Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
El Machine Learning es un campo de la tecnología que se desarrolla con inmensas habilidades y aplicaciones en la automatización de tareas, donde no se necesita la intervención humana ni la programación explícita.
El poder del aprendizaje automático es tan grande que podemos ver que sus aplicaciones son tendencias en casi todas partes de nuestra vida diaria. ML ha resuelto muchos problemas que existían antes y ha hecho que las empresas en el mundo progresen en gran medida.
Hoy, analizaremos uno de esos problemas prácticos y crearemos una solución (modelo) por nuestra cuenta utilizando ML.
¿Qué tiene de emocionante esto?
Bueno, implementaremos nuestro modelo construido usando aplicaciones Flask y Heroku. Y al final, tendremos aplicaciones web en pleno funcionamiento en nuestras manos.
¿Por qué es importante implementar su modelo?
Los modelos de aprendizaje automático generalmente apuntan a ser una solución a un problema o problemas existentes. Y en algún momento de tu vida, debes haber pensado que ¿cómo sería tu modelo una solución y cómo la gente usaría esto? De hecho, la gente no puede usar sus cuadernos y código directamente, y ahí es donde necesita implementar su modelo.
Puede implementar su modelo, como API o un servicio web. Aquí estamos usando el micro-framework Flask. Flask define un conjunto de restricciones para que la aplicación web envíe y reciba datos.
Sistema de predicción de precios de atención
Estamos a punto de implementar un modelo ML para la predicción y el análisis de precios de venta de automóviles. Este tipo de sistema resulta útil para muchas personas.
Imagina una situación en la que tienes un coche viejo y quieres venderlo. Por supuesto, puede acercarse a un agente para esto y encontrar el precio de mercado, pero más tarde tendrá que pagar dinero de bolsillo por su servicio al vender su automóvil. Pero, ¿qué pasa si puede conocer el precio de venta de su automóvil sin la intervención de un agente? O si eres agente, definitivamente esto te facilitará el trabajo. Sí, este sistema ya ha aprendido sobre los precios de venta anteriores durante años de varios automóviles.
Entonces, para ser claros, esta aplicación web implementada le proporcionará el precio de venta aproximado de su automóvil según el tipo de combustible, los años de servicio, el precio de la sala de exposición, el número de propietarios anteriores, los kilómetros recorridos, si es distribuidor / individuo y finalmente si el tipo de transmisión es manual / automática. Y ese es un punto de brownie.
Cualquier tipo de modificación también se puede incorporar posteriormente en esta aplicación. Solo es posible realizar posteriormente una facilidad para conocer compradores. Esta es una buena idea para un gran proyecto que puedes probar. Puede implementar esto como una aplicación como OLA o cualquier aplicación de comercio electrónico. Las aplicaciones de Machine Learning no terminan aquí. Del mismo modo, existen infinitas posibilidades que puedes explorar. Pero por el momento, permítame ayudarlo a crear el modelo para la predicción de precios de automóviles y su proceso de implementación.
Importar conjunto de datos
El conjunto de datos está adjunto en la carpeta de GitHub. Chequea aquí
Los datos constan de 300 filas y 9 columnas. Dado que nuestro objetivo es encontrar el precio de venta, el atributo objetivo y también es el precio de venta, las características restantes se toman para análisis y predicciones.
import numpy as np import pandas as pd data = pd.read_csv(r'C:UsersSURABHIOneDriveDocumentsprojectsdatasetscar.csv') data.head()
Ingeniería de funciones
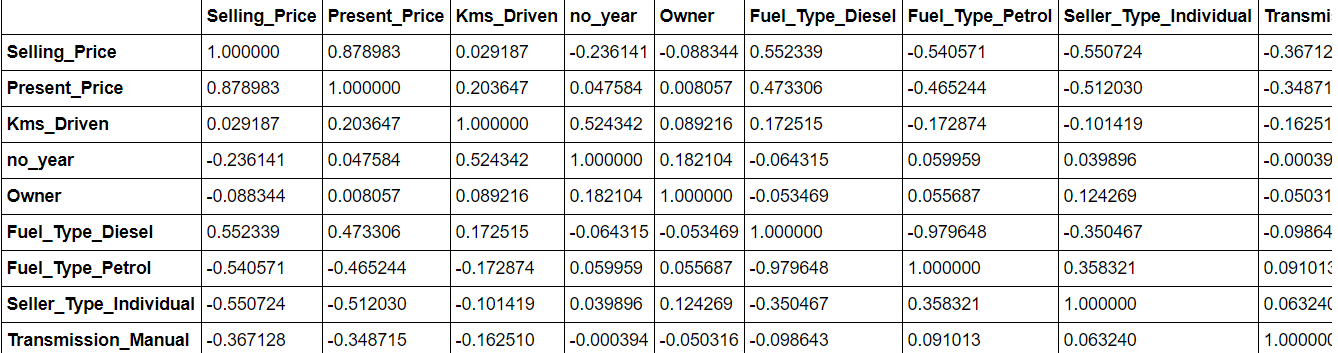
Los datos. corr () le dará una idea de la correlación entre todos los atributos en el conjunto de datos. Se pueden eliminar más características correlacionadas, ya que pueden provocar un ajuste excesivo del modelo.
data = data.drop(['Car_Name'], axis=1) data['current_year'] = 2020 data['no_year'] = data['current_year'] - data['Year'] data = data.drop(['Year','current_year'],axis = 1) data = pd.get_dummies(data,drop_first=True) data = data[['Selling_Price','Present_Price','Kms_Driven','no_year','Owner','Fuel_Type_Diesel','Fuel_Type_Petrol', 'Seller_Type_Individual','Transmission_Manual']] data
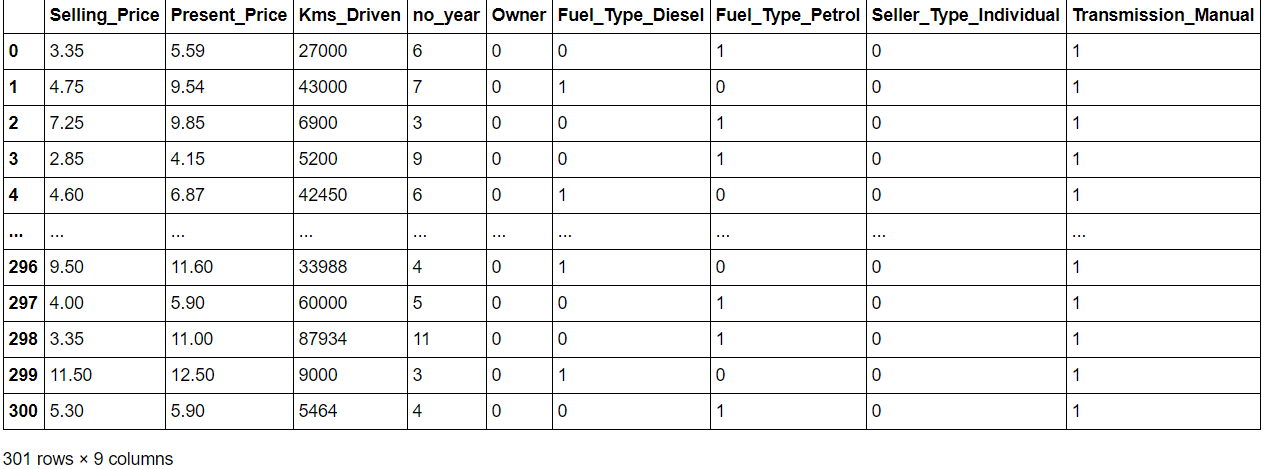
data.corr()
A continuación, dividimos los datos en conjuntos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y prueba.
x = data.iloc[:,1:] y = data.iloc[:,0]
Descubrir la importancia de las funciones para eliminar las funciones no deseadas
La biblioteca extratressregressor le permite ver la importancia de las características y, por lo tanto, eliminar las características menos importantes de los datos. Siempre se recomienda eliminar la función innecesaria porque definitivamente pueden producir mejores puntajes de precisión.
from sklearn.ensemble import ExtreesRegressor model = ExtraTreesRegressor() model.fit(x,y)

model.feature_importances_
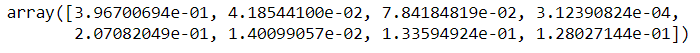
Optimización de hiperparámetros
Esto se hace para obtener los valores óptimos para su uso en nuestro modelo, esto también puede en cierta medida
ayudar a obtener buenos resultados en la predicción
n_estimators = [int(x) for x in np.linspace(start = 100, stop = 1200,num = 12)] max_features = ['auto','sqrt'] max_depth = [int(x) for x in np.linspace(5,30,num = 6)] min_samples_split = [2,5,10,15,100] min_samples_leaf = [1,2,5,10]
grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf}
print(grid)
# Producción
{'n_estimators': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200],
'max_features': ['auto', 'sqrt'],
'max_depth': [5, 10, 15, 20, 25, 30],
'min_samples_split': [2, 5, 10, 15, 100],
'min_samples_leaf': [1, 2, 5, 10]}
Prueba de tren dividida
from sklearn.model_selection import train_test_split #importing train test split module x_train, x_test,y_train,y_test = train_test_split(x,y,random_state=0,test_size=0.2)
Entrenando el modelo
Hemos utilizado el regresor de bosque aleatorio para predecir los precios de venta ya que este es un problema de regresión y ese bosque aleatorio usa múltiples árboles de decisión y ha mostrado buenos resultados para mi modelo.
from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor()
hyp = RandomizedSearchCV(estimator = model,
param_distributions=grid,
n_iter=10,
scoring= 'neg_mean_squared_error'
cv=5,verbose = 2,
random_state = 42,n_jobs = 1)
hyp.fit(x_train,y_train)
hyp es un modelo creado utilizando los hiperparámetros óptimos obtenidos a través de la validación cruzada de búsqueda aleatoria
Producción
Ahora finalmente usamos el modelo para predecir el conjunto de datos de prueba.
y_pred = hyp.predict(x_test) y_pred

Para usar el marco Flask para la implementación, es necesario empaquetar todo este modelo e importarlo al archivo Python para crear aplicaciones web. Por lo tanto, volcamos nuestro modelo en el archivo pickle usando el código dado.
import pickle
file = open("file.pkl", "wb") # opening a new file in write mode
pickle.dump(hyp, file) # dumping created model into a pickle file
Código completo
https://github.com/SurabhiSuresh22/Car-Price-Prediction/blob/master/car_project.ipynb
Marco del matraz
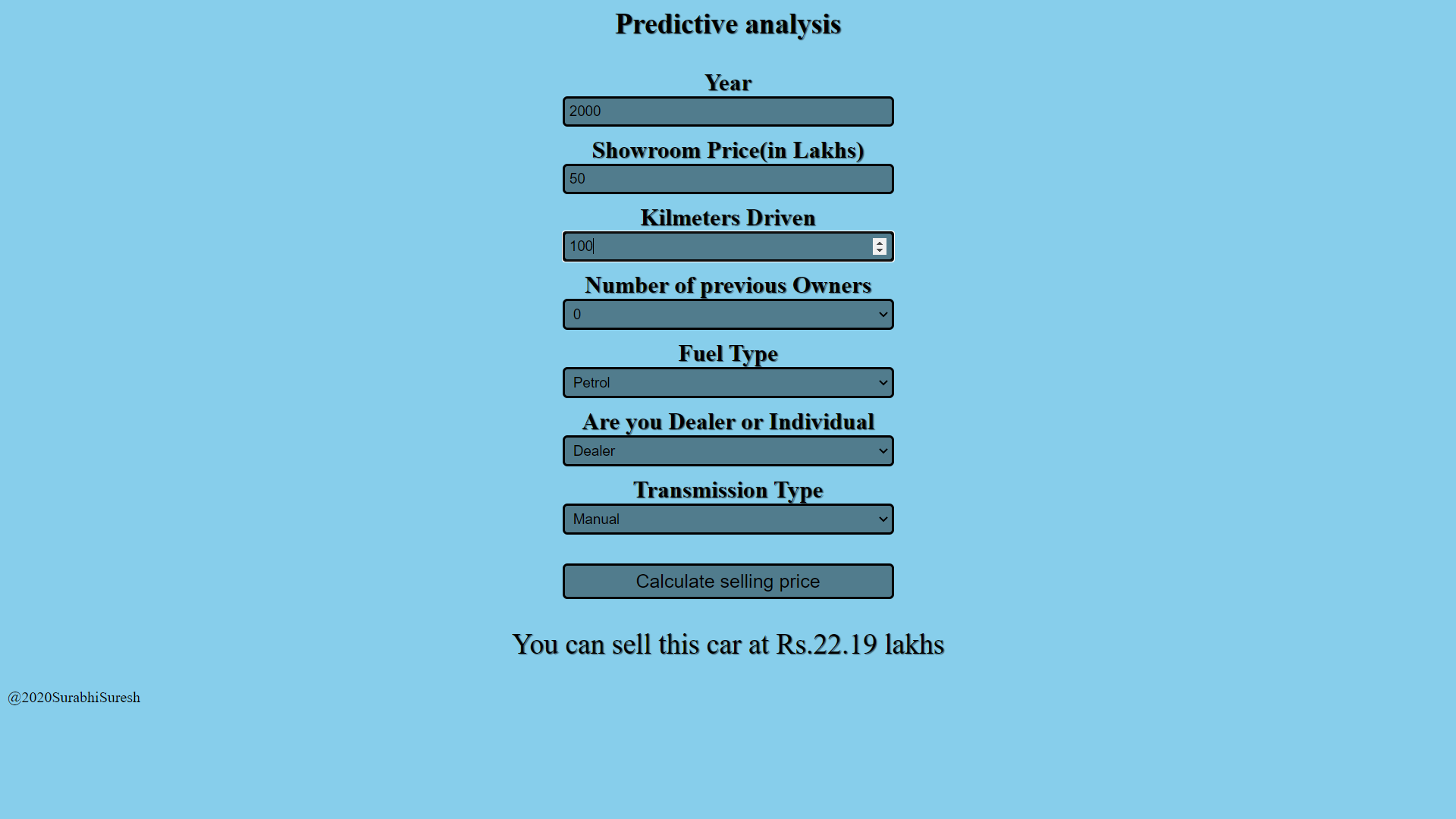
Lo que necesitamos es una aplicación web que contenga un formulario para tomar la entrada del usuario y devolver las predicciones del modelo. Entonces, desarrollaremos una aplicación web simple para esto. La interfaz se realiza utilizando HTML y CSS simples. Le aconsejo que revise los conceptos básicos del desarrollo web para comprender el significado del código escrito para la interfaz. También sería genial si conociera el marco del matraz. Atravesar este video si es nuevo en FLASK.
Déjame explicarte, brevemente, lo que he codificado usando FLASK.
Entonces, comencemos el código importando todas las bibliotecas requeridas que se usan aquí.
from flask import Flask, render_template, request import pickle import requests import numpy as np
Como saben, tenemos que importar aquí el modelo guardado para hacer las predicciones de los datos proporcionados por el usuario. Entonces estamos importando el modelo guardado
model = pickle.load(open("model.pkl", "rb"))
Ahora vayamos al código para crear la aplicación de matraz real.
app = Flask(_name_)
@app.route("/") # this will direct us to the home page when we click our web app link
def home():
return render_template("home.html") # home page
@app.route("/predict", methods = ["POST"]) # this works when the user click the prediction button
def predict():
year = int(request.form["year"]) # taking year input from the user
tot_year = 2020 - year
present_price = float(request.form["present_price"]) #taking the present prize
fuel_type = request.form["fuel_type"] # type of fuel of car
# if loop for assigning numerical values
if fuel_type == "Petrol":
fuel_P = 1
fuel_D = 0
else:
fuel_P = 0
fuel_D = 1
kms_driven = int(request.form["kms_driven"]) # total driven kilometers of the car
transmission = request.form["transmission"] # transmission type
# assigning numerical values
if transmisson == "Manuel":
transmission_manual = 1
else:
transmission_manual = 0
seller_type = request.form["seller_type"] # seller type
if seller_type == "Individual":
seller_individual = 1
else:
seller_individual = 0
owner = int(request.form["owner"]) # number of owners
values = [[
present_price,
kms_driven,
owner,
tot_year,
fuel_D,
fuel_P,
seller_individual,
transmission_manual
]]
# created a list of all the user inputed values, then using it for prediction
prediction = model.predict(values)
prediction = round(prediction[0],2)
# returning the predicted value inorder to display in the front end web application
return render_template("home.html", pred = "Car price is {} Lakh".format(float(prediction)))
if _name_ == "_main_":
app.run(debug = True)
Implementación con Heroku
Todo lo que necesita hacer es conectar su repositorio de GitHub que contiene todos los archivos necesarios para el proyecto con Heroku. Para todos aquellos que no saben qué es Heroku, Heroku es una plataforma que permite a los desarrolladores crear, ejecutar y operar aplicaciones en la nube.
Este es el enlace a la aplicación web que he creado usando la plataforma Heroku. Entonces, hemos visto el proceso de construcción e implementación de un modelo de aprendizaje automático. También puedes hacerlo, aprender más y no dudes en probar cosas nuevas y desarrollarlas.
https://car-price-analysis-app.herokuapp.com/
Conclusión
Entonces, hemos visto el proceso de construcción e implementación de un modelo de aprendizaje automático. También puedes hacerlo, aprender más y no dudes en probar cosas nuevas y desarrollarlas. Siéntete libre de conectarte conmigo en vinculado en.
Gracias
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





