- Aprenda a construir un modelo de árbol de decisiones con Weka
- Este tutorial es perfecto para los recién llegados al aprendizaje automático y los árboles de decisión, y para aquellas personas que no se sienten cómodas con la codificación.
Introducción
«Cuanto mayor es el obstáculo, más gloria se obtiene al superarlo».
– Moliere
El aprendizaje automático puede resultar intimidante para las personas que no tienen conocimientos técnicos. Todos los trabajos de aprendizaje automático parecen requerir una comprensión sana de Python (o R).
Entonces, ¿cómo obtienen los no programadores experiencia en codificación? ¡No es un juego de niños!

Estas son las buenas noticias: existen muchas herramientas que nos permiten realizar tareas de aprendizaje automático sin tener que codificar. Puede crear fácilmente algoritmos como árboles de decisión desde cero en una hermosa interfaz gráfica. ¿No es ese el sueño? Estas herramientas, como Weka, nos ayudan principalmente a lidiar con dos cosas:
- Cree rápidamente un modelo de aprendizaje automático, como un árbol de decisiones, y comprenda cómo se está desempeñando el algoritmo. Esto puede modificarse más tarde y basarse en
- Esto es ideal para mostrarle al cliente / su equipo de liderazgo con qué está trabajando
¡Este artículo le mostrará cómo resolver problemas de clasificación y regresión utilizando árboles de decisión en Weka sin ningún conocimiento previo de programación!
Pero si te apasiona ensuciarte las manos con la programación y el aprendizaje automático, te sugiero que sigas los siguientes cursos maravillosamente seleccionados:
Tabla de contenido
- Clasificación frente a regresión en el aprendizaje automático
- Comprensión de los árboles de decisión
- Explorando el conjunto de datos en Weka
- Clasificación mediante el árbol de decisiones en Weka
- ParámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... del árbol de decisión en Weka
- Visualización de un árbol de decisiones en Weka
- Regresión usando el árbol de decisión en Weka
Clasificación frente a regresión en el aprendizaje automático
Permítanme primero resumir rápidamente qué son la clasificación y la regresión en el contexto de aprendizaje automático. Es importante conocer estos conceptos antes de sumergirse en los árboles de decisiones.
A clasificación problema se trata de enseñarle a su modelo de aprendizaje automático cómo categorizar un valor de datos en una de muchas clases. Lo hace aprendiendo las características de cada tipo de clase. Por ejemplo, para predecir si una imagen es de un gato o un perro, el modelo aprende las características del perro y el gato en los datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.....
A regresión problema se trata de enseñarle a su modelo de aprendizaje automático cómo predecir el valor futuro de una cantidad continua. Lo hace aprendiendo el patrón de la cantidad en el pasado afectada por diferentes variables. Por ejemplo, un modelo que intenta predecir el precio futuro de las acciones de una empresa es un problema de regresión.
Puede encontrar estos dos problemas en abundancia en nuestro Plataforma DataHack.
Ahora, aprendamos sobre un algoritmo que resuelve ambos problemas: ¡árboles de decisión!
Comprensión de los árboles de decisión
Árboles de decisión también se conocen como Árboles de clasificación y regresión (CART). Trabajan aprendiendo respuestas a una jerarquía de preguntas si / si no que conducen a una decisión. Estas preguntas forman una estructura en forma de árbol, y de ahí el nombre.
Por ejemplo, digamos que queremos predecir si una persona pedirá comida o no. Podemos visualizar el siguiente árbol de decisiones para esto:
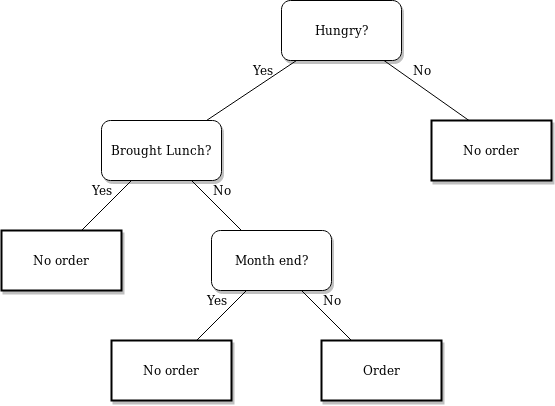
Cada nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... del árbol representa una pregunta derivada de las características presentes en su conjunto de datos. Su conjunto de datos se divide en función de estas preguntas hasta que se alcanza la profundidad máxima del árbol. El último nodo no hace una pregunta, sino que representa a qué clase pertenece el valor.
- El nodo superior del árbol de decisiones se denomina Rnodo oot
- El nodo más inferior se llama Leaf nodo
- Un nodo dividido en subnodos se llama Nodo padre. Los subnodos se denominan Nodos secundarios
Si desea comprender los árboles de decisión en detalle, le sugiero que consulte los siguientes recursos:
¿Qué es Weka? ¿Por qué debería utilizar Weka para el aprendizaje automático?
«Weka es un software gratuito de código abierto con una gama de algoritmos de aprendizaje automático integrados a los que puede acceder a través de una interfaz gráfica de usuario. «
WEKA representa Entorno de Waikato para el análisis del conocimiento y fue desarrollado en la Universidad de Waikato, Nueva Zelanda.
Weka tiene múltiples funciones integradas para implementar una amplia gama de algoritmos de aprendizaje automático, desde la regresión lineal hasta la red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas.... ¡Esto le permite implementar los algoritmos más complejos en su conjunto de datos con solo hacer clic en un botón! ¡No solo esto, Weka brinda soporte para acceder a algunos de los algoritmos de biblioteca de aprendizaje automático más comunes de Python y R!
Con Weka puede preprocesar los datos, clasificarlos, agruparlos e incluso visualizarlos. Esto lo puede hacer en diferentes formatos de archivos de datos como ARFF, CSV, C4.5 y JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software.... Weka incluso le permite agregar filtros a su conjunto de datos a través de los cuales puede normalizar sus datos, estandarizarlos, intercambiar funciones entre valores nominales y numéricos, ¡y mucho más!
Podría continuar sobre la maravilla que es Weka, pero para el alcance de este artículo, intentemos explorar Weka de manera práctica mediante la creación de un árbol de decisiones. Ahora sigue adelante y descarga Weka desde su página web oficial!
![]()
Explorando el conjunto de datos en Weka
Tomaré el conjunto de datos de cáncer de mama del Repositorio de aprendizaje automático de la UCI. Te recomiendo que leas sobre el problema antes de seguir adelante.
Primero carguemos el conjunto de datos en Weka. Para hacer eso, siga los pasos a continuación:
- Abrir la GUI de Weka
- Selecciona el «Explorador» opción.
- Seleccione «Abrir documento» y elija su conjunto de datos.
Su ventana de Weka ahora debería verse así:
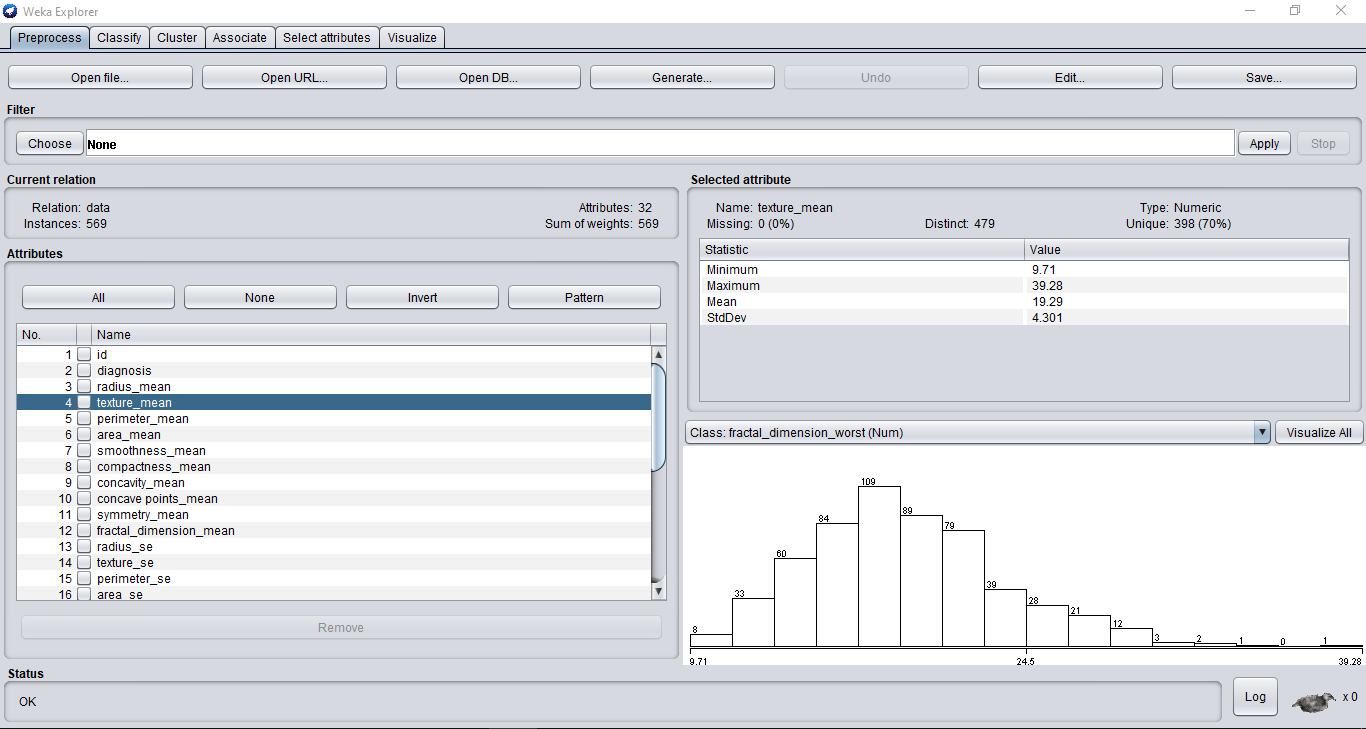
Puede ver todas las funciones de su conjunto de datos en el lado izquierdo. Weka crea automáticamente gráficos para sus características que notará a medida que navega por sus características.
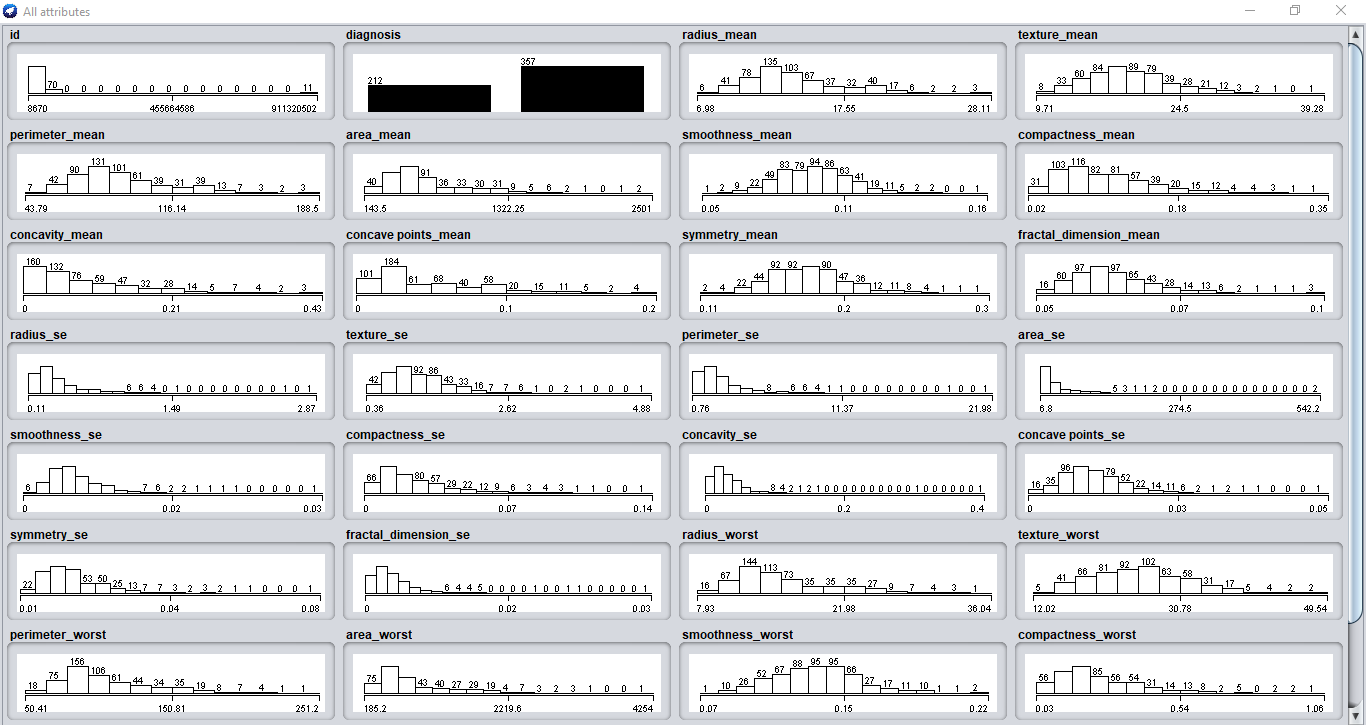
Incluso puede ver todas las parcelas juntas si hace clic en el «Visualizar todo» botón.
¡Ahora entrenemos nuestro modelo de clasificación!
Clasificación usando Árbol de decisión en Weka
Implementar un árbol de decisiones en Weka es bastante sencillo. Simplemente complete los siguientes pasos:
- Clickea en el «Clasificar» pestaña en la parte superior
- Haga clic en el «Escoger» botón
- En la lista desplegable, seleccione «árboles» que abrirá todos los algoritmos del árbol
- Finalmente, seleccione el «RepTree» árbol de decisión
”Árbol de poda de error reducido (RepTree) es un aprendiz de árbol de decisión rápido que construye un árbol de decisión / regresión usando ganancia de información como criterio de división y lo poda utilizando un algoritmo de poda de error reducido «.

«El árbol de decisión divide los nodos en todas las variables disponibles y luego selecciona la división que da como resultado los subnodos más homogéneos».
La ganancia de información se utiliza para calcular la homogeneidad de la muestra en una división.
Puede seleccionar su función de destino en el menú desplegable justo encima del «Comienzo» botón. Si no lo hace, WEKA selecciona automáticamente la última función como objetivo para usted.
los «División porcentual» especifica la cantidad de datos que desea conservar para entrenar al clasificador. El resto de los datos se utiliza durante la fase de prueba para calcular la precisión del modelo.
Con «Plegado de validación cruzada» puede crear varias muestras (o pliegues) a partir del conjunto de datos de entrenamiento. Si decide crear N pliegues, el modelo se ejecuta iterativamente N veces. Y cada vez que uno de los pliegues se retiene para su validación, mientras que los pliegues N-1 restantes se utilizan para entrenar el modelo. El resultado de todos los pliegues se promedia para obtener el resultado de la validación cruzada.
Cuanto mayor sea el número de pliegues de validación cruzada que utilice, mejor será su modelo. Esto hace que el modelo se entrene con datos seleccionados al azar, lo que lo hace más robusto.
Finalmente, presione el «Comienzo» ¡Botón para que el clasificador haga su magia!

Nuestro clasificador tiene una precisión del 92,4%. Weka incluso imprime el Matriz de confusión para ti, lo que ofrece diferentes métricas. Puede estudiar en detalle la matriz de confusión y otras métricas aquí.
Parámetros del árbol de decisión en Weka
Los árboles de decisión tienen muchos parámetros. Podemos ajustarlos para mejorar el rendimiento general de nuestro modelo. Aquí es donde el conocimiento práctico de los árboles de decisión realmente juega un papel crucial.
Puede acceder a estos parámetros haciendo clic en el algoritmo de su árbol de decisiones en la parte superior:

Hablemos brevemente de los principales parámetros:
- máxima profundidad – Determina la profundidad máxima de su árbol de decisiones. De forma predeterminada, es -1, lo que significa que el algoritmo controlará automáticamente la profundidad. Pero puede modificar manualmente este valor para obtener los mejores resultados en sus datos.
- no poda – Poda significa reducir automáticamente un nodo de hoja que no contiene mucha información. Esto hace que el árbol de decisiones sea simple y fácil de interpretar.
- numFolds – El número especificado de pliegues de datos se utilizará para podar el árbol de decisiones. El resto se utilizará para hacer crecer las reglas.
- minNum – Número mínimo de instancias por hoja. Si no se menciona, el árbol seguirá dividiéndose hasta que todos los nodos hoja tengan solo una clase asociada.
Siempre puede experimentar con diferentes valores para estos parámetros para obtener la mejor precisión en su conjunto de datos.
Visualización de su árbol de decisiones en Weka
Weka incluso le permite visualizar fácilmente el árbol de decisiones construido en su conjunto de datos:
- Ve a la «Lista de resultados» sección y haga clic derecho en su algoritmo entrenado
- Elegir el «Visualizar árbol» opción

Su árbol de decisiones se verá a continuación:

Interpretar estos valores puede ser un poco intimidante, pero en realidad es bastante fácil una vez que lo dominas.
- Los valores de las líneas que unen los nodos representan los criterios de división basados en los valores de la función del nodo principal.
- En el nodo hoja:
- El valor antes del paréntesis denota el valor de clasificación.
- El primer valor en el primer paréntesis es el número total de instancias del conjunto de entrenamiento en esa hoja. El segundo valor es el número de instancias clasificadas incorrectamente en esa hoja.
- El primer valor en el segundo paréntesis es el número total de instancias del conjunto de poda en esa hoja. El segundo valor es el número de instancias clasificadas incorrectamente en esa hoja.
Regresión usando el árbol de decisión en Weka
Como dije antes, los árboles de decisión son tan versátiles que pueden funcionar tanto en la clasificación como en los problemas de regresión. Para esto, usaré el «Predecir el número de votos a favor«Problema de Plataforma DataHack de DataPeaker.
Aquí, necesitamos predecir la calificación de una pregunta hecha por un usuario en una plataforma de preguntas y respuestas.
Como de costumbre, comenzaremos cargando el archivo de datos. Pero esta vez, los datos también contienen un «IDENTIFICACIÓN» columna para cada usuario en el conjunto de datos. Esto no sería útil en la predicción. Entonces, eliminaremos esta columna seleccionando el «Eliminar» opción debajo de los nombres de las columnas:

Podemos hacer predicciones sobre el conjunto de datos como lo hicimos para el Problema de cáncer de mama. RepTree detectará automáticamente el problema de regresión:

La métrica de evaluación proporcionada en el hackathon es la puntuación RMSE. Podemos ver que el modelo tiene un RMSE muy pobre sin ninguna ingeniería de características. Aquí es donde interviene: ¡adelante, experimente y mejore el modelo final!
Notas finales
Y así, ¡ha creado un modelo de árbol de decisión sin tener que hacer ninguna programación! Esto será de gran ayuda en su búsqueda para dominar el funcionamiento de los modelos de aprendizaje automático.
Si desea aprender y explorar la parte de programación del aprendizaje automático, le sugiero que siga estos cursos maravillosamente seleccionados sobre el Analítica Vidhya sitio web:





