Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción:
Como todos sabemos, la Inteligencia Artificial se está utilizando ampliamente a nuestro alrededor: desde leer las noticias en su dispositivo móvil o analizar esos datos complejos en su lugar de trabajo, la IA ha mejorado la velocidad, precisión y efectividad del esfuerzo humano. Los avances en IA nos han ayudado a lograr cosas que antes pensábamos que no eran posibles. Incluso tener una pizza de tu restaurante favorito en casa está a solo un clic de distancia, gracias a la IA.
En pocas palabras, la inteligencia artificial significa una computadora o un programa de computadora que imita la inteligencia humana. Se logra aprendiendo cómo piensa, aprende, decide y trabaja el cerebro humano mientras resuelve un problema. Los resultados de este estudio se utilizan luego como base para desarrollar software y sistemas inteligentes.
Hay 4 tipos de aprendizaje:
● Aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en....
● Aprendizaje sin supervisión.
● Aprendizaje semi-supervisado.
● Aprendizaje reforzado.
| Supervisado | Sin supervisión | Semi-supervisado | Reforzado |
| El aprendizaje supervisado es cuando el modelo se entrena en un conjunto de datos etiquetado. | El aprendizaje no supervisadoEl aprendizaje no supervisado es una técnica de machine learning que permite a los modelos identificar patrones y estructuras en datos sin etiquetas predefinidas. A través de algoritmos como k-means y análisis de componentes principales, este enfoque se utiliza en diversas aplicaciones, como la segmentación de clientes, la detección de anomalías y la compresión de datos. Su capacidad para revelar información oculta lo convierte en una herramienta valiosa en la... es cuando el modelo se entrena en un conjunto de datos sin etiquetar, depende del algoritmo encontrar patrones subyacentes en los datos. | Se sitúa entre el aprendizaje supervisado y no supervisado, en esto, algunos datos de aprendizaje están etiquetados y otros no. | El algoritmo evalúa su rendimiento en función de las respuestas de retroalimentación y reacciona en consecuencia. |
Este blog cubre el aprendizaje supervisado y no supervisado de la IA, utilizando el conjunto de datos de Python e Iris.
Tabla de contenido:
- Introducción
- Conjunto de datos de iris
- Aprendizaje supervisado
- Árbol de decisión
- Regresión logística
- Aprendizaje sin supervisión
- Agrupación de K-medias
- Conclusión y referencias
Conjunto de datos de iris:
El conjunto de datos contiene 3 clases con 50 instancias cada una y 150 instancias en total, donde cada clase se refiere a un tipo de planta de iris.
Clase: Iris Setosa, Iris Versicolour, Iris Virginica
El formato de los datos: (longitud del sépalo, ancho del sépalo, largo del pétalo, ancho del pétalo)

Entrenaremos nuestros modelos en función de estos parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... y los usaremos para predecir las clases de flores.
Entendiendo los datos:
Descargar el conjunto de datos de Iris de https://www.kaggle.com/uciml/iris
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
iris = pd.read_csv("Iris.csv") #Iris.csv is now a pandas dataframe
print(iris.head()) #prints first 5 values
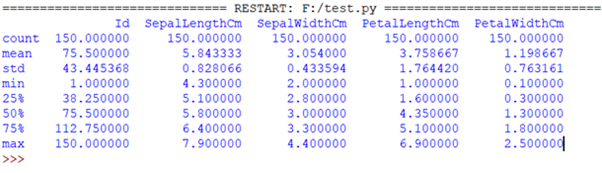
print(iris.describe()) #prints some basic statistical details like percentile,mean, std etc. of the data frame |

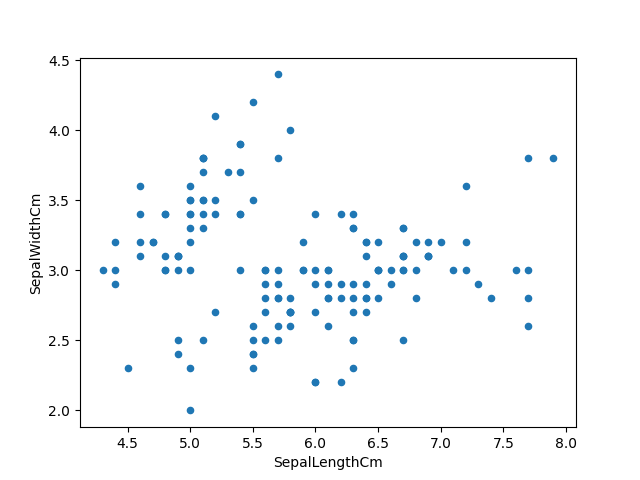
Visualizando los datos usando matplotlib:
iris.plot(kind="scatter", x="SepalLengthCm", y="SepalWidthCm") plt.show() |
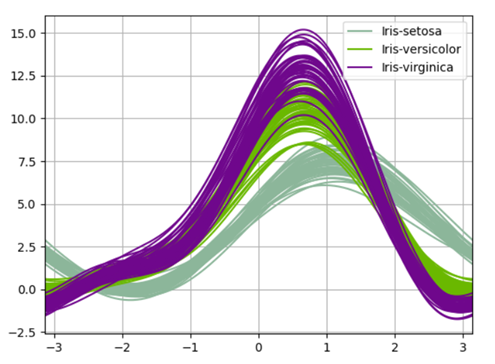
Visualización de los datos usando las curvas de andrew de pandas:
Las curvas de Andrews tienen la forma funcional:
f
x_4 sin (2t) + x_5 cos (2t) +…
Donde los coeficientes x corresponden a los valores de cada dimensión"Dimensión" es un término que se utiliza en diversas disciplinas, como la física, la matemática y la filosofía. Se refiere a la medida en la que un objeto o fenómeno puede ser analizado o descrito. En física, por ejemplo, se habla de dimensiones espaciales y temporales, mientras que en matemáticas puede referirse a la cantidad de coordenadas necesarias para representar un espacio. Su comprensión es fundamental para el estudio y... y t está espaciado linealmente entre -pi y + pi. Cada fila del marco corresponde a una única curva.
from pandas.plotting import andrews_curves
andrews_curves(iris.drop("Id", axis=1), "Species")
plt.show()
|
Procesamiento previo del conjunto de datos:
Usando una biblioteca incorporada llamada ‘train_test_split’, que divide nuestro conjunto de datos en una proporción de 80:20. El 80% se utilizará para entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina...., evaluación y selección entre nuestros modelos y el 20% se retendrá como un conjunto de datos de validación.
from sklearn.model_selection import train_test_split x = iris.iloc[:, :-1].values #last column values excluded y = iris.iloc[:, -1].values #last column value from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=0) #Splitting the dataset into the Training set and Test set |
Aprendizaje supervisado :
Los algoritmos de aprendizaje automático supervisados están entrenados para encontrar patrones utilizando un conjunto de datos. El proceso es simple, toma lo que se ha aprendido en el pasado y luego lo aplica a los nuevos datos. El aprendizaje supervisado utiliza ejemplos etiquetados para predecir patrones y eventos futuros.
Por ejemplo, cuando le enseñamos a un niño que 2 + 2 = 4 o le señalamos la imagen de cualquier animal para que sepa cómo se llama.
El aprendizaje supervisado se divide a su vez en:
● Clasificación: La clasificación predice las etiquetas de clase categóricas, que son discretas y desordenadas. Es un proceso de dos pasos, que consta de un paso de aprendizaje y un paso de clasificación. Hay varios algoritmos de clasificación como: «Clasificador de árbol de decisión», «Bosque aleatorio», «Clasificador de Bayes ingenuo», etc.
● Regresión: La regresión generalmente se describe como la determinación de una relación entre dos o más variables, como predecir el trabajo de una persona en función de los datos de entrada X. Algunos de los algoritmos de regresión son: «Regresión logística», «Regresión de lazo», «Regresión de cresta», etc. .
Clasificador de árbol de decisión:
El motivo general de usar un árbol de decisión es crear un modelo de entrenamiento que pueda usarse para predecir la clase o el valor de las variables objetivo aprendiendo reglas de decisión inferidas de datos anteriores (datos de entrenamiento).
Intenta resolver el problema mediante la representación de árbol. Cada nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... interno del árbol corresponde a un atributo y cada nodo hoja corresponde a una etiqueta de clase.
Usando el árbol de decisión en el conjunto de datos Iris:
from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score classifier = DecisionTreeClassifier() classifier.fit(x_train, y_train) #training the classifier y_pred = classifier.predict(x_test) #making precdictions print(classification_report(y_test, y_pred)) #Summary of the predictions made by the classifier print(confusion_matrix(y_test, y_pred)) #to evaluate the quality of the output print('accuracy is',accuracy_score(y_pred,y_test)) #Accuracy score
|
Precisión: precisión de las predicciones positivas.
Recuperación: fracción de positivos que se identificaron correctamente.
Puntaje F1: ¿Qué porcentaje de predicciones positivas fueron correctas?
macro avg – promediando la media no ponderada por etiqueta
promedio ponderado: promediando la media ponderada de soporte por etiqueta
Mapa de calorUn "mapa de calor" es una representación gráfica que utiliza colores para mostrar la densidad de datos en un área específica. Comúnmente utilizado en análisis de datos, marketing y estudios de comportamiento, este tipo de visualización permite identificar patrones y tendencias rápidamente. A través de variaciones cromáticas, los mapas de calor facilitan la interpretación de grandes volúmenes de información, ayudando a la toma de decisiones informadas.... para la matriz de confusión:
import seaborn as sns cm = confusion_matrix(y_test, y_pred) #Transform to df cm_df = pd.DataFrame(cm,index = ['setosa','versicolor','virginica'], columns = ['setosa','versicolor','virginica']) plt.figure(figsize=(5.5,4)) sns.heatmap(cm_df, annot=True) plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show() |
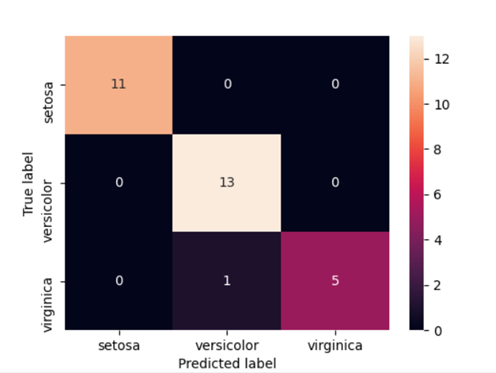
Una idea que podemos obtener de la matriz es que el modelo fue muy preciso al clasificar Setosa y Virginica (Verdadero Positivo / Todos = 1.0). Sin embargo, la precisión de Versicolor fue menor (13/14 = 0,928).
Aprendizaje sin supervisión:
El aprendizaje no supervisado se utiliza contra datos sin etiquetas históricas. El sistema no está sujeto a un conjunto predeterminado de salidas, correlaciones entre entradas y salidas o una «respuesta correcta». El algoritmo debe averiguar lo que está viendo por sí mismo, ya que no tiene ningún almacenamiento de puntos de referencia. El objetivo es explorar los datos y encontrar algún tipo de patrones o estructuras.
El aprendizaje no supervisado se puede clasificar en:
● Agrupación: La agrupación es la tarea de dividir la población o los puntos de datos en varios grupos, de modo que los puntos de datos de un grupo sean homogéneos entre sí que los de diferentes grupos. Existen numerosos algoritmos de agrupación, algunos de ellos son: «algoritmos de agrupación de K-medias», «cambio medio», «agrupación jerárquica», etc.
● Asociación: Una regla de asociación es un método de aprendizaje no supervisado que se utiliza para encontrar las relaciones entre variables en una gran base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos..... Determina el conjunto de elementos que ocurren juntos en el conjunto de datos.
Agrupación de K-medias:
El objetivo del algoritmo de agrupación en clústeres de K-medias es encontrar grupos en los datos, con el número de grupos representado por la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... K. El algoritmo funciona de forma iterativa para asignar cada punto de datos a uno de los K grupos en función de las características que se proporcionan. .
Los resultados de ejecutar un K-means en un conjunto de datos son:
● Centroides K: centroides para cada uno de los grupos K identificados en el conjunto de datos.
● Etiquetas para los datos de entrenamiento: conjunto de datos completo etiquetado para garantizar que cada punto de datos se asigne a uno de los clústeres.
Usando la agrupación en clústeres de K-means en el conjunto de datos Iris:
from sklearn.datasets import load_iris from sklearn.cluster import KMeans iris_data=load_iris() #loading iris dataset from sklearn.datasets iris_df = pd.DataFrame(iris_data.data, columns = iris_data.feature_names) #creating dataframe kmeans = KMeans(n_clusters=3,init="k-means++", max_iter = 100, n_init = 10, random_state = 0) #Applying Kmeans classifier y_kmeans = kmeans.fit_predict(x) print(kmeans.cluster_centers_) #display cluster centers plt.scatter(x[y_kmeans == 0, 0], x[y_kmeans == 0, 1],s = 100, c="red", label="Iris-setosa") plt.scatter(x[y_kmeans == 1, 0], x[y_kmeans == 1, 1],s = 100, c="blue", label="Iris-versicolour") plt.scatter(x[y_kmeans == 2, 0], x[y_kmeans == 2, 1],s = 100, c="green", label="Iris-virginica") #Visualising the clusters - On the first two columns plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:,1],s = 100, c="black", label="Centroids") #plotting the centroids of the clusters plt.legend() plt.show() |
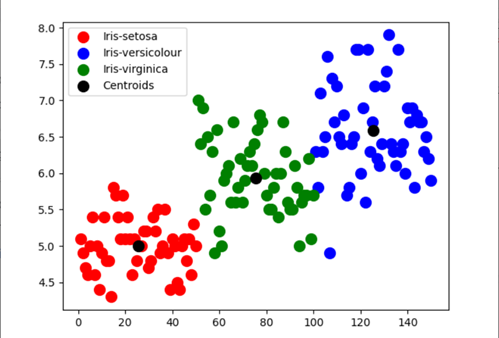
Una idea que podemos obtener del diagrama de dispersiónEl diagrama de dispersión es una herramienta gráfica utilizada en estadística para visualizar la relación entre dos variables. Consiste en un conjunto de puntos en un plano cartesiano, donde cada punto representa un par de valores correspondientes a las variables analizadas. Este tipo de gráfico permite identificar patrones, tendencias y posibles correlaciones, facilitando la interpretación de datos y la toma de decisiones basadas en la información visual presentada.... es que la precisión del modelo para determinar Setosa y Virginica es comparativamente más a Versicolour.
Conclusión:
Hemos explorado y preprocesado el conjunto de datos de Iris utilizando sklearn. conjunto de datos, así como utilizar el archivo Iris.csv. Además, aprendí sobre el aprendizaje supervisado y no supervisado e implementé el algoritmo de árbol de decisión y el algoritmo de agrupamientoEl "agrupamiento" es un concepto que se refiere a la organización de elementos o individuos en grupos con características o objetivos comunes. Este proceso se utiliza en diversas disciplinas, incluyendo la psicología, la educación y la biología, para facilitar el análisis y la comprensión de comportamientos o fenómenos. En el ámbito educativo, por ejemplo, el agrupamiento puede mejorar la interacción y el aprendizaje entre los estudiantes al fomentar el trabajo... de K-means.
Referencias:
https://www.kaggle.com/sixteenpython/machine-learning-with-iris-dataset
https://scikit-learn.org/stable/
https://certes.co.uk/types-of-artificial-intelligence-a-detailed-guide/
Sobre el Autor:
Hola lector, soy Yashi Saxena, y actualmente trabajo en TCS como ingeniero de sistemas. AI, ML y NLP siempre han sido mi interés, así que aquí estoy haciendo un esfuerzo para aprender más sobre este campo. Puedes conectarte conmigo en Linkedin: https://www.linkedin.com/in/yashi-saxena-7a9522194/
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





