Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
Gradient Descent es uno de los algoritmos de aprendizaje automático más utilizados en la industria. Y, sin embargo, confunde a muchos recién llegados.
¡Lo entiendo! La matemática detrás del aumento de gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en... no es fácil si recién está comenzando. Mi objetivo es ayudarlo a obtener una intuición detrás del descenso de gradientes en este artículo.

Comprenderemos rápidamente el papel de una función de costo, la explicación del descenso de gradiente, cómo elegir el parámetro de aprendizaje y el efecto de sobrepasar en el descenso de gradiente. ¡Vamos a empezar!
¿Qué es una función de costo?
Es un función que mide el rendimiento de un modelo para cualquier dato dado. Función de costo cuantifica el error entre los valores predichos y los valores esperados y lo presenta en forma de un solo número real.
Luego de realizar una hipótesis con parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... iniciales, calculamos la función Costo. Y con el objetivo de reducir la función de costo, modificamos los parámetros utilizando el algoritmo de descenso de gradiente sobre los datos dados. Aquí está la representación matemática para ello:
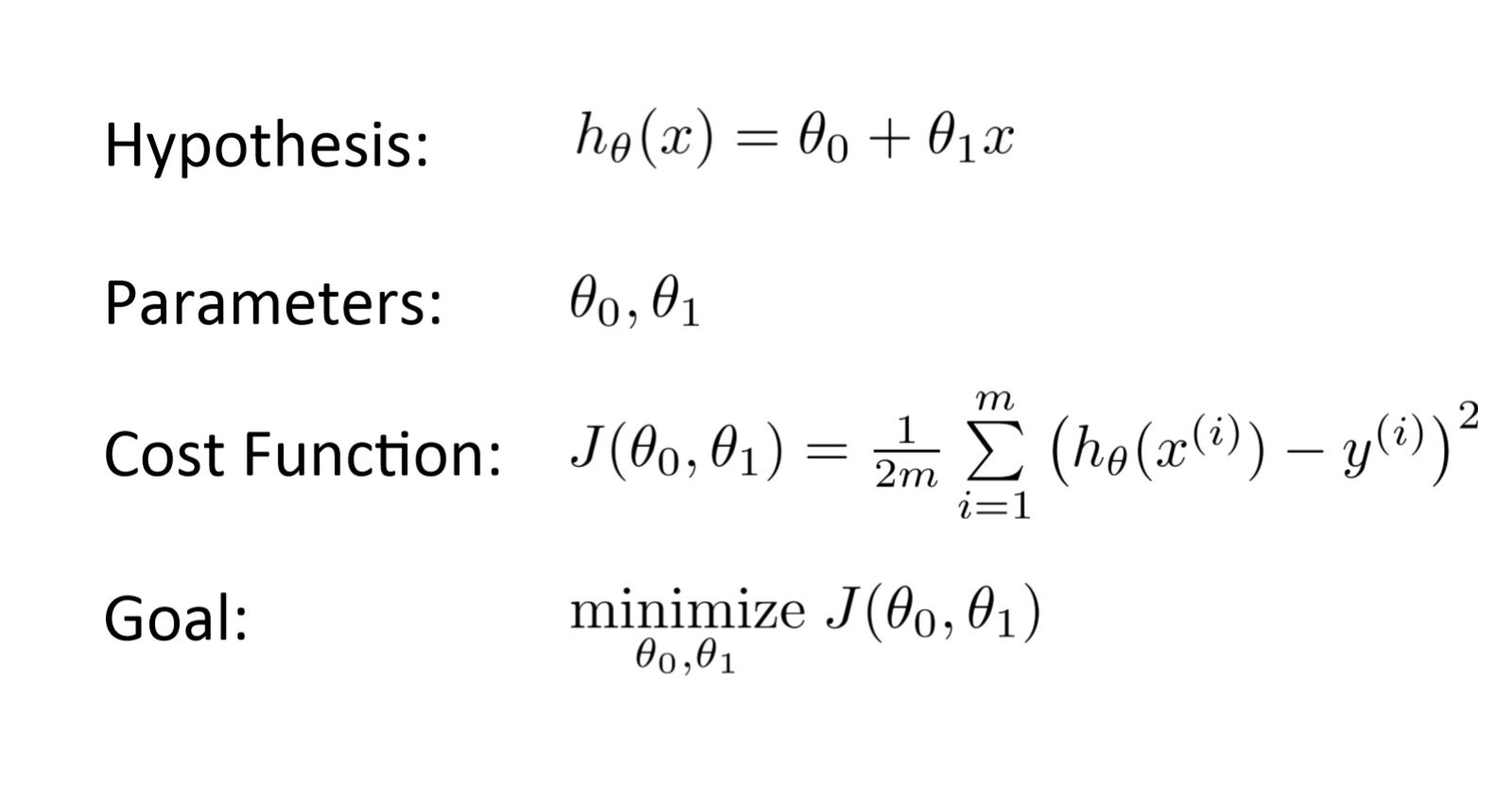
¿Qué es Gradient Descent?
¡La pregunta del millón de dólares!
Digamos que estás jugando un juego en el que los jugadores están en la cima de una montaña y se les pide que lleguen al punto más bajo de la montaña. Además, tienen los ojos vendados. Entonces, ¿qué enfoque crees que te haría llegar al lago?
Tómate un momento para pensar en esto antes de seguir leyendo.
La mejor manera es observar el suelo y encontrar dónde desciende la tierra. Desde esa posición, da un paso en dirección descendente e itera este proceso hasta llegar al punto más bajo.
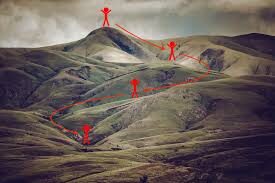 Encontrar el punto más bajo en un paisaje montañoso. (Fuente: Fisseha Berhane)
Encontrar el punto más bajo en un paisaje montañoso. (Fuente: Fisseha Berhane)El descenso de gradiente es un algoritmo de optimizaciónUn algoritmo de optimización es un conjunto de reglas y procedimientos diseñados para encontrar la mejor solución a un problema específico, maximizando o minimizando una función objetivo. Estos algoritmos son fundamentales en diversas áreas, como la ingeniería, la economía y la inteligencia artificial, donde se busca mejorar la eficiencia y reducir costos. Existen múltiples enfoques, incluyendo algoritmos genéticos, programación lineal y métodos de optimización combinatoria.... iterativo para encontrar el mínimo local de una función.
Para encontrar el mínimo local de una función usando el descenso de gradiente, debemos dar pasos proporcionales al negativo del gradiente (alejarse del gradiente) de la función en el punto actual. Si damos pasos proporcionales al positivo del gradiente (moviéndonos hacia el gradiente), nos acercaremos a un máximo local de la función, y el procedimiento se llama Ascenso en gradiente.
El descenso de gradiente fue propuesto originalmente por CAUCHY en 1847. También se conoce como descenso más empinado.
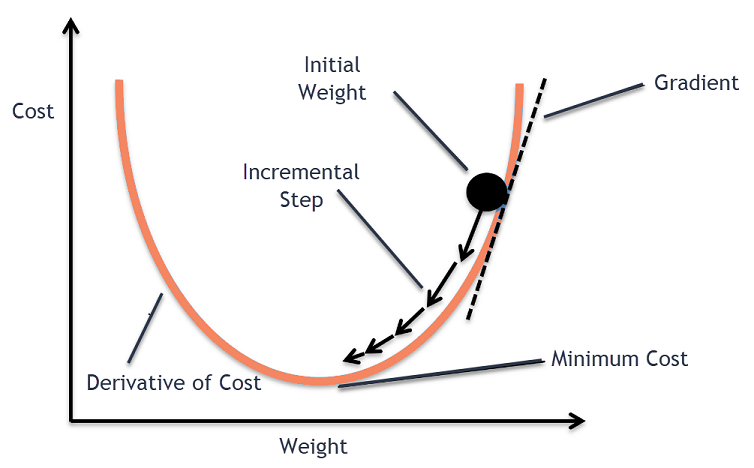
El objetivo del algoritmo de descenso de gradiente es minimizar la función dada (por ejemplo, función de costo). Para lograr este objetivo, realiza dos pasos de forma iterativa:
- Calcule el gradiente (pendiente), la derivada de primer orden de la función en ese punto
- Da un paso (muévete) en la dirección opuesta al degradado, la dirección opuesta de la pendiente aumenta desde el punto actual en alfa veces el gradiente en ese punto

Alpha se llama Tasa de aprendizaje – un parámetro de ajuste en el proceso de optimización. Decide la longitud de los pasos.
Trazado del algoritmo de descenso de gradiente
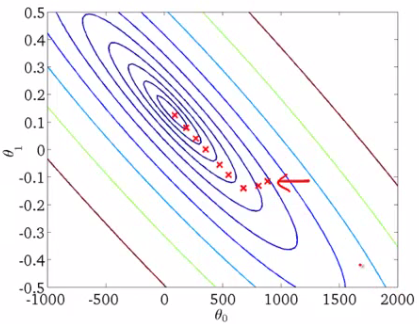
Cuando tenemos un solo parámetro (theta), podemos graficar el costo de la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... dependiente en el eje y y theta en el eje x. Si hay dos parámetros, podemos optar por una gráfica en 3-D, con el costo en un eje y los dos parámetros (thetas) a lo largo de los otros dos ejes.
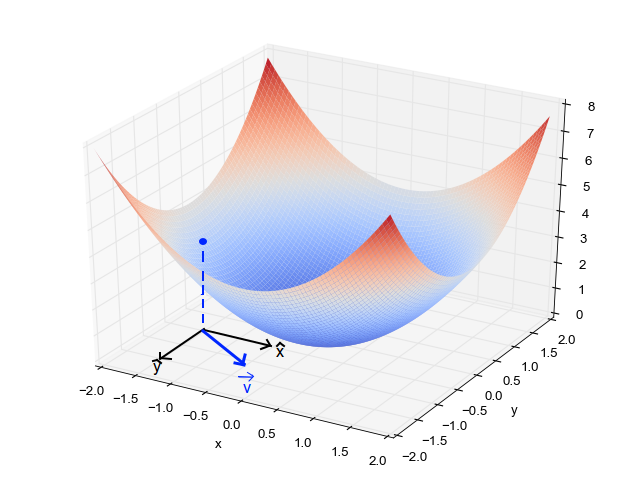
También se puede visualizar usando Contornos. Esto muestra una gráfica 3D en dos dimensiones con parámetros a lo largo de ambos ejes y la respuesta como un contorno. El valor de la respuesta aumenta alejándose del centro y tiene el mismo valor junto con los anillos. La respuesta es directamente proporcional a la distancia de un punto al centro (a lo largo de una dirección).
Alpha – La tasa de aprendizaje
Tenemos la dirección en la que queremos movernos, ahora debemos decidir el tamaño del paso que debemos dar.
* Debe elegirse con cuidado para terminar con mínimos locales.
- Si la tasa de aprendizaje es demasiado alta, podríamos EXCEDERSE los mínimos y seguir rebotando, sin llegar a los mínimos
- Si la tasa de aprendizaje es demasiado pequeña, la capacitación puede resultar demasiado larga.
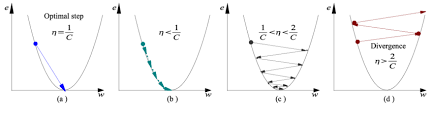
- a) La tasa de aprendizaje es óptima, el modelo converge al mínimo
- b) La tasa de aprendizaje es demasiado pequeña, lleva más tiempo pero converge al mínimo
- c) La tasa de aprendizaje es mayor que el valor óptimo, se sobrepasa pero converge (1 / C <η <2 / C)
- d) La tasa de aprendizaje es muy grande, se sobrepasa y diverge, se aleja de los mínimos, el rendimiento disminuye en el aprendizaje
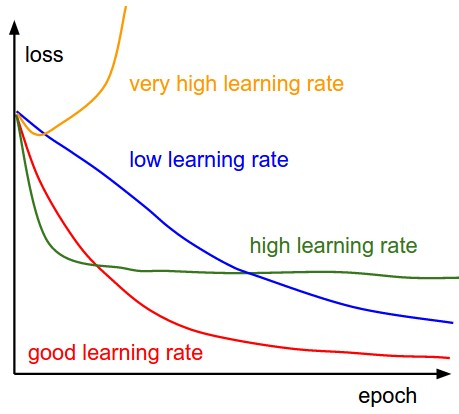
Nota: A medida que el gradiente disminuye mientras se mueve hacia los mínimos locales, el tamaño del paso disminuye. Por lo tanto, la tasa de aprendizaje (alfa) puede ser constante durante la optimización y no es necesario variar de forma iterativa.
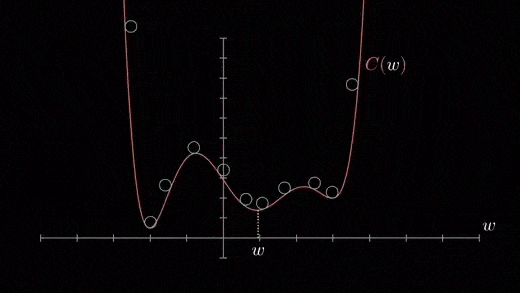
Mínimos locales
La función de costo puede constar de muchos puntos mínimos. El gradiente puede asentarse en cualquiera de los mínimos, que depende del punto inicial (es decir, los parámetros iniciales (theta)) y la tasa de aprendizaje. Por lo tanto, la optimización puede converger en diferentes puntos con diferentes puntos de partida y tasa de aprendizaje.
Implementación de código de Gradient Descent en Python
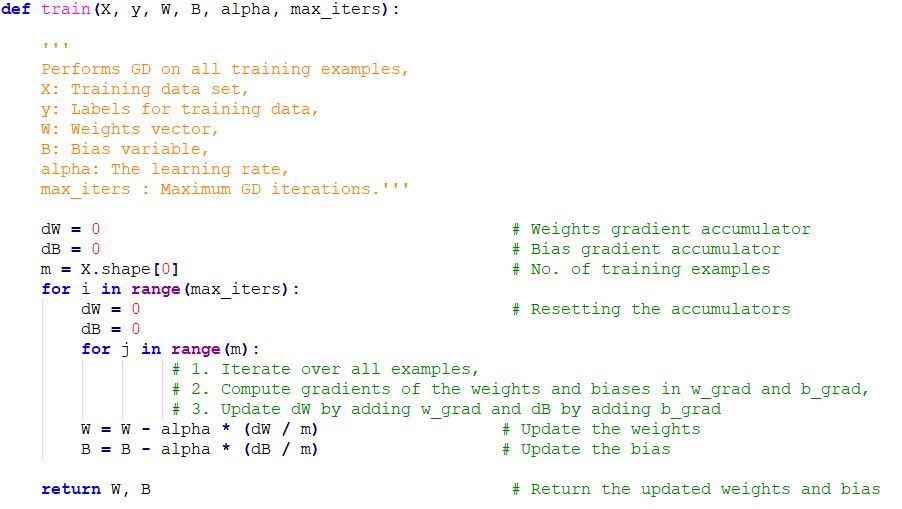
Notas finales
Una vez que sintonizamos el parámetro de aprendizaje (alfa) y obtenemos la tasa de aprendizaje óptima, comenzamos a iterar hasta que convergemos a los mínimos locales.





