[*]
Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
Uno de los principales problemas que todos enfrentan cuando intentan por primera vez la transmisión estructurada es configurar el entorno necesario para transmitir sus datos. Tenemos algunos tutoriales en línea sobre cómo podemos configurar esto. La mayoría de ellos se enfocan en pedirle que instale una máquina virtual y un sistema operativo ubuntu y luego configure todos los archivos requeridos cambiando el archivo bash. Esto funciona bien, pero no para todos. Una vez que usamos una máquina virtual, a veces es posible que tengamos que esperar mucho si tenemos máquinas con menos memoria. El proceso podría atascarse debido a problemas de retraso de la memoria. Entonces, para una mejor manera de hacerlo y una operación fácil, le mostraré cómo podemos configurar la transmisión estructurada en nuestro sistema operativo Windows.
Herramientas utilizadas
Para la configuración usamos las siguientes herramientas:
1. Kafka (para la transmisión de datos, actúa como productor)
2. Guardián del zoológico
3. Pyspark (para generar los datos transmitidos, actúa como consumidor)
4. Jupyter Notebook (editor de código)
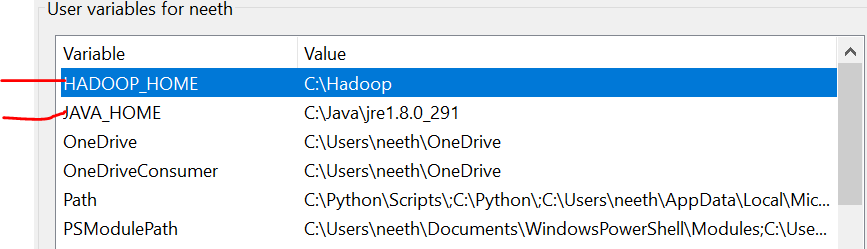
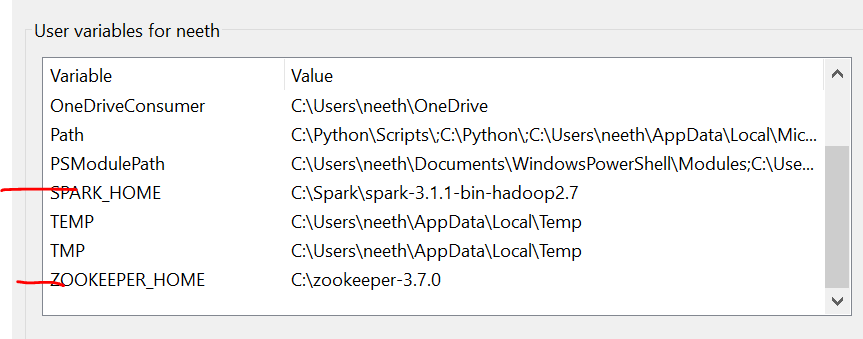
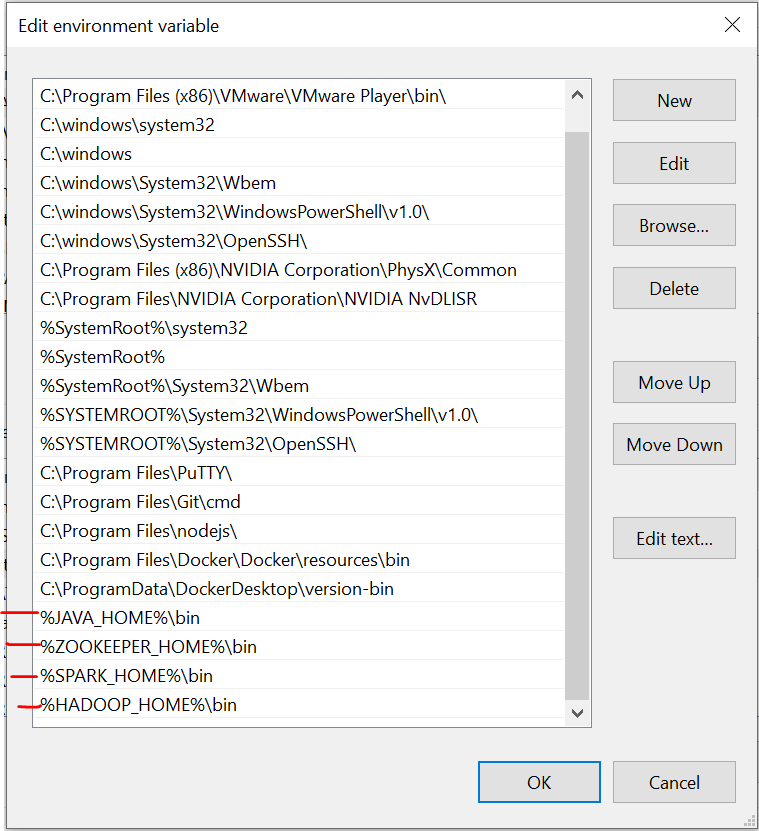
Variables de entorno
Es importante tener en cuenta que aquí, he agregado todos los archivos en la unidad C. Además, la denominación debe ser la misma que la de los archivos que instala en línea.
Tenemos que configurar las variables de entorno a medida que instalamos estos archivos. Consulte estas imágenes durante la instalación para disfrutar de una experiencia sin complicaciones.
La última imagen es la ruta de las variables del sistema.
Archivos requeridos
https://drive.google.com/drive/folders/1kOQAKgo98cPPYcvqpygyqNFIGjrK_bjw?usp=sharing
Instalación de Kafka
El primer paso es instalar Kafka en nuestro sistema. Para ello tenemos que ir a este enlace:
https://dzone.com/articles/running-apache-kafka-on-windows-os
Necesitamos instalar Java 8 inicialmente y configurar las variables de entorno. Puede obtener todas las instrucciones del enlace.
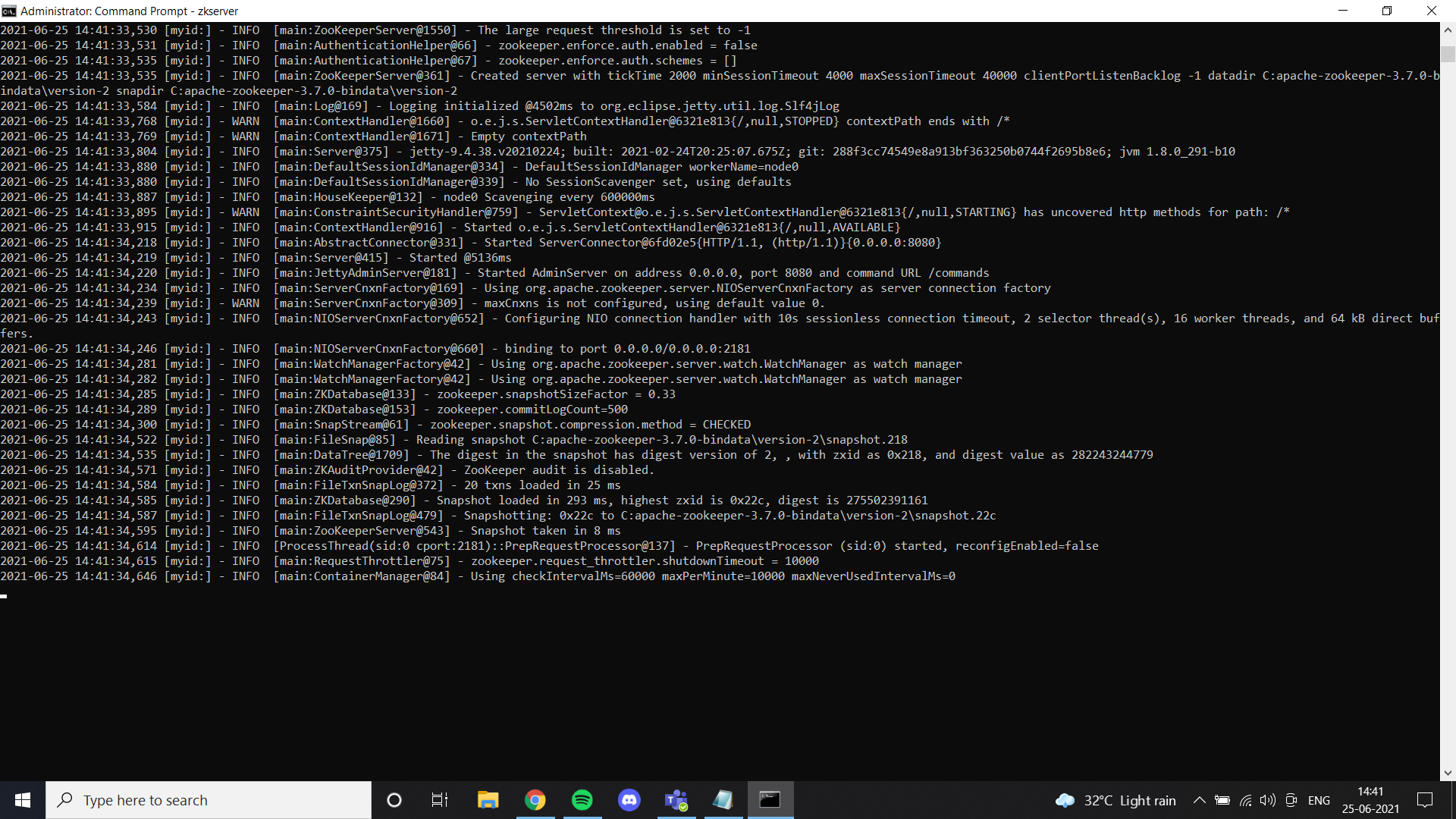
Una vez que hayamos terminado con Java, debemos instalar un guardián del zoológico. He agregado archivos de guardián del zoológico en Google Drive. Siéntase libre de usarlo o simplemente siga todas las instrucciones dadas en el enlace. Si instaló zookeeper"Zookeeper" es un videojuego de simulación lanzado en 2001, donde los jugadores asumen el rol de un cuidador de zoológico. La misión principal consiste en gestionar y cuidar diversas especies de animales, asegurando su bienestar y la satisfacción de los visitantes. A lo largo del juego, los usuarios pueden diseñar y personalizar su zoológico, enfrentando desafíos que incluyen la alimentación, el hábitat y la salud de los animales.... correctamente y configuró la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de entorno, puede ver este resultado cuando ejecute zkserver como administrador en el símbolo del sistema.
A continuación, instale Kafka según las instrucciones del enlace y ejecútelo con el comando especificado.
.binwindowskafka-server-start.bat .configserver.properties
Una vez que todo esté configurado, intente crear un tema y verifique si funciona correctamente. Si es así, habrá completado la instalación de Kafka.
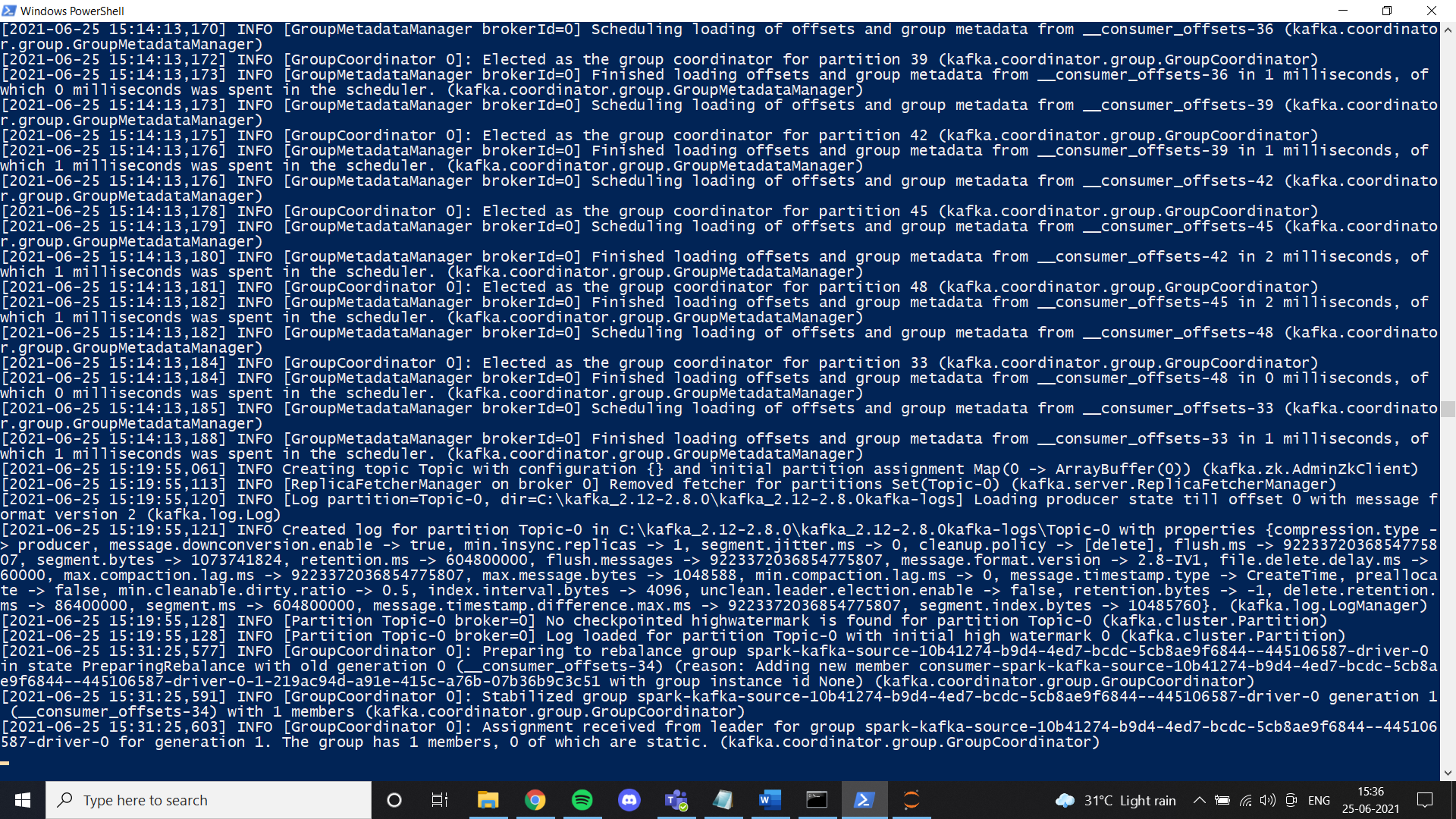
Instalación de Spark
En este paso, instalamos Spark. Básicamente, puede seguir este enlace para configurar Spark en su máquina con Windows.
https://phoenixnap.com/kb/install-spark-on-windows-10
Durante uno de los pasos, pedirá que se configure el archivo winutils. Para su comodidad, agregué el archivo en el enlace de la unidad que compartí. En una carpeta llamada Hadoop. Simplemente coloque esa carpeta en su unidad C y configure la variable de entorno como se muestra en las imágenes. Te recomiendo encarecidamente que uses el archivo Spark que he agregado a Google Drive. Una de las razones principales es la transmisión de datos que necesitamos para configurar manualmente un entorno de transmisión estructurado. En nuestro caso, configuré todas las cosas necesarias y modifiqué los archivos después de probar mucho. En caso de que desee realizar una nueva configuración, no dude en hacerlo. Si la configuración no funciona correctamente, terminamos con un error como este al transmitir datos en pyspark:
Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".;Una vez que somos uno con Spark, ahora podemos transmitir los datos requeridos desde un archivo CSV en un productor y obtenerlos en un consumidor usando el tema de Kafka. Principalmente trabajo con el cuaderno Jupiter y, por lo tanto, he usado un cuaderno para este tutorial.
En su cuaderno primero, debe instalar algunas bibliotecas:
1. pip instalar pyspark
2. pip instalar Kafka
3. pip instalar py4j
¿Cómo funciona la transmisión estructurada con Pyspark?
Tenemos un archivo CSV que tiene datos que queremos transmitir. Procedamos con el conjunto de datos clásico de Iris. Ahora, si queremos transmitir los datos del iris, debemos usar Kafka como productor. Kafka, creamos un tema al que transmitimos los datos del iris y el consumidor puede recuperar el marco de datos de este tema.
El siguiente es el código de productor para transmitir datos de iris:
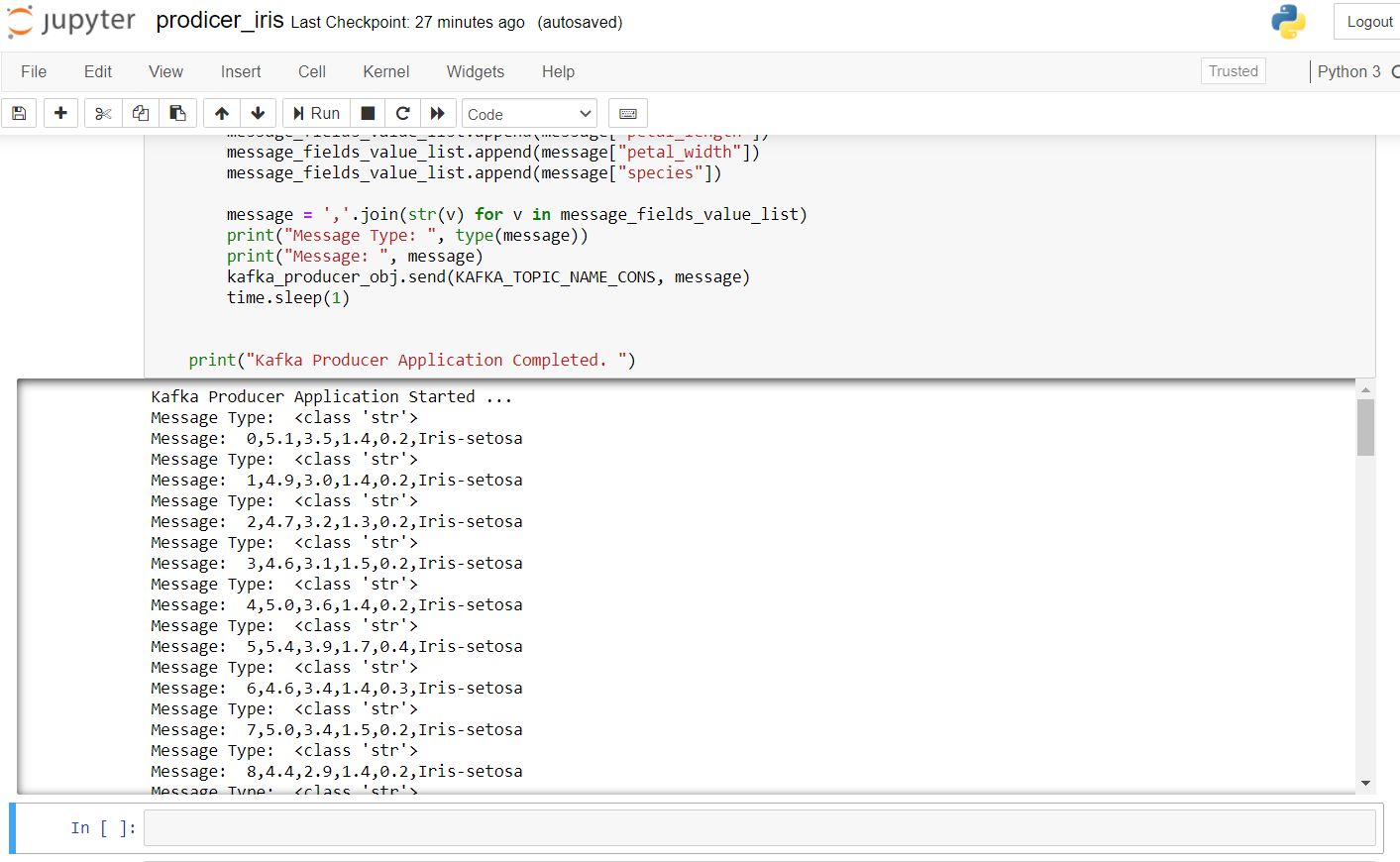
Para iniciar el productor, tenemos que ejecutar zkserver como administrador en el símbolo del sistema de Windows y luego iniciar Kafka usando: .binwindowskafka-server-start.bat .configserver.properties desde el símbolo del sistema en el directorio de Kafka. Si obtiene un error de «no broker», significa que Kafka no se está ejecutando correctamente.
El resultado después de ejecutar este código en el cuaderno jupyter se ve así:
Ahora, revisemos al consumidor. Ejecute el siguiente código para ver si funciona bien en un nuevo portátil.
Una vez que ejecute esto, debería obtener un resultado como este:
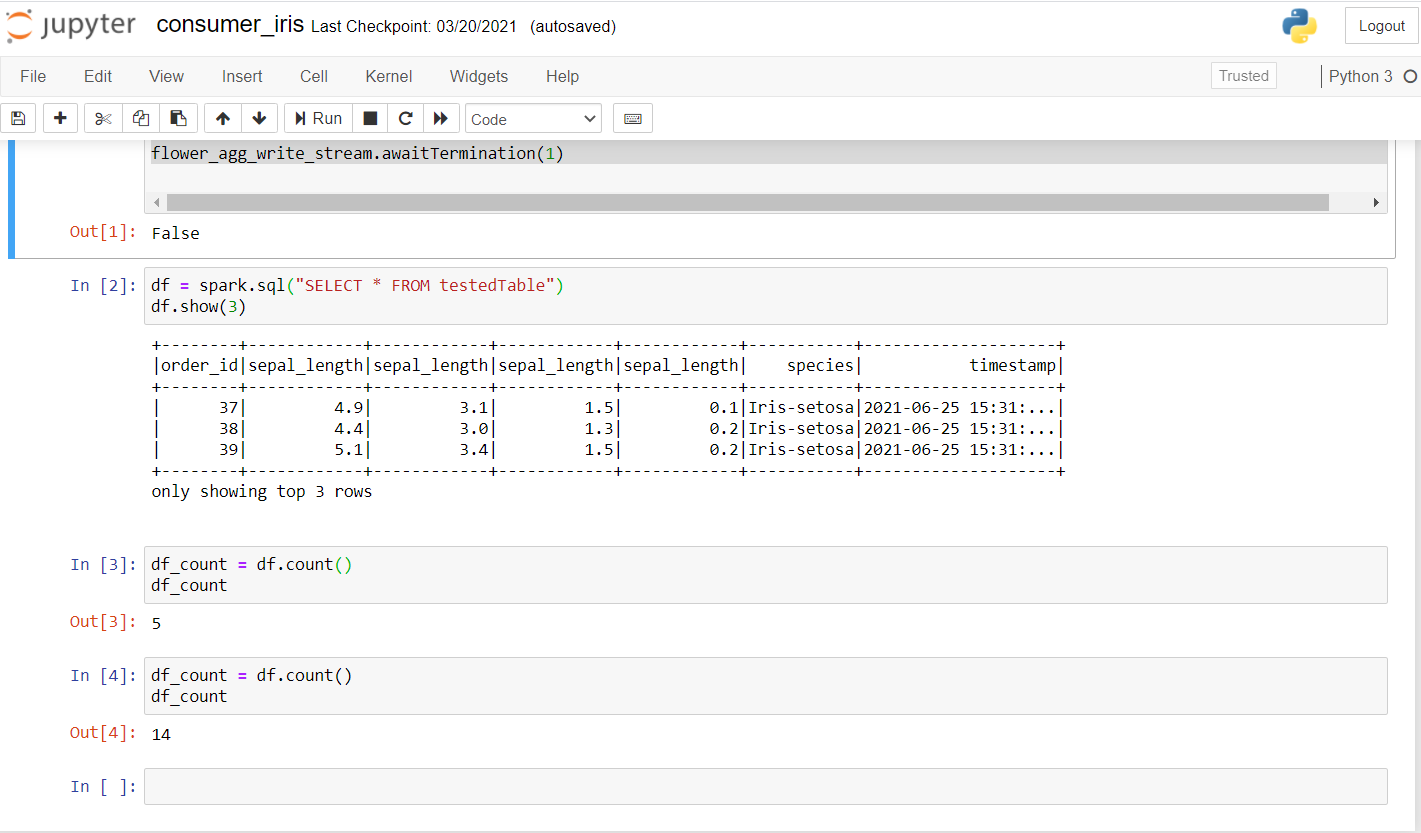
Como puede ver, realicé algunas consultas y verifiqué si los datos se estaban transmitiendo. La primera cuenta fue de 5 y, después de unos segundos, la cuenta aumentó a 14, lo que confirma que los datos se están transmitiendo.
Aquí, básicamente, la idea es crear un contexto de chispa. Obtenemos los datos mediante la transmisión de Kafka en nuestro tema en el puerto especificado. Se puede crear una sesiónLa "Sesión" es un concepto clave en el ámbito de la psicología y la terapia. Se refiere a un encuentro programado entre un terapeuta y un cliente, donde se exploran pensamientos, emociones y comportamientos. Estas sesiones pueden variar en duración y frecuencia, y su objetivo principal es facilitar el crecimiento personal y la resolución de problemas. La efectividad de las sesiones depende de la relación entre el terapeuta y el... de chispa usando getOrCreate () como se muestra en el código. El siguiente paso incluye leer el flujo de Kafka y los datos se pueden cargar usando load (). Dado que los datos se están transmitiendo, sería útil tener una marca de tiempo en la que ha llegado cada uno de los registros. Especificamos el esquema como lo hacemos en nuestro SQL y finalmente creamos un marco de datos con los valores de los datos transmitidos con su marca de tiempo. Por fin, con un tiempo de procesamiento de 5 segundos, podemos recibir datos en lotes. Hacemos uso de SQL View para almacenar temporalmente los datos en la memoria en modo adjunto y podemos realizar todas las operaciones en él usando nuestro marco de datos Spark.
Consulte el código completo aquí:
https://github.com/Siddharth1698/Structured-Streaming-Tutorial
Este es uno de mis proyectos de transmisión de Spark, puede consultarlo para obtener consultas más detalladas y el uso del aprendizaje automático en Spark:
https://github.com/Siddharth1698/Spotify-Recommendation-System-using-Pyspark-and-Kafka
Referencias
1. https://github.com/Siddharth1698/Structured-Streaming-Tutorial
2. https://dzone.com/articles/running-apache-kafka-on-windows-os
3. https://phoenixnap.com/kb/install-spark-on-windows-10
4. https://drive.google.com/drive/u/0/folders/1kOQAKgo98cPPYcvqpygyqNFIGjrK_bjw
5. https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
6. Imagen en miniatura -> https://unsplash.com/photos/ImcUkZ72oUs
Conclusión
Si sigue estos pasos, puede configurar fácilmente todos los entornos y ejecutar su primer programa de transmisión estructurado con Spark y Kafka. En caso de cualquier dificultad para configurarlo, no dude en ponerse en contacto conmigo:
[email protected]
https://www.linkedin.com/in/siddharth-m-426a9614a/





