Este artículo se refiere a uno de los algoritmos de clasificación ML supervisados:Algoritmo KNN (K vecinos más cercanos). Es uno de los algoritmos de clasificación más simples y ampliamente utilizados en el que un nuevo punto de datos se clasifica en función de la similitud en el grupo específico de puntos de datos vecinos. Esto da un resultado competitivo.
Laboral
Para un punto de datos dado en el conjunto, los algoritmos encuentran las distancias entre este y todos los demás K números de puntos de datos en el conjunto de datos cerca del punto inicial y votos para la categoría que tiene la mayor frecuencia. Generalmente, distancia euclidiana está tomando como medida de distancia. Por lo tanto, el modelo final resultante son solo los datos etiquetados colocados en un espacio. Este algoritmo es conocido popularmente por varias aplicaciones como genética, previsión, etc. El algoritmo es mejor cuando hay más características presentes y muestra SVM en este caso.
KNN reducir el sobreajuste es un hecho. Por otro lado, es necesario elegir el mejor valor para K. Entonces, ¿cómo elegimos K? Generalmente usamos la raíz cuadrada del número de muestras en el conjunto de datos como valor para K. Se debe encontrar un valor óptimo ya que un valor más bajo puede conducir a un sobreajuste y un valor más alto puede requerir una gran complicación computacional en la distancia. Por lo tanto, el uso de una gráfica de error puede ayudar. Otro método es el método del codo. Puede preferir echar raíces, de lo contrario también puede seguir el método del codo.
Profundicemos en los diferentes pasos de K-NN para clasificar un nuevo punto de datos
Paso 1: Seleccione el valor de K vecinos (digamos k = 5)
Paso 2: Encuentre el punto de datos K (5) más cercano para nuestro nuevo punto de datos basado en la distancia euclidiana (que discutiremos más adelante)
Paso 3: Entre estos K puntos de datos, cuente los puntos de datos en cada categoría.
Paso 4: Asigne el nuevo punto de datos a la categoría que tenga más vecinos de la nuevo punto de datos
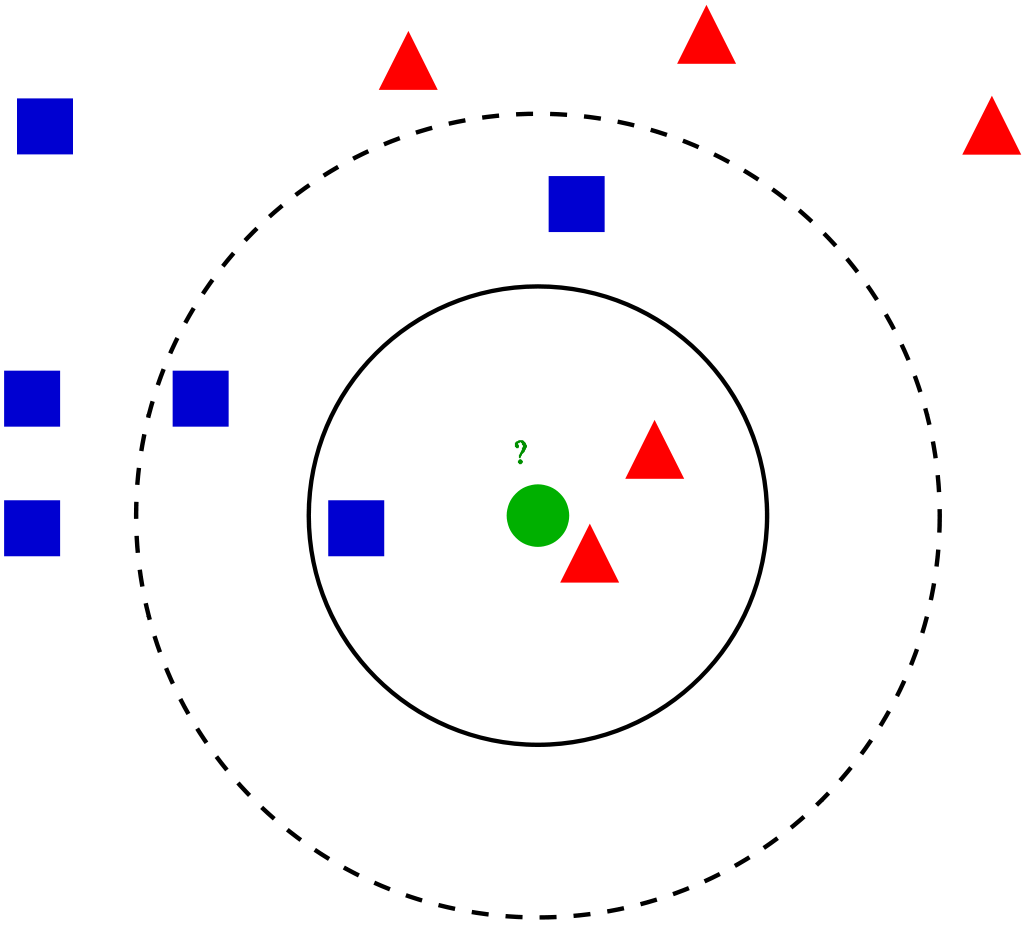
Ejemplo
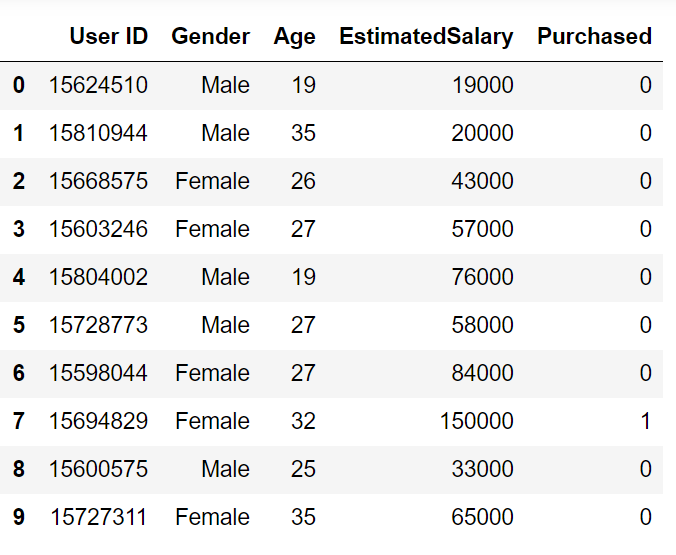
Repasemos un problema de ejemplo para tener una intuición clara sobre la clasificación K-Vecino más cercano. Estamos utilizando el conjunto de datos de anuncios de redes sociales (Descargar). El conjunto de datos contiene los detalles de los usuarios en un sitio de redes sociales para saber si un usuario compra un producto al hacer clic en el anuncio en el sitio en función de su salario, edad y sexo.
Comencemos la programación importando bibliotecas esenciales
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import sklearn
Importar el conjunto de datos y dividirlo en variables independientes y dependientes
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [1, 2, 3]].values
y = dataset.iloc[:, -1].values
Dado que nuestro conjunto de datos contiene variables de caracteres, tenemos que codificarlo usando LabelEncoder
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
X[:,0] = le.fit_transform(X[:,0])
Estamos realizando una prueba de tren dividida en el conjunto de datos. Proporcionamos un tamaño de prueba de 0,20, lo que significa que nuestra muestra de entrenamiento contiene 320 conjuntos de entrenamiento y la muestra de prueba contiene 80 conjuntos de prueba
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0)
A continuación, vamos a realizar un escalado de características al conjunto de entrenamiento y prueba de variables independientes para reducir el tamaño a valores más pequeños.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
Ahora tenemos que crear y entrenar el modelo K Vecino más cercano con el conjunto de entrenamiento
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors = 5, metric="minkowski", p = 2)
classifier.fit(X_train, y_train)
Estamos usando 3 parámetros en la creación del modelo. n_neighbors se establece en 5, lo que significa que se requieren 5 puntos de vecindario para clasificar un punto dado. La métrica de distancia que estamos usando es Minkowski, la ecuación para ella se da a continuación
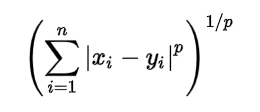
Según la ecuación, también tenemos que seleccionar el valor p.
p = 1, Distancia de Manhattan
p = 2, distancia euclidiana
p = infinito, distancia de Cheybchev
En nuestro problema, elegimos p como 2 (también u puede elegir la métrica como «euclidiana»)
Se crea nuestro modelo, ahora tenemos que predecir la salida para el conjunto de prueba
y_pred = classifier.predict(X_test)
Comparación de valor verdadero y predicho:
y_prueba
array([0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1,
0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1,
0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1,
1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1], dtype=int64)
y_pred
array([0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1,
0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1,
0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1,
1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1], dtype=int64)
Podemos evaluar nuestro modelo usando la matriz de confusión y la puntuación de precisión comparando los valores de prueba predichos y reales
from sklearn.metrics import confusion_matrix,accuracy_score
cm = confusion_matrix(y_test, y_pred)
ac = accuracy_score(y_test,y_pred)
matriz de confusión –
[[64 4] [ 3 29]]
la precisión es 0,95
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, -1].values
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0)
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# Training the K-NN model on the Training set
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors = 5, metric="minkowski", p = 2)
classifier.fit(X_train, y_train)
# Predicting the Test set results
y_pred = classifier.predict(X_test)
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
ac = accuracy_score(y_test, y_pred)
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





