing_df.loc[pct_missing_df.pct_missing > 40, 'col'].values) df.drop(columns=_40_pct_missing_cols_list, inplace=True)
La cantidad de características en nuestro conjunto de datos ahora es 286.
Imputar valores perdidos
Aún faltan datos en nuestro conjunto de datos. Ahora imputaremos los valores faltantes en cada columna numérica con el valor mediano de esa columna.
df_numeric = df.select_dtypes(include=[np.number])
numeric_cols = df_numeric.columns.values
for col in numeric_cols:
missing = df[col].isnull()
num_missing = np.sum(missing)
if num_missing > 0: # impute values only for columns that have missing values
med = df[col].median() #impute with the median
df[col] = df[col].fillna(med)
Los valores que faltan en las columnas numéricas ahora están corregidos. En el caso de columnas categóricas, reemplazaremos los valores perdidos con los valores de moda de esa columna.
df_non_numeric = df.select_dtypes(exclude=[np.number])
non_numeric_cols = df_non_numeric.columns.values
for col in non_numeric_cols:
missing = df[col].isnull()
num_missing = np.sum(missing)
if num_missing > 0: # impute values only for columns that have missing values
mod = df[col].describe()['top'] # impute with the most frequently occuring value
df[col] = df[col].fillna(mod)
Todos los valores faltantes en nuestro conjunto de datos ya se han tratado. Podemos verificar esto ejecutando el siguiente código:
df.isnull().sum().sum()
Si la salida es cero, significa que ahora no quedan valores faltantes en nuestro conjunto de datos.
Además podemos reemplazar los valores que faltan con un valor particular (como -9999 o ‘faltante’) que indicará el hecho de que faltaban los datos en este lugar. Esto puede ser un sustituto de la imputación de valor perdido.
Valores atípicos
Un valor atípico es una observación inusual que se aleja de la mayoría de los datos. Los valores atípicos pueden afectar significativamente el rendimiento de un modelo de aprendizaje automático. Por eso, es esencial identificar los valores atípicos y tratarlos.
Tomemos la columna ‘life_sq’ como ejemplo. Primero usaremos el método describe () para mirar las estadísticas descriptivas y ver si podemos recolectar información de él.
df.life_sq.describe()
La salida se verá así:
count 30446.000000 mean 33.482658 std 46.538609 min 0.000000 25% 22.000000 50% 30.000000 75% 38.000000 max 7478.000000 Name: life_sq, dtype: float64
De la salida, es claro que algo no está correcto. El valor máximo parece ser anormalmente grande en comparación con los valores medio y mediano. Hagamos un diagrama de caja de estos datos para tener una mejor idea.
df.life_sq.plot(kind='box', figsize=(12, 8)) plt.show()
La salida se verá así:
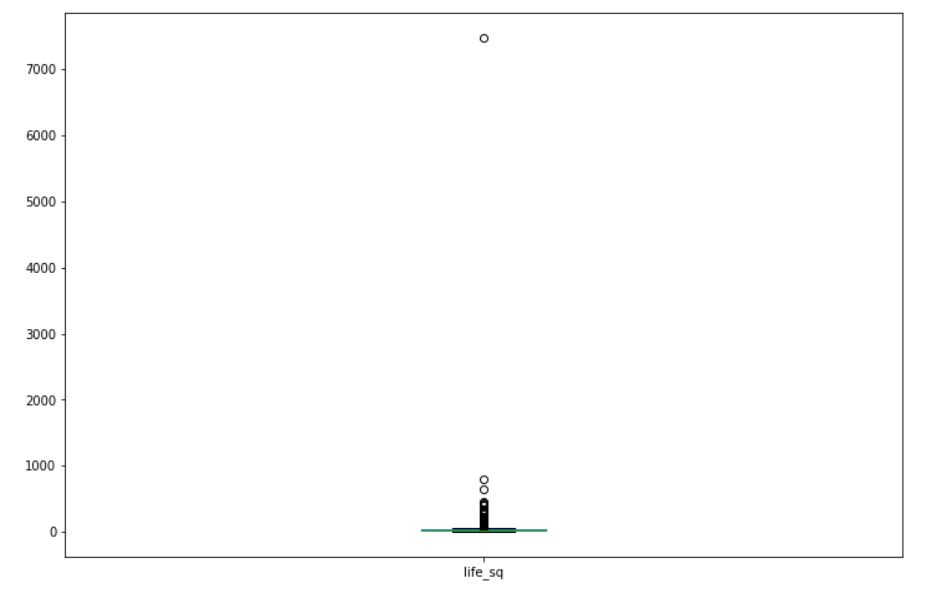
De la gráfica de caja se desprende claramente que la observación respectivo al valor máximo (7478) es un valor atípico en estos datos. Las estadísticas descriptivas, los diagramas de cajaLos diagramas de caja, también conocidos como diagramas de caja y bigotes, son herramientas estadísticas que representan la distribución de un conjunto de datos. Estos diagramas muestran la mediana, los cuartiles y los valores atípicos, lo que permite visualizar la variabilidad y la simetría de los datos. Son útiles en la comparación entre diferentes grupos y en el análisis exploratorio, facilitando la identificación de tendencias y patrones en los datos.... y los diagramas de dispersión nos ayudan a identificar valores atípicos en los datos.
Podemos lidiar con los valores atípicos como lo hicimos con los valores perdidos. Podemos borrar las observaciones que creemos que son valores atípicos, o podemos reemplazar los valores atípicos con valores adecuados, o podemos hacer algún tipo de transformación en los datos (como logaritmo o exponencial). En nuestro caso, eliminemos el registro donde el valor de ‘life_sq’ es 7478.
# removing the outlier value in life_sq column df = df.loc[df.life_sq < 7478]
Registros duplicados
A veces, los datos pueden contener valores duplicados. Es esencial borrar los registros duplicados de su conjunto de datos antes de continuar con cualquier proyecto de aprendizaje automático. En nuestros datos, dado que la columna de ID es un identificador único, eliminaremos los registros duplicados considerando todos menos la columna de ID.
# dropping duplicates by considering all columns other than ID cols_other_than_id = list(df.columns)[1:] df.drop_duplicates(subset=cols_other_than_id, inplace=True)
Esto nos ayudará a borrar los registros duplicados. Al utilizar el método de forma, puede verificar que los registros duplicados verdaderamente se hayan eliminado. El número de observaciones es ahora 30,434.
Arreglando el tipo de datos
A menudo, en el conjunto de datos, los valores no se almacenan en el tipo de datos correcto. Esto puede crear un obstáculo en etapas posteriores y es factible que no obtengamos el resultado deseado o que obtengamos errores durante la ejecución. Un error de tipo de datos común es el de las fechas. Las fechas a menudo se analizan como objetos en Python. Hay un tipo de datos separado para las fechas en Pandas, llamado DateTime.
Primero verificaremos el tipo de datos de la columna de marca de tiempo en nuestros datos.
df.timestamp.dtype
Esto devuelve el tipo de datos ‘objeto’. Ahora sabemos que la marca de tiempo no se almacena correctamente. Para arreglar este problema, convierta la columna de marca de tiempo al formato DateTime.
# converting timestamp to datetime format df['timestamp'] = pd.to_datetime(df.timestamp, format="%Y-%m-%d")
Ahora tenemos la marca de tiempo en el formato correcto. De manera semejante, puede haber columnas donde los números enteros se almacenan como objetos. Es esencial identificar dichas características y corregir el tipo de datos antes de continuar con el aprendizaje automático. Por suerte para nosotros, no tenemos ningún problema de este tipo en nuestro conjunto de datos.
EndNote
En este post, discutimos algunas formas básicas en las que podemos limpiar datos en Python antes de comenzar con nuestro proyecto de aprendizaje automático. Necesitamos identificar y borrar los valores faltantes, identificar y tratar los valores atípicos, borrar los registros duplicados y corregir el tipo de datos de todas las columnas de nuestro conjunto de datos antes de continuar con nuestra tarea de AA.
El autor de este post es Vishesh Arora. Puedes conectarte conmigo en LinkedIn.
Los medios que se muestran en este post sobre el acreditación del lenguaje de señas no son propiedad de DataPeaker y se usan a discreción del autor.





