Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
¿Trabaja en un proyecto sobre reconocimiento de imágenes o detección de objetos pero no tenía los conceptos básicos para construir una arquitectura?
En este artículo, veremos qué son las arquitecturas de redes neuronales convolucionales desde lo básico y tomaremos una arquitectura básica como un caso de estudio para aplicar nuestros aprendizajes.El único requisito previo es que solo necesita saber cómo funciona la convolución. preocúpate es muy simple !!
Tomemos una red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora... simple,
Iremos por capas para obtener información detallada sobre esta CNN.
Primero, hay algunas cosas que aprender de la capa 1 que es zancadas y acolchado, veremos cada uno de ellos en breve con ejemplos
Supongamos esto en la matriz de entrada de 5 × 5 y un filtro de matriz 3X3, para aquellos que no saben qué El filtro es un conjunto de pesos en una matriz que se aplica sobre una imagen o una matriz para obtener las características requeridas., busque por convolución si es la primera vez.
Nota: Siempre tomamos la suma o el promedio de todos los valores mientras hacemos una convolución.
Un filtro puede ser de cualquier profundidad, si un filtro tiene una profundidad d, puede ir a una profundidad de d capas y convolucionar, es decir, sumar todos los (pesos x entradas) de d capas
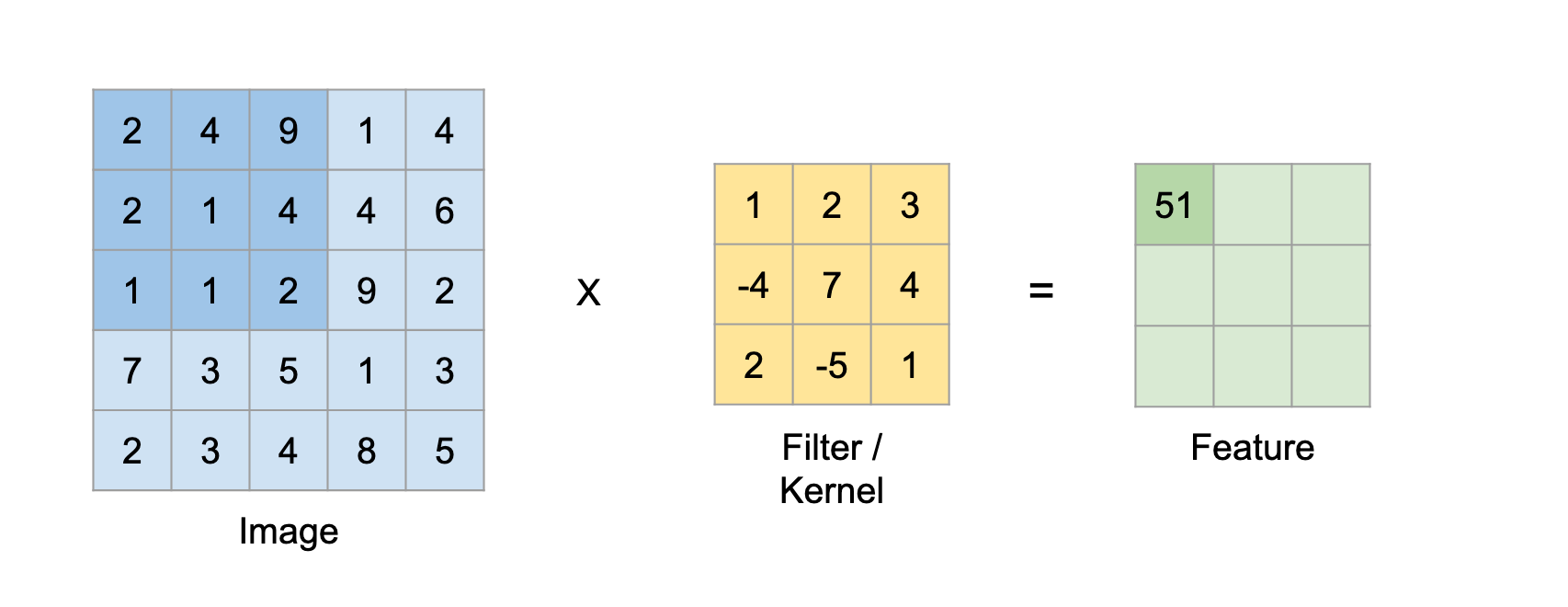
Aquí la entrada es de tamaño 5 × 5 después de aplicar un kernel o filtros de 3 × 3, se obtiene un mapa de características de salida de 3 × 3, así que intentemos formular esto
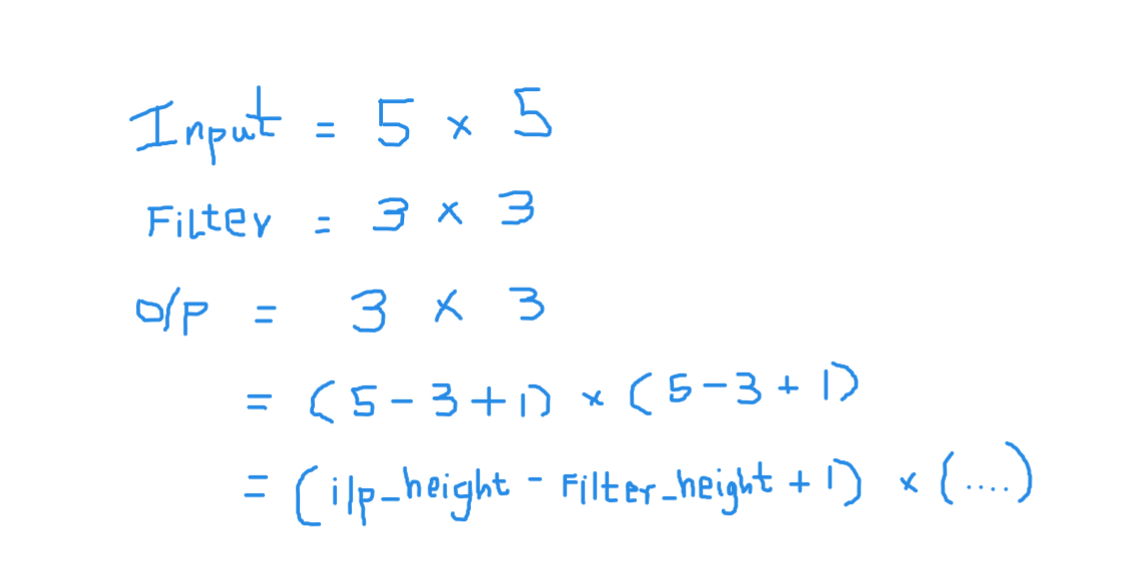
Entonces, la altura de salida está formulada y lo mismo con el ancho de o / p también …
Relleno
Mientras aplicamos convoluciones, no obtendremos las mismas dimensiones de salida que las de entrada, perderemos datos sobre los bordes, por lo que agregamos un borde de ceros y recalculamos la convolución que cubre todos los valores de entrada.
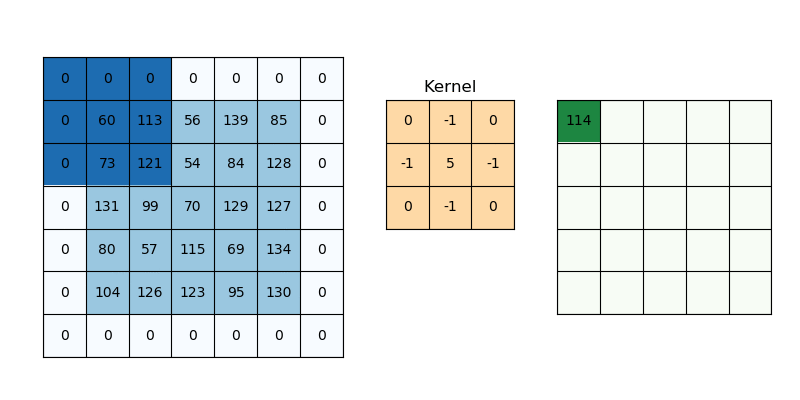
Intentaremos formular esto,
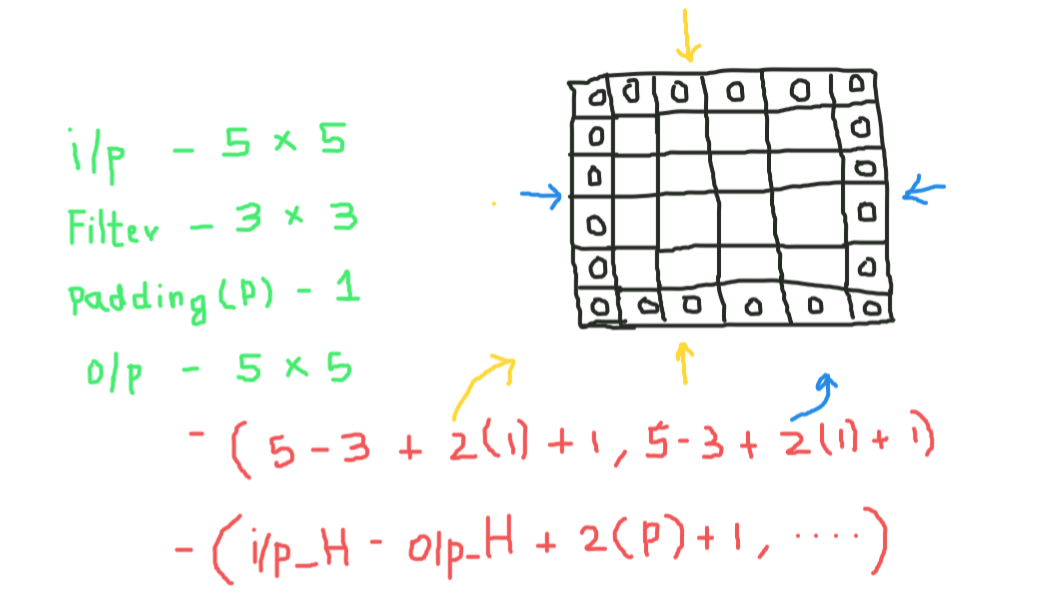
Aquí 2 es para dos columnas de ceros junto con la altura y el ancho, y formula lo mismo para el ancho también
Zancadas
Algunas veces no queremos capturar todos los datos o información disponible por lo que nos saltamos algunas celdas vecinas déjanos visualizarlo,
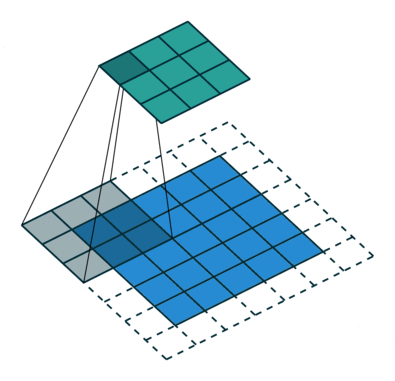
Aquí la matriz o imagen de entrada es de dimensiones 5 × 5 con un filtro de 3 × 3 y una zancada de 2 así que cada vez que saltemos dos columnas y convolucionemos, formulemos esto
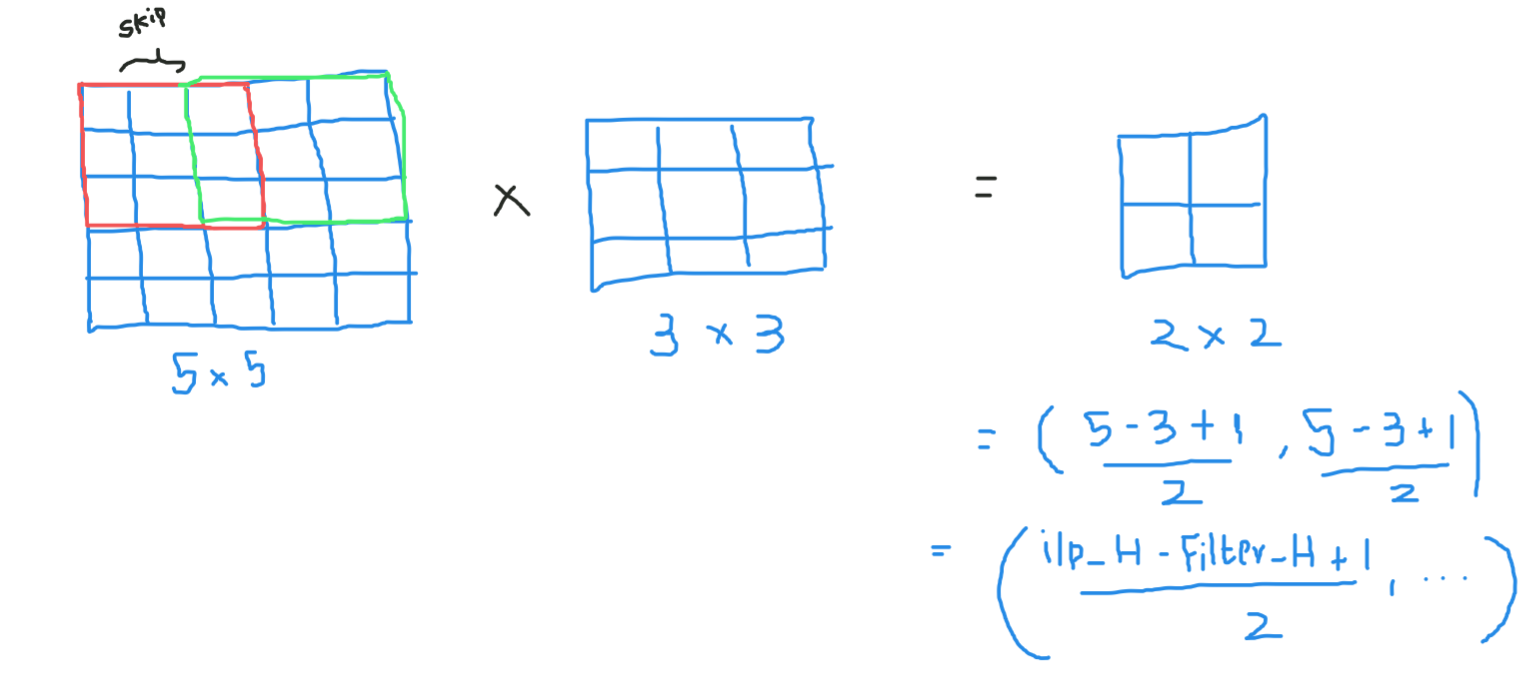
Si las dimensiones están en flotador, puede tomar ceil () en la salida, es decir (próximo entero cercano)
Aquí H se refiere a la altura, por lo que la altura de salida está formulada y lo mismo con el ancho de o / p también y aquí 2 es el valor de la zancada para que pueda hacerlo como S en las fórmulas.
Agrupación
En términos generales, la agrupación se refiere a una pequeña parte, por lo que aquí tomamos una pequeña parte de la entrada e intentamos tomar el valor promedio denominado agrupación promedio o tomar un valor máximo denominado agrupación máxima, por lo que al hacer una agrupación en una imagen, no estamos sacando todos los valores estamos tomando un valor resumido sobre todos los valores presentes !!!

aquí, este es un ejemplo de agrupación máxima, por lo que aquí, dando un paso de dos, estamos tomando el valor máximo presente en la matriz
Función de activaciónLa función de activación es un componente clave en las redes neuronales, ya que determina la salida de una neurona en función de su entrada. Su propósito principal es introducir no linealidades en el modelo, permitiendo que aprenda patrones complejos en los datos. Existen diversas funciones de activación, como la sigmoide, ReLU y tanh, cada una con características particulares que afectan el rendimiento del modelo en diferentes aplicaciones....
La función de activación es un nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... que se coloca al final o entre las redes neuronales. Ayudan a decidir si la neurona se disparará o no.. Tenemos diferentes tipos de funciones de activación como en la figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... anterior, pero para esta publicación, mi enfoque estará en Unidad lineal rectificada (ReLULa función de activación ReLU (Rectified Linear Unit) es ampliamente utilizada en redes neuronales debido a su simplicidad y eficacia. Definida como ( f(x) = max(0, x) ), ReLU permite que las neuronas se activen solo cuando la entrada es positiva, lo que contribuye a mitigar el problema del desvanecimiento del gradiente. Su uso ha demostrado mejorar el rendimiento en diversas tareas de aprendizaje profundo, haciendo de ReLU una opción...)
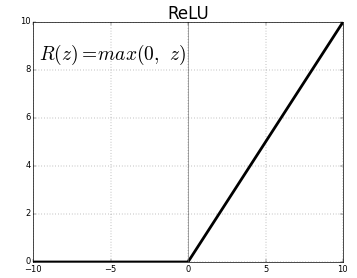
No dejes caer la mandíbula, esto no es tan complejo esta función simplemente devuelve 0 si su valor es negativo, de lo contrario, devuelve el mismo valor que dio, nada más que elimina las salidas negativas y mantiene valores entre 0 y + infinito
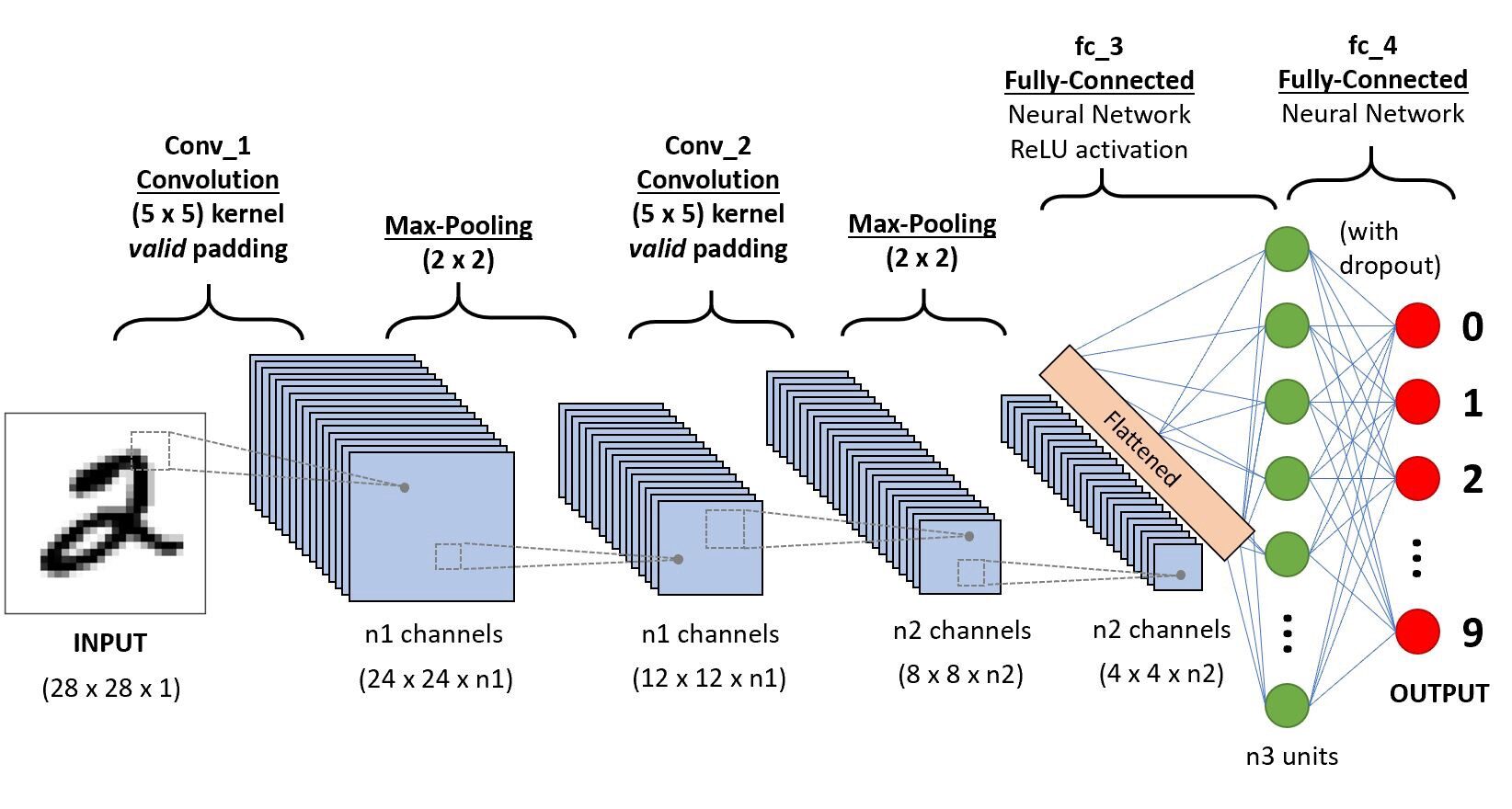
Ahora que hemos aprendido todos los conceptos básicos necesarios, estudiemos una red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... básica llamada LeNet.
LeNet-5
Antes de comenzar veremos cuáles son las arquitecturas diseñadas hasta la fecha. Estos modelos se probaron en datos de ImageNet donde tenemos más de un millón de imágenes y 1000 clases para predecir
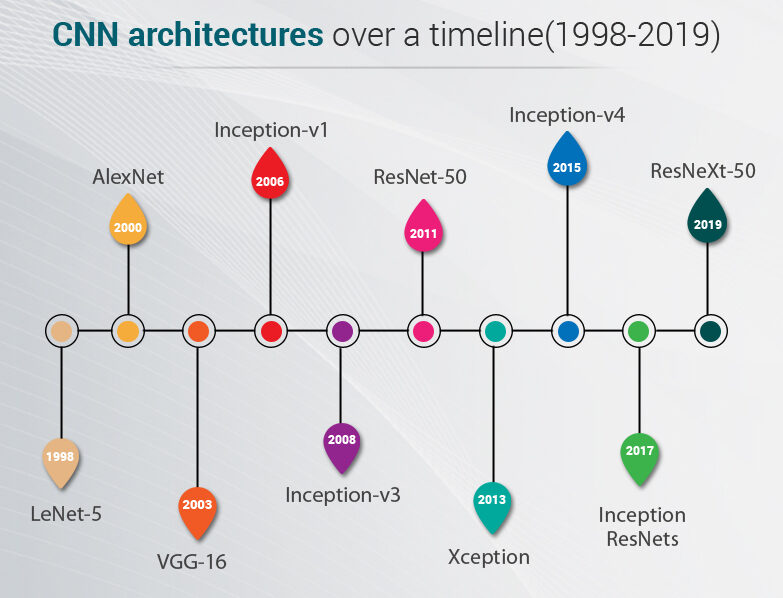
LeNet-5 es una arquitectura muy básica para que cualquiera pueda comenzar con arquitecturas avanzadas
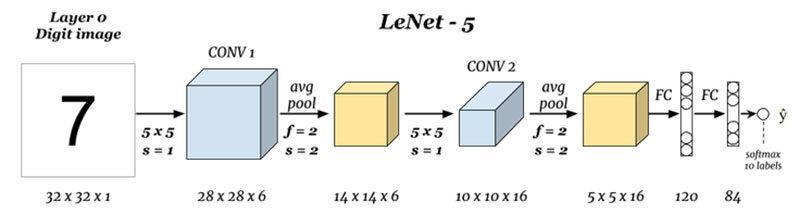
Cuáles son las entradas y salidas (Capa 0 y Capa N):
Aquí estamos prediciendo dígitos basados en la imagen de entrada dada, tenga en cuenta que aquí la imagen tiene las dimensiones de alto = 32 píxeles, ancho = 32 píxeles y una profundidad de 1, por lo que podemos suponer que es una imagen en escala de grises o en blanco y negro, teniendo en cuenta que la salida es un softmax de los 10 valores, aquí softmax da probabilidades o razones para todos los 10 dígitos, podemos tomar el número como salida con la mayor probabilidad o razón.
Convolución 1 (Capa 1):
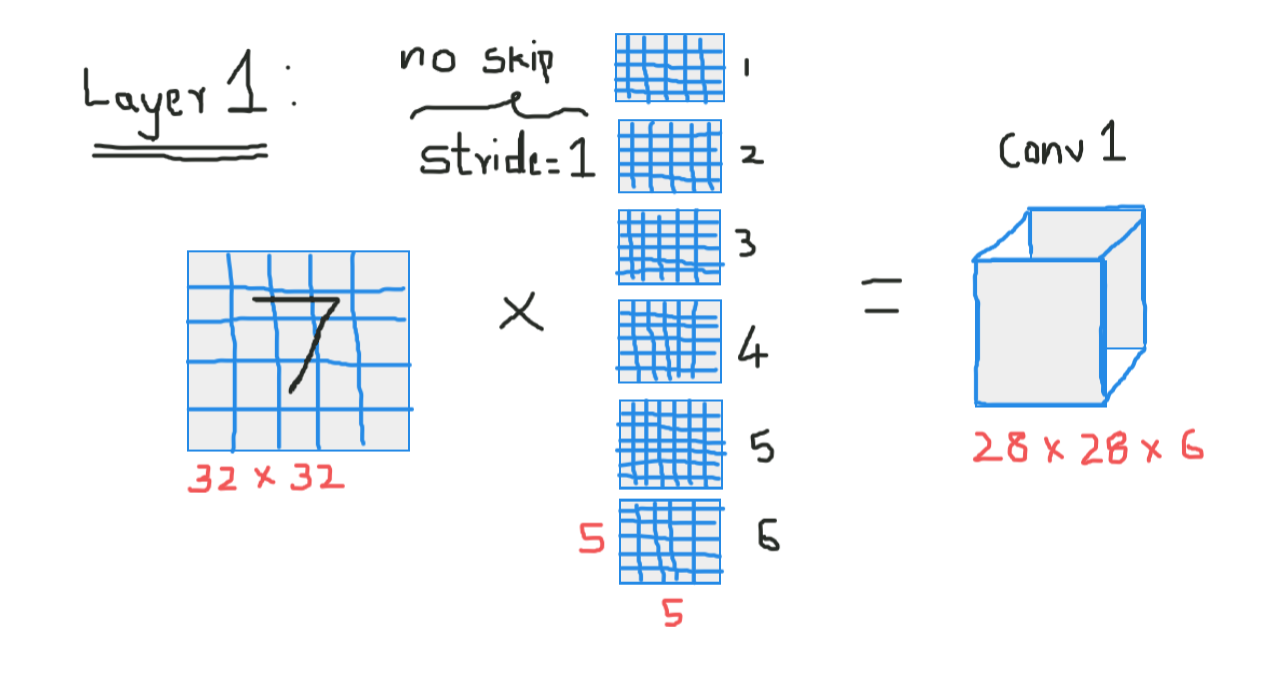
Aquí estamos tomando la entrada y convolviendo con filtros de tamaño 5 x 5, produciendo así una salida de tamaño 28 x 28.Verifique la fórmula anterior para calcular las dimensiones de salida, lo que aquí es que hemos tomado 6 filtros de este tipo y, por lo tanto, el profundidad de conv1 es 6, por lo tanto, sus dimensiones fueron 28 x 28 x 6 ahora pase esto a la capa de agrupación
Agrupación 1 (Capa 2):
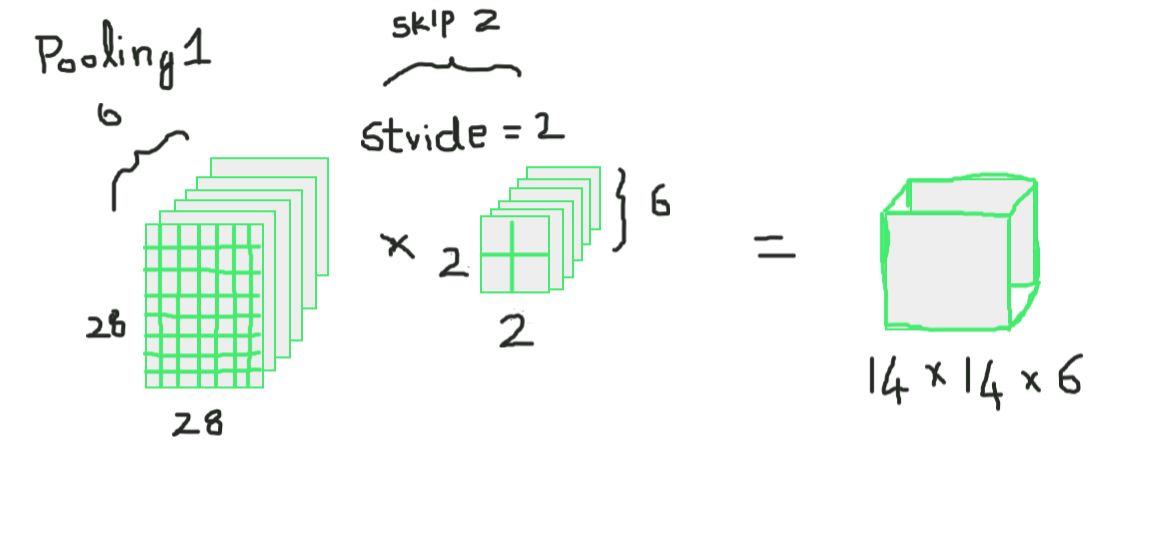
Aquí estamos tomando 28 x 28 x 6 como entrada y aplicando la combinación promedio de una matriz de 2 × 2 y un paso de 2, es decir, colocando una matriz de 2 x 2 en la entrada y tomando el promedio de todos esos cuatro píxeles y saltando con un salto de 2 columnas cada vez, lo que da 14 x 14 x 6 como salida, estamos calculando la agrupación para cada capa, por lo que aquí la profundidad de salida es 6
Convolución 2 (Capa 3):
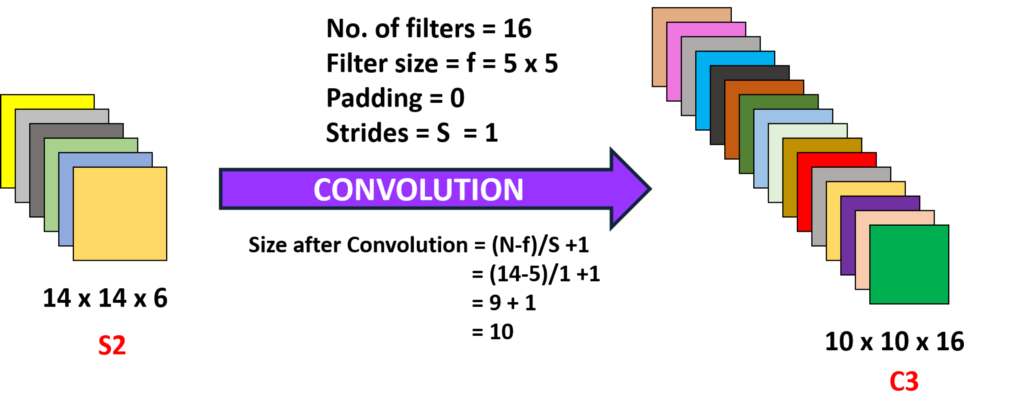
Aquí estamos tomando el 14 x 14 x 6, es decir, el o / py convolviendo con un filtro de tamaño 5 x5, con una zancada de 1, es decir (sin saltos), y con rellenos de cero, por lo que obtenemos una salida de 10 x 10, ahora aquí tomamos 16 filtros de este tipo de profundidad 6 y convolucionamos obteniendo así una salida de 10 x 10 x 16
Agrupación 2 (Capa 4):

Aquí estamos tomando la salida de la capa anterior y realizando una agrupación promedio con un paso de 2, es decir (omitir dos columnas) y con un filtro de tamaño 2 x 2, aquí superponemos este filtro en las capas de 10 x 10 x 16 por lo que para cada 10 x 10 obtenemos salidas de 5 x 5, por lo tanto, obteniendo 5 x 5 x 16
Capa (N-2) y Capa (N-1):
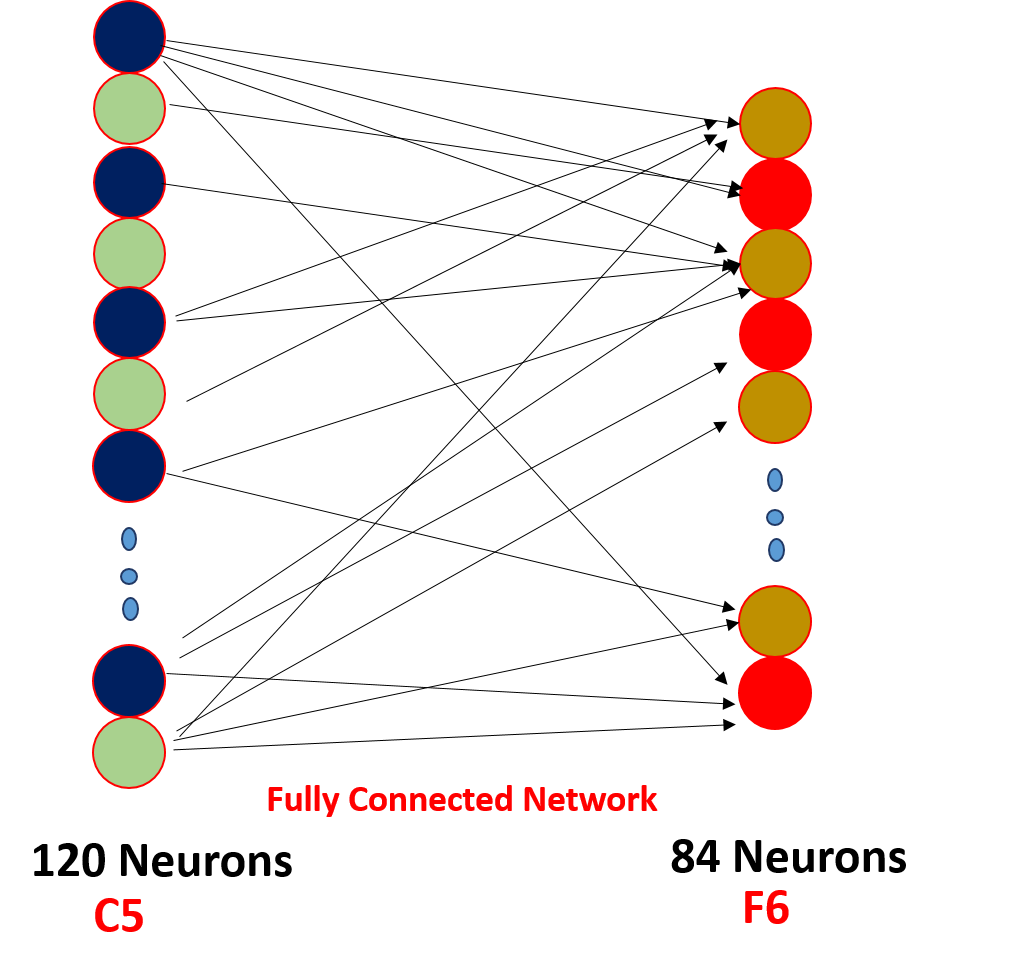
Finalmente, aplanamos todos los valores de 5 x 5 x 16 a una sola capa de tamaño 400 y los ingresamos en una red neuronal de alimentación hacia adelante de 120 neuronas que tienen una matriz de peso de tamaño. [400,120] y una capa oculta de 84 neuronas conectadas por las 120 neuronas con una matriz de peso de [120,84] y estas 84 neuronas de hecho están conectadas a 10 neuronas de salida
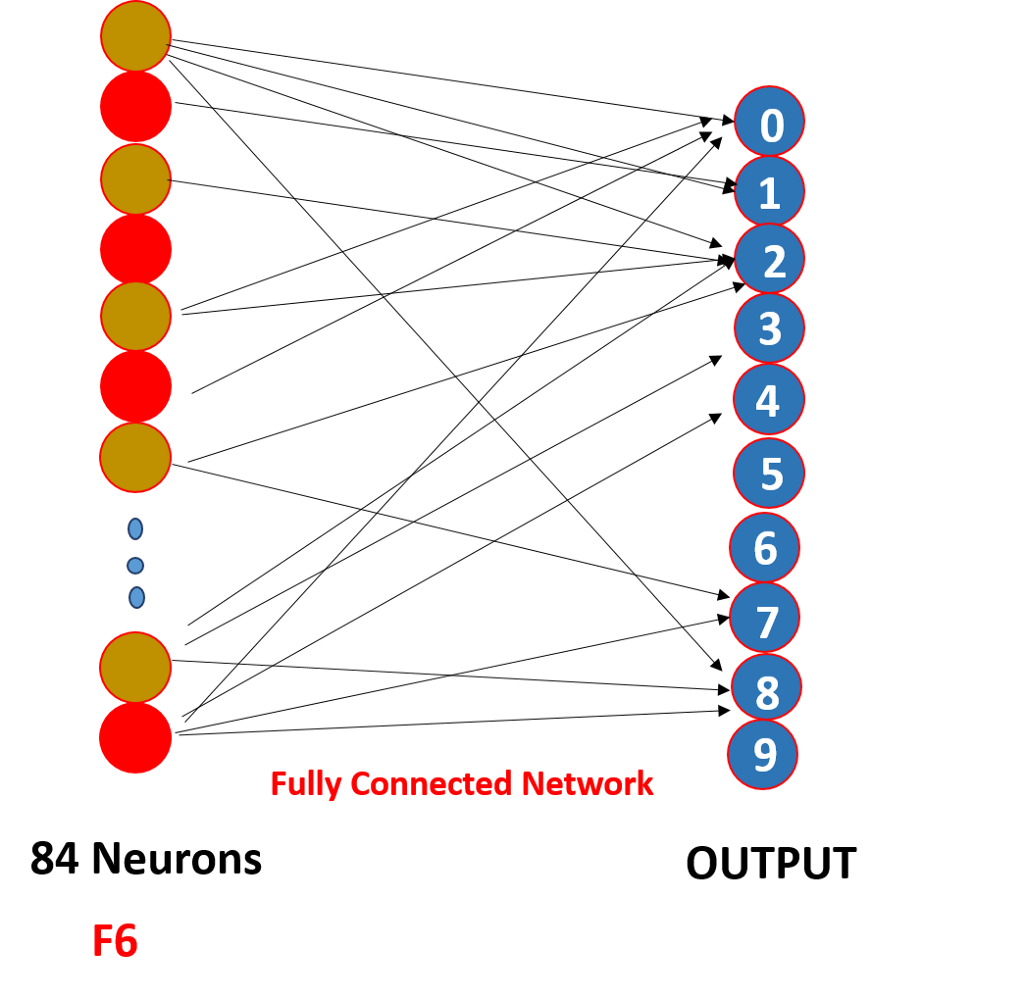
Estas neuronas o / p finalizan el número predicho por softmaxing.
¿Cómo funciona realmente una red neuronal convolucional?
Funciona a través del reparto de peso y la conectividad escasa,
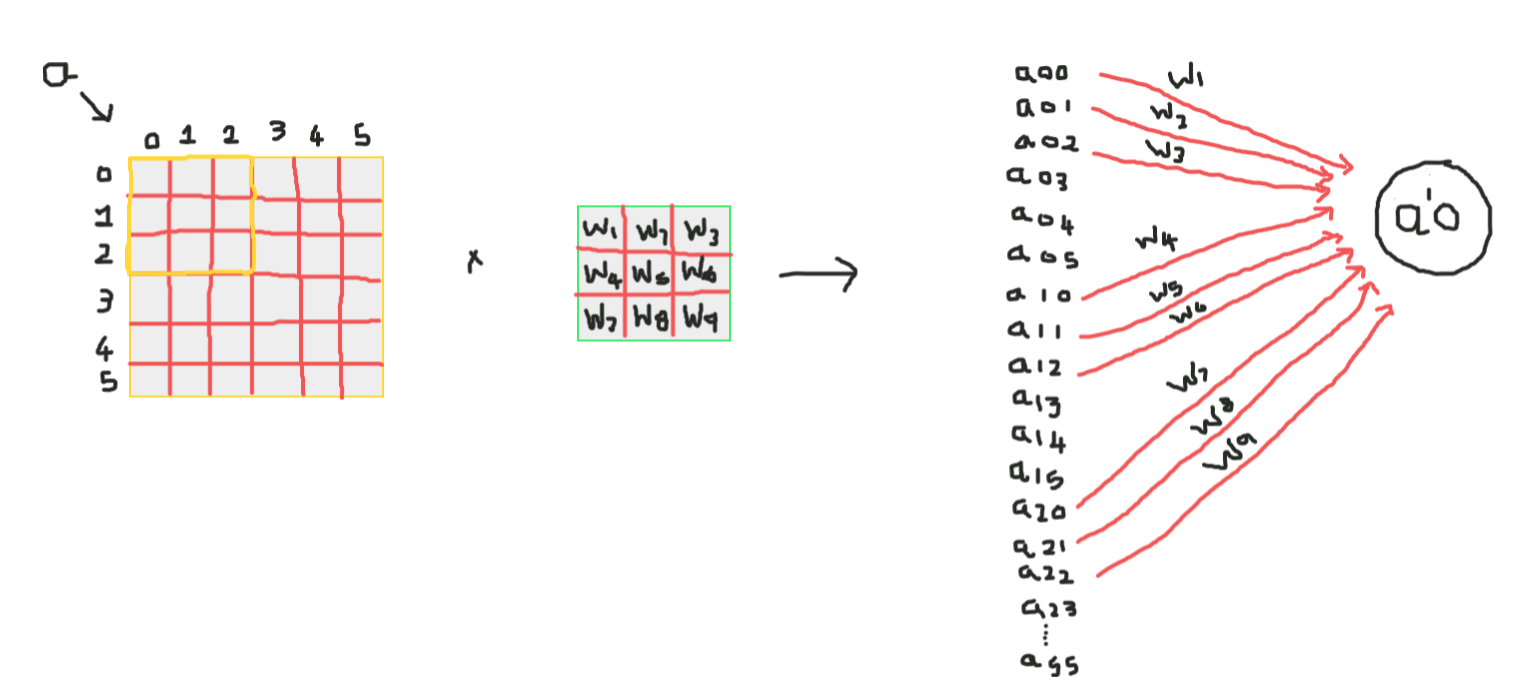
Así que aquí, como puedes ver la convolución tiene algunos pesos estos pesos son compartidos por todas las neuronas de entrada, no cada entrada tiene un peso separado llamado peso compartido, y no todas las neuronas de entrada están conectadas a la neurona de salida y solo algunas que están enrevesadas se activan, lo que se conoce como conectividad escasa, CNN no es diferente de las redes neuronales de alimentación hacia adelante, ¡estas dos propiedades las hacen especiales!
Puntos para mirar
1. Después de cada convolución, la salida se envía a una función de activación para obtener mejores características y mantener la positividad, por ejemplo: ReLu
2. La conectividad escasa y el peso compartido son la razón principal para que funcione una red neuronal convolucional.
3. El concepto de elegir una serie de filtros entre las capas y el acolchado y las dimensiones de la zancada y el filtro se toma al realizar una serie de experimentos, no te preocupes por eso, céntrate en construir los cimientos, algún día harás esos experimentos y construirás un mas productivo !!!





