Mapa reducido es un modelo de programación para procesar grandes conjuntos de datos con un paralelo, distribuido algoritmo en un clúster (fuente: Wikipedia). Map Reduce cuando se combina con HDFS se puede usar para manejar big data. Los principios fundamentales de este sistema HDFS-MapReduce, que comúnmente se conoce como Hadoop, se discutieron en nuestro post anterior.
La unidad básica de información que se utiliza en MapReduceMapReduce es un modelo de programación diseñado para procesar y generar grandes conjuntos de datos de manera eficiente. Desarrollado por Google, este enfoque Divide el trabajo en tareas más pequeñas, las cuales se distribuyen entre múltiples nodos en un clúster. Cada nodo procesa su parte y luego se combinan los resultados. Este método permite escalar aplicaciones y manejar volúmenes masivos de información, siendo fundamental en el mundo del Big Data.... es un par (clave, valor). Todos los tipos de datos estructurados y no estructurados deben traducirse a esta unidad básica, antes de alimentar los datos al modelo MapReduce. Como sugiere el nombre, el modelo MapReduce consta de dos rutinas separadas, a saber, función de mapa y función de disminución. Este post lo ayudará a comprender la funcionalidad paso a paso del modelo Map-Reduce. El cálculo de una entrada (dicho de otra forma, en un conjunto de pares) en el modelo MapReduce ocurre en tres etapas:
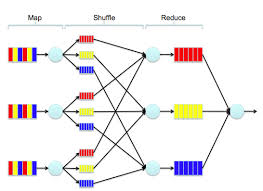
Paso 1: la etapa del mapa
Paso 2: la etapa de reproducción aleatoria
Paso 3: la etapa de disminución.
Semánticamente, las fases de mapa y barajado distribuyen los datos, y la etapa de disminución realiza el cálculo. En este post analizaremos en detalle cada una de estas etapas.
[stextbox id=”section”] La etapa del mapa [/stextbox]
La lógica de MapReduce, a diferencia de otros marcos de datos, no se limita a conjuntos de datos estructurados. Además cuenta con una amplia capacidad para manejar datos no estructurados. La etapa del mapa es el paso crítico que lo hace factible. MapperMapper es una herramienta que facilita la visualización y el análisis de datos geoespaciales. Permite a los usuarios crear mapas interactivos y personalizables, integrando información diversa como demografía, infraestructuras y recursos naturales. Su uso se extiende en sectores como la planificación urbana, la investigación ambiental y la gestión de recursos, contribuyendo a la toma de decisiones informadas y al desarrollo sostenible. Mapper se ha convertido en una solución esencial en... aporta una estructura a los datos no estructurados. A modo de ejemplo, si quiero contar la cantidad de fotografías en mi computadora portátil por la ubicación (ciudad), donde se tomó la foto, necesito analizar datos no estructurados. El asignador crea pares (clave, valor) a partir de este conjunto de datos. Para este caso, la clave será la ubicación y el valor será la fotografía. Una vez que el asignador termina con su tarea, tenemos una estructura para todo el conjunto de datos.
En la etapa de mapa, el asignador toma un solo par (clave, valor) como entrada y produce cualquier número de pares (clave, valor) como salida. Es esencial pensar en la operación del mapa como sin estado, dicho de otra forma, su lógica opera en un solo par al mismo tiempo (inclusive si en la práctica se envían varios pares de entrada al mismo asignador). Para resumir, para la etapa de mapa, el usuario simplemente diseña una función de mapa que asigna un par de entrada (clave, valor) a cualquier número (inclusive ninguno) de pares de salida. La mayoría de las veces, la etapa de mapa se utiliza simplemente para especificar la ubicación deseada del valor de entrada cambiando su clave.
[stextbox id=”section”] La etapa de barajar [/stextbox]
La etapa de reproducción aleatoria es manejada automáticamente por el marco MapReduce, dicho de otra forma, el ingeniero no tiene nada que hacer en esta etapa. El sistema subyacente que implementa MapReduce enruta todos los valores asociados con una clave individual al mismo reductor.
[stextbox id=”section”] La etapa Reducir [/stextbox]
En la etapa de disminución, el reductor toma todos los valores asociados con una sola clave k y genera cualquier número de pares (clave, valor). Esto resalta uno de los aspectos secuenciales del cálculo de MapReduce: todos los mapas deben finalizar antes de que pueda comenzar la etapa de disminución. Dado que el reductor tiene acceso a todos los valores con la misma clave, puede realizar cálculos secuenciales sobre estos valores. En el paso de disminución, el paralelismo se explota al observar que los reductores que operan en diferentes teclas pueden ejecutarse simultáneamente. Para resumir, para la etapa de disminución, el usuario diseña una función que toma como entrada una lista de valores asociados con una sola tecla y genera cualquier número de pares. A menudo, las teclas de salida de un reductor son iguales a la tecla de entrada (en realidad, en el papel MapReduce original, la tecla de salida debe igual a la clave de entrada, pero Hadoop relajó esta restricción).
En general, un programa en el paradigma MapReduce puede constar de muchas rondas (de forma general llamadas trabajos) de diferentes funciones de mapa y disminución, hechas secuencialmente una tras otra.
[stextbox id=”section”] Un ejemplo [/stextbox]
Consideremos un ejemplo para comprender Map-Reduce en profundidad. Tenemos las siguientes 3 frases:
1. El zorro marrón veloz
2. El zorro se comió al ratón
3. ¿Cómo ahora vaca marrón
Nuestro objetivo es contar la frecuencia de cada palabra en todas las frases. Imagine que cada una de estas oraciones adquiere una gran cantidad de memoria y, por eso, se asignan a diferentes nodos de datos. Mapper se hace cargo de estos datos no estructurados y crea pares clave-valor. Para este caso, la clave es la palabra y el valor es el recuento de esta palabra en el texto disponible en este nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... de datos. A modo de ejemplo, el nodo 1st Map genera 4 pares clave-valor: (the, 1), (brown, 1), (fox, 1), (quick, 1). Los primeros 3 pares clave-valor van al primer reductor y el último valor clave al segundo reductor.
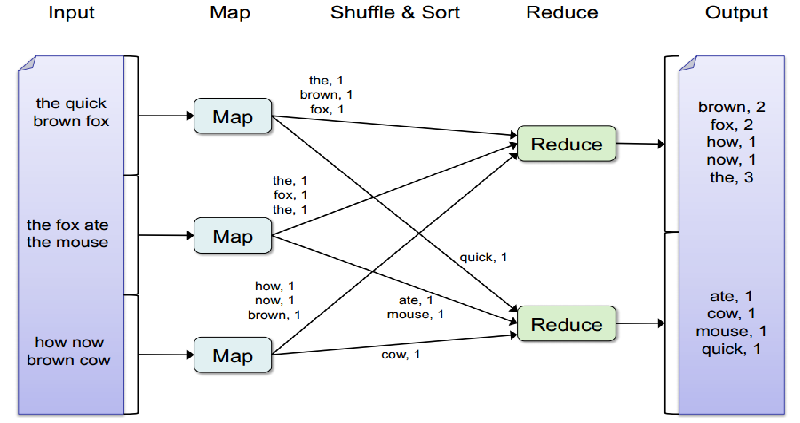
De manera semejante, las funciones de mapa 2 y 3 hacen el mapa de las otras dos oraciones. Al mezclar, todas las palabras similares llegan al mismo final. Una vez que se ordenan los pares clave-valor, la función reductora opera sobre estos datos estructurados para generar un resumen.
[stextbox id=”section”] Notas finales: [/stextbox]
Tomemos un ejemplo del uso de la función Map-Reduce en la industria:
• En el buscador de Google:
– Construcción de índices para la búsqueda de Google
– Agrupación de posts para Google News
– Traducción automática estadística
• ¡En Yahoo !:
– Creación de índices para Yahoo! Buscar
– Detección de spam para Yahoo! Correo
• En Facebook:
– Procesamiento de datos
– Optimización de anuncios
– Ejemplo de detección de spam
• En Amazon:
– Agrupación de productos
– Traducción automática estadística
La restricción de utilizar la función Map-reduce es que el usuario tiene que seguir un formato lógico. Esta lógica es generar pares clave-valor usando la función Mapa y después resumir usando la función Reducir. Pero, por suerte, la mayoría de las operaciones de manipulación de datos se pueden engañar en este formato. En el próximo post tomaremos algunos ejemplos como cómo hacer una fusión de conjuntos de datos, multiplicación de matrices, transposición de matrices, etc. usando Map-Reduce.
¿Le fue útil el post? Comparta con nosotros otros ejemplos prácticos de la función Map-Reduce. Háganos saber su opinión sobre este post en el cuadro a continuación.





