Fuente: https://www.serokell.io
En la imagen de arriba, puede ver que los correos electrónicos se clasifican como spam o no. Entonces, es un ejemplo de clasificación (clasificación binaria).
1. Regresión logística
2. Bayes ingenuo
3. K-Vecinos más cercanos
5. Árbol de decisiones
Veremos todos los algoritmos con un pequeño código aplicado en el conjunto de datos del iris que se utiliza para las tareas de clasificación. El conjunto de datos tiene 150 instancias (filas), 4 características (columnas) y no contiene ningún valor nulo. Hay 3 clases en el conjunto de datos de iris:
– Iris Setosa
– Iris Versicolor
– Iris Virginica
Es un algoritmo de clasificación muy básico pero importante en el aprendizaje automático que utiliza una o más variables independientes para establecer un resultado. La regresión logística intenta hallar la vinculación que mejor se ajuste entre la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... dependiente y un conjunto de variables independientes. La línea que mejor se ajusta en este algoritmo se parece a la forma de S, como se muestra en la figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.....
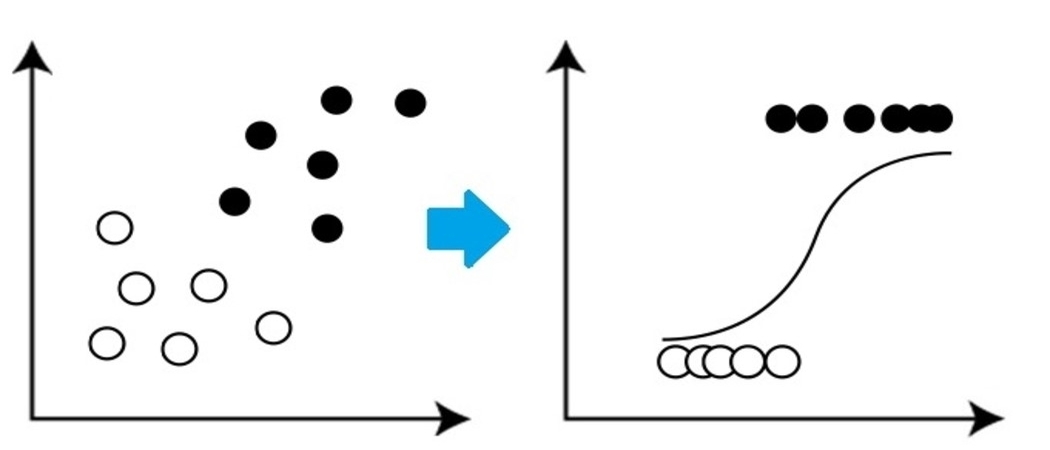
Fuente: https://www.equiskill.com
Pros:
- Es un algoritmo muy simple y eficiente.
- Varianza baja.
- Proporciona probabilidad puntuación de las observaciones.
Contras:
- Mal manejo un gran número de características categóricas.
- Asume que los datos están libres de valores perdidos y que los predictores son independientes entre sí.
Ejemplo:
from sklearn.datasets import load_iris from sklearn.linear_model import LogisticRegression X, y = load_iris() LR_classifier = LogisticRegression(random_state=0) LR_classifier.fit(X, y) LR_classifier.predict(X[:3, :])
Producción:
array([0, 0, 0]) It predicted 0 class for all 3 tests given to predict function.
2. Bayes ingenuo
Naive Bayes se basa en Teorema de bayes lo que da un supuesto de independencia entre predictores. Este clasificador asume que la presencia de una característica particular en una clase no está relacionada con la presencia de ninguna otra
característica / variable.
Los clasificadores Naive Bayes son de tres tipos: Multinomial Naive Bayes, Bernoulli Naive Bayes, Gaussian Naive Bayes.
Pros:
- Este algoritmo funciona muy rápido.
- Además se puede usar para solucionar problemas de predicción de varias clases, dado que es bastante útil con ellos.
- Este clasificador funciona mejor que otros modelos con menos datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... si se mantiene el supuesto de independencia de las características.
Contras:
- Asume
que todas las funciones son independientes. Aunque puede sonar genial en
teoría, pero en la vida real, nadie puede hallar un conjunto de características independientes.
Ejemplo:
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.naive_bayes import GaussianNB X, y = load_iris(return_X_y=True) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=142) Naive_Bayes = GaussianNB() Naive_Bayes.fit(X_train, y_train) prediction_results = Naive_Bayes.predict(X_test) print(prediction_results)
Producción:
array([0, 1, 1, 2, 1, 1, 0, 0, 2, 1, 1, 1, 2, 0, 1, 0, 2, 1, 1, 2, 2, 1,0, 1, 2, 1, 2, 2, 0, 1, 2,
1, 2, 1, 2, 2, 1, 2])
These are the classes predicted for X_test data by our naive Bayes model.
3. Algoritmo de vecino más cercano K
Debes haber oído hablar de un dicho popular:
«Dios los cría y ellos se juntan.»
KNN funciona según el mismo principio. Clasifica los nuevos puntos de datos en función de la clase de la mayoría de los puntos de datos entre el vecino K, donde K es el número de vecinos a considerar. KNN captura la idea de similitud (a veces llamada distancia,
proximidad o cercanía) con algunas fórmulas matemáticas básicas de distancia como distancia euclidiana, distancia de Manhattan, etc.

Fuente: https://www.javatpoint.com
Seleccionar el valor correcto para K
Para elegir la K adecuada para los datos que desea entrenar, ejecute el algoritmo KNN varias veces con diferentes valores de K y elija ese valor de K que reduce la cantidad de errores en los datos no vistos.
Pros:
- KNN es simple y fácil de poner en práctica.
- No es necesario crear un modelo, ajustar varios parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... o hacer suposiciones adicionales como algunos de los otros algoritmos de clasificación.
- Se puede usar para clasificación, regresión y búsqueda. Entonces, es flexible.
- El algoritmo se torna significativamente más lento a medida que aumenta el número de ejemplos y / o predictores / variables independientes.
from sklearn.neighbors import KNeighborsClassifier X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=142) knn = KNeighborsClassifier(n_neighbors=3) knn.fit(X_train, y_train) prediction_results = knn.predict(X_test[:5,:) print(prediction_results)
Producción:
array([0, 1, 1, 2, 1]) We predicted our results for 5 sample rows. Hence we have 5 results in array.
4. SVM
SVM son las siglas de Support Vector Machine. Este es un algoritmo de aprendizaje automático supervisado que se utiliza con mucha frecuencia para desafíos de clasificación y regresión. A pesar de esto, se utiliza principalmente en problemas de clasificación. El concepto básico de Support Vector Machine y cómo funciona se puede comprender mejor con este sencillo ejemplo. Entonces, imagina que tienes dos etiquetas: verde y azul, y nuestros datos disponen dos características: X y y. Queremos un clasificador que, dado un par de (x, y) coordenadas, salidas si es verde o azul. Trace los datos de entrenamiento etiquetados en un plano y después intente hallar un plano (el hiperplano de dimensiones aumenta) que segrega los puntos de datos de ambos colores con mucha claridad.

Fuente: https://www.javatpoint.com
Pero este es el caso de los datos lineales. Pero, ¿qué pasa si los datos no son lineales, entonces utiliza el truco del kernel? Entonces, para manejar esto, aumentamos la dimensión"Dimensión" es un término que se utiliza en diversas disciplinas, como la física, la matemática y la filosofía. Se refiere a la medida en la que un objeto o fenómeno puede ser analizado o descrito. En física, por ejemplo, se habla de dimensiones espaciales y temporales, mientras que en matemáticas puede referirse a la cantidad de coordenadas necesarias para representar un espacio. Su comprensión es fundamental para el estudio y..., esto trae datos en el espacio y ahora los datos se vuelven linealmente separables en dos grupos.
Pros:
- SVM funciona relativamente bien cuando existe un claro margenEl margen es un término utilizado en diversos contextos, como la contabilidad, la economía y la impresión. En contabilidad, se refiere a la diferencia entre los ingresos y los costos, lo que permite evaluar la rentabilidad de un negocio. En el ámbito editorial, el margen es el espacio en blanco alrededor del texto en una página, que facilita la lectura y proporciona una presentación estética. Su correcta gestión es esencial... de separación entre clases.
- SVM es más eficaz en espacios de gran dimensión.
Contras:
- SVM no es adecuado para grandes conjuntos de datos.
- SVM no funciona muy bien cuando el conjunto de datos tiene más ruido, dicho de otra forma, cuando las clases de destino se superponen. Entonces, necesita ser manejado.
Ejemplo:
from sklearn import svm svm_clf = svm.SVC() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=142) svm_clf.fit(X_train, y_train) prediction_results = svm_clf.predict(X_test[:7,:]) print(prediction_results)
Producción:
array([0, 1, 1, 2, 1, 1, 0])
5.Árbol de decisión
El árbol de decisiones es uno de los algoritmos de aprendizaje automático más utilizados. Se usan para problemas de clasificación y regresión. Los árboles de decisión imitan el pensamiento a nivel humano, por lo que es muy fácil comprender los datos y realizar buenas intuiciones e interpretaciones. En realidad, te hacen ver la lógica de los datos para interpretarlos. Los árboles de decisión no son como algoritmos de caja negra como SVM, redes neuronales, etc.
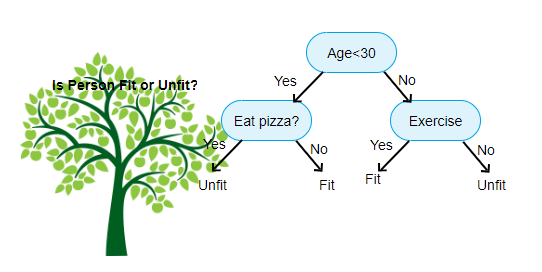
Fuente: https://www.aitimejournal.com
A modo de ejemplo, si clasificamos a una persona como apta o no apta, el árbol de decisiones se parece un poco a esto en la imagen.
Entonces, en resumen, un árbol de decisión es un árbol donde cada nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... representa un
característica / atributo, cada rama representa una decisión, una regla y cada hoja representa un resultado. Este resultado puede ser de valor categórico o continuo. Categórico en caso de clasificación y continuo en caso de aplicaciones de regresión.
Pros:
- En comparación con otros algoritmos, los árboles de decisión requieren menos esfuerzo para la preparación de datos a lo largo del preprocesamiento.
- Tampoco requieren la normalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos.... de datos ni el escalado.
- El modelo elaborado en el árbol de decisiones es muy intuitivo y fácil de explicar tanto a los equipos técnicos como a las partes interesadas.
Contras:
- Si se realiza inclusive un pequeño cambio en los datos, eso puede conducir a un gran cambio en la estructura del árbol de decisiones que causa inestabilidad.
- A veces, el cálculo puede ser mucho más complejo en comparación con otros algoritmos.
- Los árboles de decisión suelen tardar más en entrenar el modelo.
Ejemplo:
from sklearn import tree dtc = tree.DecisionTreeClassifier() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=142) dtc.fit(X_train, y_train) prediction_results = dtc.predict(X_test[:7,:]) print(prediction_results)
Producción:
array([0, 1, 1, 2, 1, 1, 0])
Notas finales
Estos son los 5 algoritmos de clasificación más populares, hay muchos más y además algoritmos avanzados. Explórelos además. Vamos a conectarnos LinkedIn
Gracias por leer si llegaste aquí 🙂
Los medios que se muestran en este post no son propiedad de DataPeaker y se usan a discreción del autor.





