Introducción
Con la creciente necesidad de administradores de ciencia de datos, necesitamos herramientas que eliminen la dificultad de hacer ciencia de datos y lo hagan divertido. No todo el mundo está dispuesto a aprender a codificar, aunque querría aprender / aplicar la ciencia de datos. Aquí es donde las herramientas basadas en GUI pueden resultar útiles.
Hoy, les presentaré otra herramienta basada en GUI: Orange. Esta herramienta es ideal para principiantes que desean visualizar patrones y comprender sus datos sin saber realmente cómo codificar.
En mi artículo anterior, les presenté otra herramienta KNIME basada en GUI. Si no desea aprender a codificar pero aún aplicar la ciencia de datos, puede probar cualquiera de estas herramientas.
Al final de este tutorial, podrá predecir qué persona de un determinado grupo de personas es elegible para un préstamo con Orange.
Tabla de contenido:
- ¿Por qué Orange?
- Configuración de su sistema:
- Creando su primer flujo de trabajo
- Familiarizarse con los conceptos básicos
- Planteamiento del problema
- Importando los archivos de datos
- Entendiendo los datos
- ¿Cómo limpias tus datos?
- Entrenando tu primer modelo
1. ¿Por qué Orange?
Orange es una plataforma construida para minería y análisis en un flujo de trabajo basado en GUI. Esto significa que no tiene que saber cómo codificar para poder trabajar con Orange y extraer datos, procesar números y obtener información.
Puede realizar tareas que van desde elementos visuales básicos hasta manipulaciones de datos, transformaciones y minería de datos. Consolida todas las funciones de todo el proceso en un solo flujo de trabajo.
La mejor parte y el diferenciador de Orange es que tiene unas imágenes maravillosas. Puede probar siluetas, mapas de calor, mapas geográficos y todo tipo de visualizaciones disponibles.

2. Configuración de su sistema
Orange viene integrado con la herramienta Anaconda si la ha instalado previamente. De lo contrario, siga estos pasos para descargar Orange.
Paso 1: ve a https://orange.biolab.si y haga clic en Descargar.
Paso 2: Instale la plataforma y configure el directorio de trabajo para que Orange almacene sus archivos.
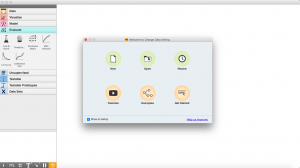
Así es como se ve la página de inicio de Orange. Tiene opciones que le permiten crear nuevos proyectos, abrir proyectos recientes o ver ejemplos y comenzar.
Antes de profundizar en cómo funciona Orange, definamos algunos términos clave para ayudarnos a comprender:
- Un widget es el punto de procesamiento básico de cualquier manipulación de datos. Puede realizar una serie de acciones en función de lo que elija en el selector de widgets a la izquierda de la pantalla.
- Un flujo de trabajo es la secuencia de pasos o acciones que realiza en su plataforma para lograr una tarea en particular.
También puede ir a «Ejemplos de flujos de trabajo» en la pantalla de inicio para ver más flujos de trabajo una vez que haya creado el primero.
Por ahora, haga clic en «Nuevo» y comencemos a crear su primer flujo de trabajo.
3. Creación de su primer flujo de trabajo
Este es el primer paso hacia la construcción de una solución a cualquier problema. Primero debemos comprender qué pasos debemos tomar para lograr nuestro objetivo final. Después de hacer clic en «Nuevo» en el paso anterior, esto es lo que debería haber creado.

Este es su flujo de trabajo en blanco en Orange. Ahora, está listo para explorar y resolver cualquier problema arrastrando cualquier widget desde el menú de widgets a su flujo de trabajo.
4. Familiarizarse con los conceptos básicos
Orange es una plataforma que puede ayudarnos a resolver la mayoría de los problemas de la ciencia de datos en la actualidad. Temas que van desde las visualizaciones más básicas hasta modelos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina..... Incluso puede evaluar y realizar un aprendizaje no supervisadoEl aprendizaje no supervisado es una técnica de machine learning que permite a los modelos identificar patrones y estructuras en datos sin etiquetas predefinidas. A través de algoritmos como k-means y análisis de componentes principales, este enfoque se utiliza en diversas aplicaciones, como la segmentación de clientes, la detección de anomalías y la compresión de datos. Su capacidad para revelar información oculta lo convierte en una herramienta valiosa en la... en conjuntos de datos:
4.1 Problema
El problema que buscamos resolver en este tutorial es el problema de práctica. Predicción de préstamos al que se puede acceder a través de este enlace sobre Datahack.
4.2 Importación de archivos de datos
Comenzamos con el primer y necesario paso para comprender nuestros datos y hacer predicciones: importando nuestros datos
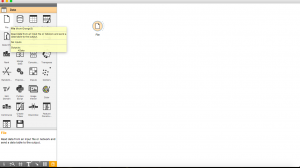
Paso 1: Haga clic en la pestaña «Datos» en el menú selector de widgets y arrastre el widget «Archivo» a nuestro flujo de trabajo en blanco.
Paso 2: Haga doble clic en el widget «Archivo» y seleccione el archivo que desea cargar en el flujo de trabajo. En este artículo, ya que aprenderemos a resolver el problema de práctica Predicción de préstamos, importaré el conjunto de datos de entrenamiento del mismo.
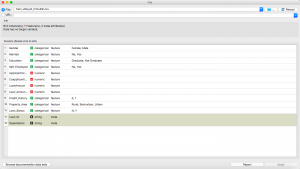
Paso 3: Una vez que pueda ver la estructura de su conjunto de datos usando el widget, regrese cerrando este menú.
Paso 4: Ahora que tenemos los detalles .csv sin procesar, necesitamos convertirlos a un formato que podamos usar en nuestra minería. Haga clic en la línea de puntos que rodea el widget «Archivo» y arrastre, y luego haga clic en cualquier lugar del espacio en blanco.
Paso 5: Como necesitamos una tabla de datos para visualizar mejor nuestros hallazgos, hacemos clic en el widget «Tabla de datos».
Paso 6: Ahora haga doble clic en el widget para visualizar su tabla.
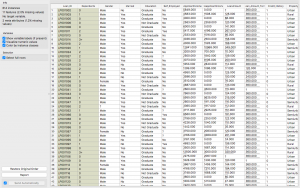
¡Limpio! ¿No es así?
Visualicemos ahora algunas columnas para encontrar patrones interesantes en nuestros datos.
4.3 Comprensión de nuestros datos
4.3.1 Gráfico de dispersiónUn gráfico de dispersión es una representación visual que muestra la relación entre dos variables numéricas mediante puntos en un plano cartesiano. Cada eje representa una variable, y la ubicación de cada punto indica su valor en relación con ambas. Este tipo de gráfico es útil para identificar patrones, correlaciones y tendencias en los datos, facilitando el análisis y la interpretación de relaciones cuantitativas....
Haga clic en el semicírculo frente al widget «Archivo» y arrástrelo a un espacio vacío en el flujo de trabajo y seleccione el widget «Diagrama de dispersión».
Una vez que haya creado un widget de gráfico de dispersión, haga doble clic en él y explore sus datos de esta manera. Puede seleccionar los ejes X e Y, colores, formas, tamaños y muchas otras manipulaciones.
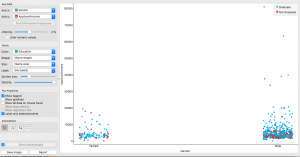
La trama que he explorado es una trama de género por ingresos, con los colores establecidos en los niveles de educación. Como podemos ver en los hombres, ¡el grupo de ingresos más altos pertenece naturalmente a los graduados!
Aunque en las mujeres, vemos que muchas de las mujeres graduadas ganan poco o casi nada. ¿Alguna razón específica? Averigüemos usando el diagrama de dispersiónEl diagrama de dispersión es una herramienta gráfica utilizada en estadística para visualizar la relación entre dos variables. Consiste en un conjunto de puntos en un plano cartesiano, donde cada punto representa un par de valores correspondientes a las variables analizadas. Este tipo de gráfico permite identificar patrones, tendencias y posibles correlaciones, facilitando la interpretación de datos y la toma de decisiones basadas en la información visual presentada.....
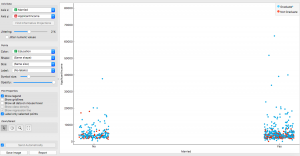
Una posible razón que encontré fue el matrimonio. Se encontró que un gran número de graduados casados pertenecían a grupos de menores ingresos; esto puede deberse a responsabilidades familiares o esfuerzos adicionales. Tiene perfecto sentido, ¿verdad?
4.3.2 Distribución
Otra forma de visualizar nuestras distribuciones sería el widget «Distribuciones». Haga clic en el semicírculo nuevamente y arrastre para encontrar el widget «Distribuciones».
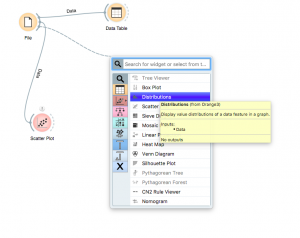
¡Ahora haz doble clic en él y visualiza!
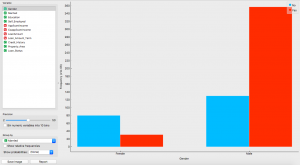
Lo que vemos es una distribución muy interesante. Tenemos en nuestro conjunto de datos más cantidad de hombres casados que de mujeres.
4.3.3 Diagrama de tamiz
¿Cómo se relacionan los ingresos con los niveles educativos? ¿A los graduados se les paga más que a los no graduados?
Visualicemos usando un diagrama de tamiz.
Haga clic y arrastre desde el widget «Archivo» y busque «Diagrama de tamiz».
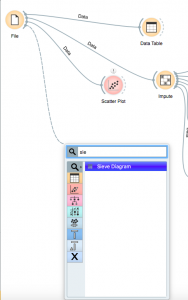
Una vez que lo coloques, haz doble clic en él y selecciona tus ejes.
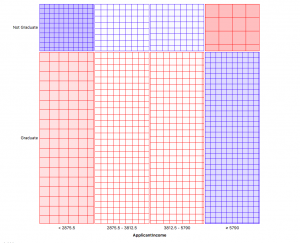
Este gráfico divide las secciones de distribución en 4 contenedores. Las secciones se pueden investigar pasando el mouse sobre ellas.
Por ejemplo, los graduados y no graduados se dividen 78% por 22%. Luego, se realizan subdivisiones del 25% cada una dividiendo los ingresos del solicitante en 4 grupos iguales. Aquí la tarea para usted, genere información a partir de estos gráficos y compártala en la sección de comentarios.
Veamos ahora cómo limpiar nuestros datos para comenzar a construir nuestro modelo.
5. ¿Cómo limpia sus datos?
Aquí, con fines de limpieza, imputaremos los valores faltantes. La imputación es un paso muy importante para comprender y hacer el mejor uso de nuestros datos.
Haga clic en el widget «Archivo» y arrastre para encontrar el widget «Imputar».
Cuando haga doble clic en el widget después de colocarlo, verá que hay una variedad de métodos de imputación que puede utilizar. También puede utilizar métodos predeterminados o elegir métodos individuales para cada clase por separado.
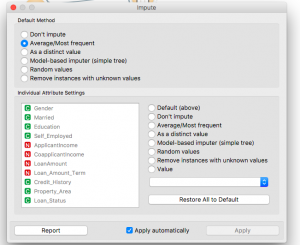
Aquí, he seleccionado el método predeterminado para que sea Promedio para valores numéricos y Más frecuente para valores basados en texto (categórico).
Puede seleccionar entre una variedad de imputaciones como:
- Valor distinto
- Valores aleatorios
- Eliminar las filas con valores perdidos
- Basado en modelos
Las otras cosas que puede incluir en su enfoque para entrenar su modelo son la extracción y generación de características. Para una mayor comprensión, siga este artículo sobre exploración de datos e ingeniería de características (https://www.analyticsvidhya.com/blog/2016/01/guide -exploración-de-datos /)
6. Entrenando su primer modelo
Comenzando con lo básico, primero entrenaremos un modelo lineal que abarque todas las características solo para comprender cómo seleccionar y construir modelos.
Paso 1: Primero, necesitamos establecer una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de destino para aplicar la Regresión logística en ella.
Paso 2: Vaya al widget «Archivo» y haga doble clic en él.
Paso 3: Ahora, haga doble clic en el Loan_Status columna y selecciónela como la variable de destino. Haga clic en Aplicar.
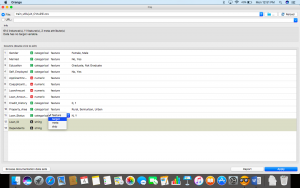
Paso 4: Una vez que hayamos establecido nuestra variable de destino, busque los datos limpios del widget «Imputar» de la siguiente manera y coloque el widget «Regresión logística».
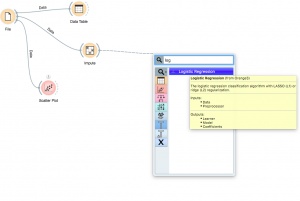
Paso 5: Haga doble clic en el widget y seleccione el tipo de regularizaciónLa regularización es un proceso administrativo que busca formalizar la situación de personas o entidades que operan fuera del marco legal. Este procedimiento es fundamental para garantizar derechos y deberes, así como para fomentar la inclusión social y económica. En muchos países, la regularización se aplica en contextos migratorios, laborales y fiscales, permitiendo a quienes se encuentran en situaciones irregulares acceder a beneficios y protegerse de posibles sanciones.... que desea realizar.
- Regresión de crestas:
- Realiza la regularización L2, es decir, agrega una penalización equivalente a cuadrado de la magnitud de coeficientes
- Objetivo de minimización = LS Obj + α * (suma del cuadrado de los coeficientes)
- Regresión de lazo:
- Realiza la regularización L1, es decir, agrega una penalización equivalente a valor absoluto de la magnitud de coeficientes
- Objetivo de minimización = LS Obj + α * (suma del valor absoluto de los coeficientes)
Para una mejor comprensión de estos, visite el enlace sobre regresiones de Ridge y Lasso https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-ridge-lasso-regression-python/
He elegido Ridge para mi análisis, puede elegir entre los dos.
Paso 6: A continuación, haga clic en el widget «Imputar» o «Regresión logística» y busque el widget «Prueba y puntaje». Asegúrese de conectar ambos datos y el modelo al widget de prueba.
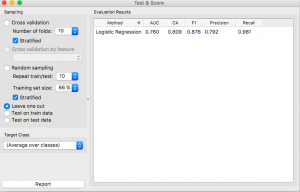
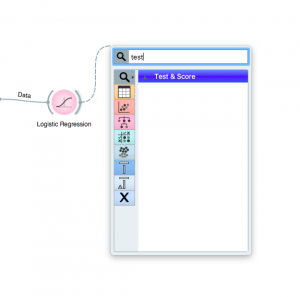 Paso 7: Ahora, haga clic en el widget «Prueba y puntaje» para ver qué tan bien le está yendo a su modelo.
Paso 7: Ahora, haga clic en el widget «Prueba y puntaje» para ver qué tan bien le está yendo a su modelo.
Paso 8: Para visualizar mejor los resultados, arrastre y suelte desde el widget «Prueba y puntaje» para encontrar «Matriz de confusión».
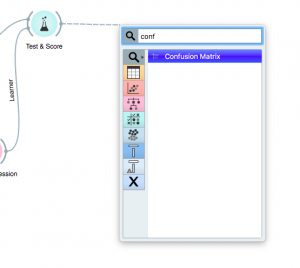
Paso 9: Una vez que lo haya colocado, haga clic en él para visualizar sus hallazgos.
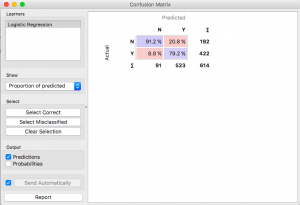
De esta manera, puede probar diferentes modelos y ver con qué precisión funcionan.
Tratemos de evaluar, ¿cómo funcionaría un bosque aleatorio? Cambie el método de modelado a Random Forest y observe la matriz de confusión.
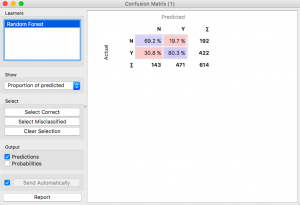
Parece decente, pero la regresión logística funcionó mejor.
Podemos volver a intentarlo con una máquina de vectores de soporte.
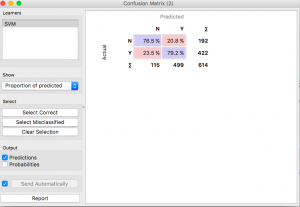
Mejor que el bosque aleatorio, pero aún no tan bueno como el modelo de regresión logística.
A veces, los métodos más simples son los mejores, ¿no es así?
Así es como se vería su flujo de trabajo final una vez que haya terminado con el proceso completo.
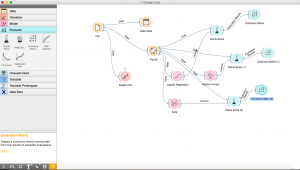
Para las personas que desean trabajar en grupos, también pueden exportar sus flujos de trabajo y enviarlos a amigos que pueden trabajar junto a usted.
El archivo resultante tiene la extensión (.ows) y se puede abrir en cualquier otra configuración de Orange.
Notas finales
Orange es una plataforma que se puede utilizar para casi cualquier tipo de análisis, pero lo más importante, para imágenes hermosas y fáciles. En este artículo, exploramos cómo visualizar un conjunto de datos. También se realizó un modelo predictivo, utilizando un predictor de regresión logística, SVM y un predictor de bosque aleatorio para encontrar los estados de los préstamos para cada persona en consecuencia.
Espero que este tutorial te haya ayudado a descubrir aspectos del problema que quizás no hayas entendido o que no hayas comprendido antes. Es muy importante comprender la canalización de la ciencia de datos y los pasos que damos para entrenar un modelo, ¡y esto seguramente debería ayudarlo a construir mejores modelos predictivos pronto!





