Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
¡Hola! Hoy haré todo lo posible para explicar de manera intuitiva cómo funcionan las redes neuronales convolucionales recurrentes (CRNN). Cuando intenté aprender por primera vez sobre cómo funciona CRNN, descubrí que la información estaba dividida entre varios sitios y que también estaban presentes diferentes niveles de «profundidad», por lo que intentaré explicarlos de una manera que al final de este artículo saber exactamente cómo funcionan y por qué se desempeñan mejor en algunas categorías que en otras.
En este artículo, asumiré que ya sabe un poco sobre cómo funciona una red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... simple. En caso de que necesites una pequeña revisión de cómo funciona o incluso si no sabes para nada cómo funcionan, te recomiendo que veas los videos bien hechos que explican cómo funcionan que enlacé al final del artículo. Proporcionaré toda la información que considere necesaria para comprender intuitivamente cómo funciona CRNN.
En este artículo cubriremos los siguientes temas, así que no dude en omitir los que ya conoce:
- ¿Qué son las redes neuronales convolucionales, cómo funcionan y por qué las necesitamos?
- ¿Qué son las redes neuronales recurrentes, cómo funcionan y por qué las necesitamos?
- · ¿Qué son y por qué necesitamos redes neuronales recurrentes convolucionales? + ejemplo de reconocimiento de texto escrito a mano
- · Más lecturas y enlaces
¿Qué son las redes neuronales convolucionales, cómo funcionan y por qué las necesitamos?
La más fácil de responder es la última pregunta, ¿por qué los necesitamos? Para eso, tomemos un ejemplo. Digamos que queremos descubrir si en la imagen tenemos un gato o un perro. Para simplificar la explicación, pensemos primero en una imagen de 3 × 3. En esta imagen, tenemos una característica importante en el rectángulo azul (como la cara de un perro, una letra o cualquiera que sea la característica importante).
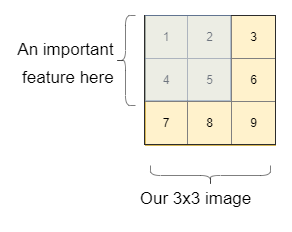
Veamos cómo una simple red neuronal reconocería la importancia y el vínculo entre los píxeles.
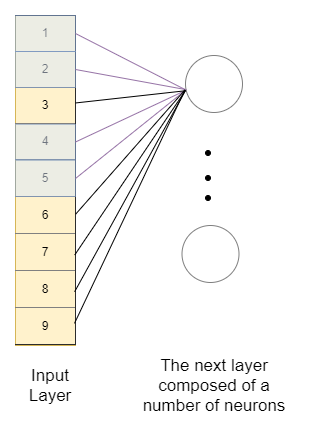
Como podemos ver, necesitaremos «aplanar» la imagen para alimentarla a una red neuronal densa. Al hacerlo, perdemos el contexto espacial en la imagen de la característica completa con el fondo y también las piezas de la característica entre sí. Imagínese lo difícil que será para la red neuronal aprender que están relacionados. Además, tendremos muchos pesos para entrenar, por lo que necesitaremos más datos y, por lo tanto, más tiempo para entrenarlos.
Entonces, podemos ver múltiples problemas con este enfoque:
- El contexto espacial se pierde
- Mucho más peso para imágenes más grandes
- Más pesos resultan en más tiempo y más datos necesarios
Solo si hubiera otra forma… ¡Espera! ¡Hay! Aquí es donde las redes neuronales convolucionales intervienen para salvar el día. Su función principal es extraer características relevantes de la entrada (una imagen, por ejemplo) mediante el uso de filtros. Estos filtros se eligen en primer lugar al azar y luego se entrenan como lo hacen los pesos. Son modificados por la Red Neural para extraer y encontrar las características más relevantes.
De acuerdo, establecimos hasta ahora que las redes neuronales convolucionales, que usaré como CNN, usan filtros para extraer características. Pero, ¿qué son exactamente los filtros y cómo funcionan?
Los filtros son matrices que contienen diferentes valores que se deslizan sobre la imagen (por ejemplo) para analizar las características. Si la matriz es, por ejemplo, 3x3x3, la característica extraída será de tamaño 3x3x3. Si la matriz es de tamaño 5 × 5, la característica que detectará tendrá un tamaño máximo de 5 × 5 en la imagen, y así sucesivamente. Al analizar una ventana de píxeles, entendemos la multiplicación por elementos entre el filtro y la ventana cubierta.
Entonces, por ejemplo, si tenemos una imagen con un tamaño de 6 × 6 y un filtro de 3 × 3, podemos imaginar el filtro deslizándose sobre la imagen, y cada vez que aterriza en una nueva ventana, la analiza, lo que podemos ver representado en la imagen de abajo, solo para las dos primeras filas de la imagen:
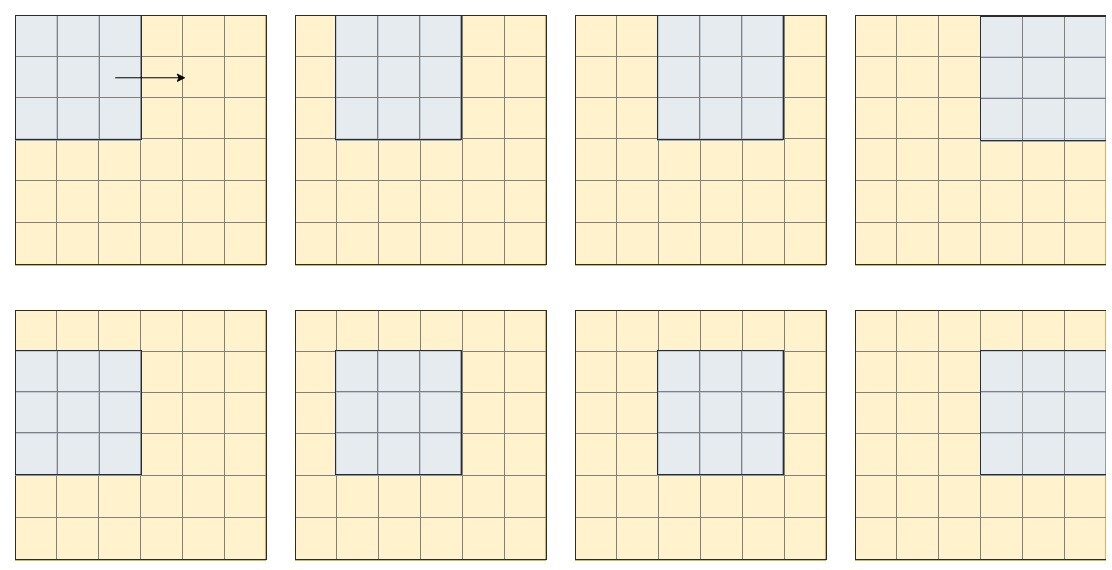
Dependiendo de lo que necesitemos extraer, podemos cambiar el paso del filtro (tanto vertical como horizontalmente, en el ejemplo anterior, el filtro da un paso en ambas direcciones).
Después de hacer la multiplicación (por elementos), el resultado se convierte en el nuevo píxel de la imagen. Entonces, después de «analizar» la primera ventana, obtenemos el primer píxel de nuestra imagen, y así sucesivamente. Vemos que en el caso presentado anteriormente, la imagen final tendrá un tamaño de 5 × 5. Para tener la imagen final con el mismo tamaño, podemos aplicar los filtros después de rellenar imaginariamente la imagen (agregando una fila y una columna imaginarias en la principio y final), pero los detalles quedan para otro momento para discutirlos.
Para ver aún mejor cómo funciona la convolución, podemos ver ejemplos de filtros y el efecto que causan en la imagen de salida:

Podemos ver cómo diferentes filtros detectan y «extraen» diferentes características. La función de entrenar una red neuronal de convolución es encontrar los mejores filtros para extraer la característica más relevante para nuestra tarea.
Entonces, para concluir la parte sobre las redes neuronales de convolución, podemos resumir la información en 3 ideas simples:
- Qué son: Las redes neuronales convolucionales son un tipo de redes neuronales que utilizan la operación de convolución (deslizando un filtro a través de una imagen) para extraer características relevantes.
- Por qué los necesitamos: funcionan mejor en datos (en lugar de usar redes neuronales densas normales) en los que existe una fuerte correlación entre, por ejemplo, píxeles porque el contexto espacial no se pierde.
- Cómo funcionan: utilizan filtros para extraer características. Los filtros son matrices que se “deslizan” sobre la imagen. Se modifican en el período de formación para extraer las características más relevantes.
¿Qué son las redes neuronales recurrentes, cómo funcionan y por qué las necesitamos?
Mientras que las redes neuronales convolucionales nos ayudan a extraer características relevantes en la imagen, las redes neuronales recurrentes ayudan a la red neuronal a tomar en consideración información del pasado para hacer predicciones o analizar.
Por lo tanto, si tenemos, por ejemplo, la siguiente matriz: {2, 4, 6}, y queremos predecir lo que vendrá después, podemos usar una Red neuronal recurrenteLas redes neuronales recurrentes (RNN) son un tipo de arquitectura de redes neuronales diseñadas para procesar secuencias de datos. A diferencia de las redes neuronales tradicionales, las RNN utilizan conexiones internas que permiten recordar información de entradas anteriores. Esto las hace especialmente útiles en tareas como el procesamiento de lenguaje natural, la traducción automática y el análisis de series temporales, donde el contexto y la secuencia son fundamentales para la..., porque, en cada paso, tomará en consideración lo que fue antes de eso.
Podemos visualizar una celda recurrente simple, como se muestra en la siguiente imagen:
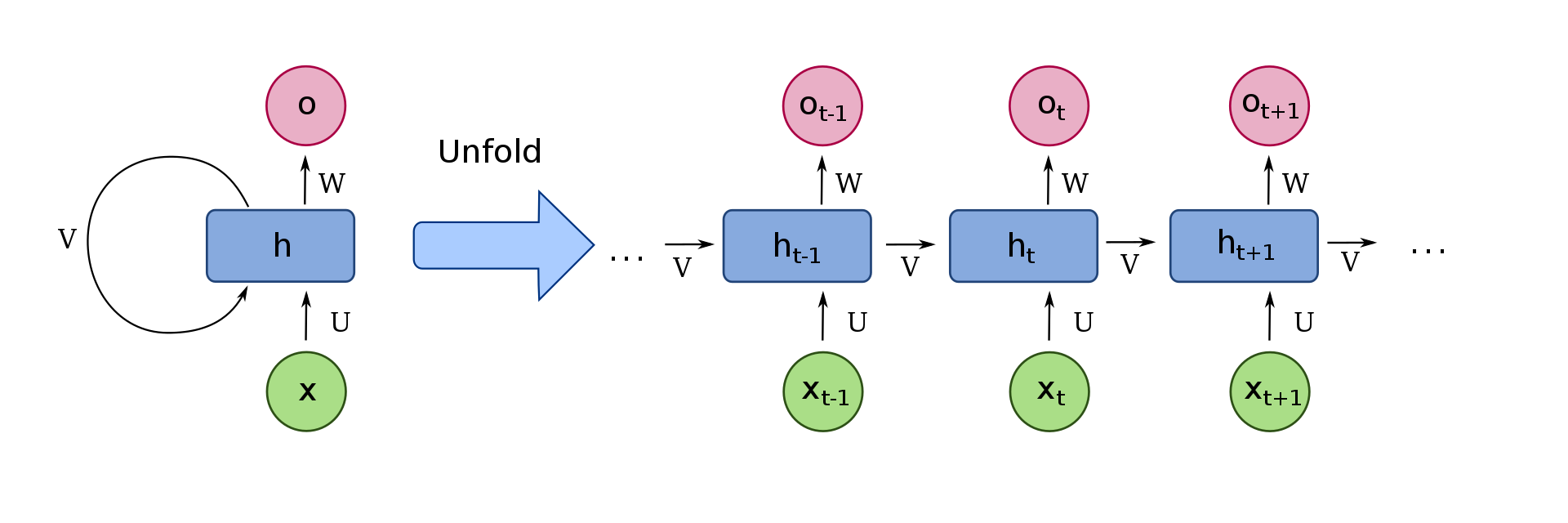
Primero, centrémonos solo en el lado derecho de la imagen. Aquí, xt son las entradas recibidas en el paso de tiempo t. Para seguir el mismo ejemplo, estos podrían ser los números de la matriz mencionada anteriormente, x0 = 2, x1 = 4, x2 = 6. Para tomar en consideración lo que era antes del paso de tiempo, la propiedad que los hace parte de una Red Neural Recurrente, tenemos que recibir información del paso de tiempo anterior, que en esta imagen hemos representado como v Cada celda tiene un llamado «estado», que contiene intuitivamente la información que luego se envía a la siguiente celda.
Entonces, para recapitular, xt es la entrada de la celda. Luego, la celda decide cuál es la información importante, teniendo en cuenta la información de los pasos de tiempo anteriores, recibida a través de la “v”, y la envía a la siguiente celda. Además, tenemos la opción si queremos devolver esta importante información que la celda consideró, a través de la «o» en la imagen, la salida de la celda.
Para representar el proceso mencionado anteriormente de una manera más compacta, podemos «plegar» las celdas, representadas en la parte izquierda de la imagen.
No entraremos en detalles sobre el tipo exacto de celdas recurrentes, ya que son muchas opciones, y explicar en detalle cómo funcionan nos llevaría demasiado tiempo. Si te interesa, dejé algunos enlaces que me parecieron muy útiles al final del artículo.
¿Qué son y por qué necesitamos redes neuronales recurrentes convolucionales?
+ ejemplo de reconocimiento de texto escrito a mano
Ahora tenemos toda la información importante para comprender cómo funciona una red recurrente convolucional.
La mayoría de las veces, la red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora... analiza la imagen y la envía a la parte recurrente de las características importantes detectadas. La parte recurrente analiza estas características en orden, teniendo en cuenta la información previa para darse cuenta de cuáles son algunos vínculos importantes entre estas características que influyen en la salida.
Para comprender un poco más sobre cómo funciona un CRNN en algunas tareas, tomemos como ejemplo el reconocimiento de texto escrito a mano.
Imaginemos que tenemos imágenes que contienen palabras y queremos entrenar la NNet para que nos dé qué palabra está inicialmente en la imagen.
En primer lugar, nos gustaría que nuestra red neuronal pudiera extraer características importantes para diferentes letras, como bucles de «g» o «l», o incluso círculos de «a» u «o». Para ello, podemos utilizar una red neuronal convolucional. Como se explicó anteriormente, CNN usa filtros para extraer las características importantes (vimos cómo diferentes filtros tienen diferentes efectos en la imagen inicial). Por supuesto, estos filtros detectarán en la práctica características más abstractas que realmente no podemos entender, pero intuitivamente podemos pensar en características más simples, como las mencionadas anteriormente.
Entonces, querríamos analizar estas características. Echemos un vistazo a por qué no podemos decidir qué letra se basa únicamente en sus propias características. En la imagen de abajo, vemos que la letra es “a” (de “aux”) u “o” (de for).
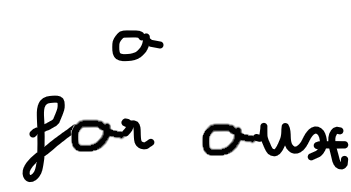
La diferencia radica en la forma en que la letra está vinculada a las otras letras. Entonces necesitaríamos saber información de lugares anteriores en la imagen para poder determinar la letra. ¿Suena familiar? Aquí es donde entra la parte RNN. Analiza de forma recursiva la información extraída por la CNN, donde la entrada para cada celda podrían ser las características detectadas en un segmento específico de la imagen, como se representa a continuación, con solo 10 segmentos (menos de lo que nosotros usaría en modelos reales):
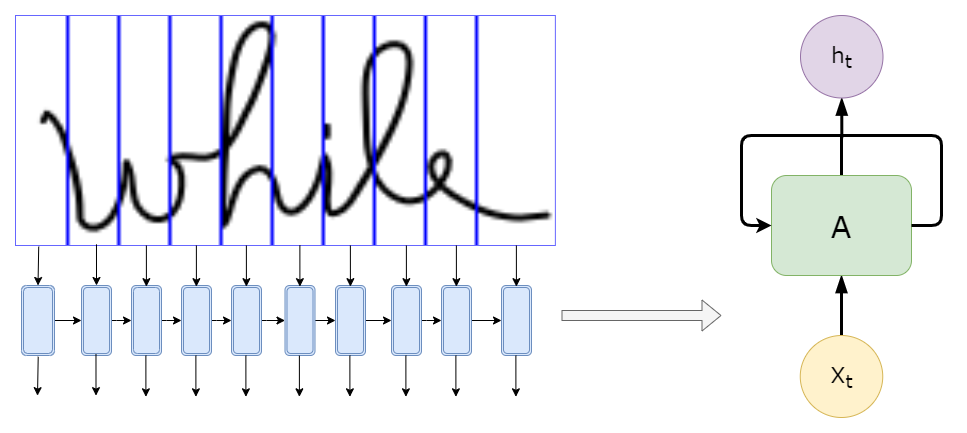
No alimentamos al RNN con la imagen en sí, como se muestra en la imagen de arriba, sino con las características extraídas de ese «segmento».
También podríamos ver que procesar la imagen hacia adelante es tan importante como procesar la imagen hacia atrás, por lo que podemos agregar una capa de celdas que procesen las características de la otra manera, teniendo en cuenta ambas al calcular la salida. O incluso verticalmente, dependiendo de la tarea a realizar.
¡Hurra! Finalmente tenemos la imagen analizada: las características extraídas y analizadas en relación entre sí. Todo lo que tenemos que hacer ahora es agregar una capa que calcule la pérdida y un algoritmo que decodifique la salida, para esto, es posible que deseemos usar una CTC (Clasificación temporal conexionista) para el reconocimiento de texto escrito a mano, pero ese es un tema interesante por sí solo. y creo que merece otro artículo.
Conclusiones
En este artículo, discutimos brevemente cómo funcionan las redes neuronales recurrentes convolucionales, cómo analizan y extraen características y un ejemplo de cómo podrían usarse.
La red neuronal convolucional extrae las características aplicando filtros relevantes y la red neuronal recurrente analiza estas características, teniendo en cuenta la información recibida de los pasos de tiempo anteriores.





