Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
Y aprendemos en el camino.
Las empresas, de manera similar, aplican su aprendizaje pasado a la toma de decisiones relacionadas con las operaciones y las nuevas iniciativas, por ejemplo, relacionadas con la clasificación de clientes, productos, etc. Sin embargo, aquí se vuelve un poco más complejo ya que hay múltiples partes interesadas involucradas. Además, las decisiones deben ser precisas debido a su impacto más amplio.
Con la evolución de la tecnología digital, los seres humanos han desarrollado múltiples activos; las máquinas son una de ellas. Hemos aprendido (y continuamos) a usar máquinas para analizar datos usando estadísticas para generar información útil que sirve como ayuda para tomar decisiones y pronósticos.
Las máquinas no hacen magia con datos, sino que aplican estadísticas simples.
En este contexto, revisemos un par de algoritmos de aprendizaje automático que se usan comúnmente para la clasificación e intentemos comprender cómo funcionan y se comparan entre sí. Pero primero, entendamos algunos conceptos relacionados.
Conceptos básicos
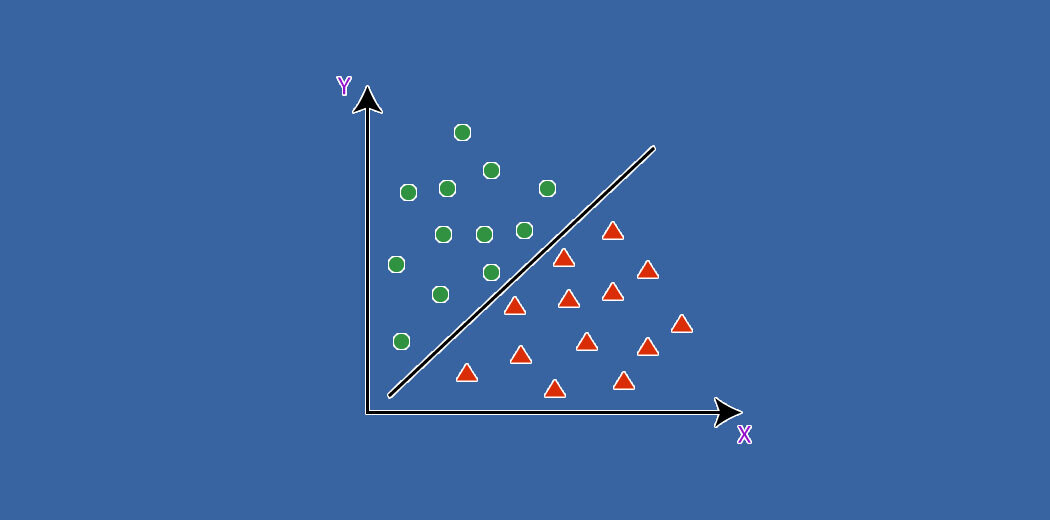
El aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en... se define como la categoría de análisis de datos donde el resultado objetivo es conocido o etiquetado, por ejemplo, si el cliente o los clientes compraron un producto o no. Sin embargo, cuando la intención es agruparlos en función de lo que todos compraron, entonces se convierte en Sin supervisión. Esto se puede hacer para explorar la relación entre los clientes y lo que compran.
Tanto la clasificación como la regresión pertenecen al aprendizaje supervisado, pero la primera se aplica cuando el resultado es finito, mientras que la última es para infinitos valores posibles de resultado (por ejemplo, predecir el valor en dólares de la compra).
La distribución normal es la conocida distribución en forma de campana de una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... continua. Ésta es una extensión natural de los valores que toma normalmente un parámetro.
Dado que los predictores pueden tener diferentes rangos de valores, por ejemplo, el peso humano puede ser de hasta 150 (kg), pero la altura típica es sólo de hasta 6 (pies); los valores necesitan escala (alrededor de la media respectiva) para hacerlos comparables.
La colinealidad es cuando dos o más predictores están relacionados, es decir, sus valores se mueven juntos.
Los valores atípicos son valores excepcionales de un predictor, que pueden ser ciertos o no.
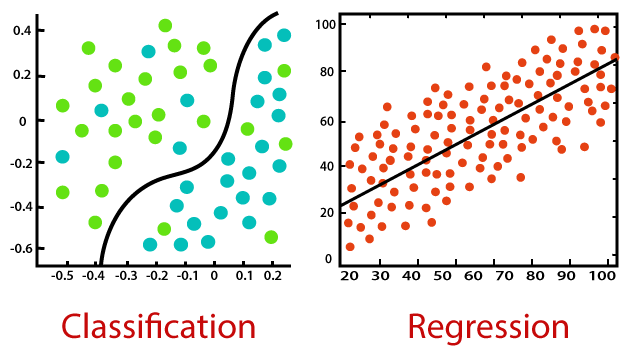
Regresión logística
La regresión logística utiliza el poder de la regresión para realizar la clasificación y lo ha estado haciendo muy bien durante varias décadas, para permanecer entre los modelos más populares. Una de las principales razones del éxito del modelo es su poder de explicabilidad, es decir, señalar la contribución de los predictores individuales, cuantitativamente.
A diferencia de la regresión que usa mínimos cuadrados, el modelo usa la probabilidad máxima para ajustar una curva sigmoidea en la distribución de la variable objetivo.
Dada la susceptibilidad del modelo a la multicolinealidad, aplicarlo paso a paso resulta ser un mejor enfoque para finalizar los predictores elegidos del modelo.
El algoritmo es una opción popular en muchas tareas de procesamiento del lenguaje natural, por ejemplo, detección de habla tóxica, clasificación de temas, etc.
Redes neuronales artificiales
Las redes neuronales artificiales (ANN), llamadas así porque intentan imitar el cerebro humano, son adecuadas para conjuntos de datos grandes y complejos. Su estructura se compone de capas de nodos intermedios (similares a las neuronas) que se asignan juntas a las múltiples entradas y la salida de destino.
Es un algoritmo de autoaprendizaje, ya que comienza con un mapeo inicial (aleatorio) y, a partir de entonces, autoajusta iterativamente los pesos relacionados para ajustar con precisión la salida deseada para todos los registros. Las múltiples capas brindan una capacidad de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... para poder extraer características de nivel superior de los datos sin procesar.
El algoritmo proporciona una alta precisión de predicción, pero es necesario escalar características numéricas. Tiene amplias aplicaciones en campos futuros que incluyen visión artificial, PNL, reconocimiento de voz, etc.

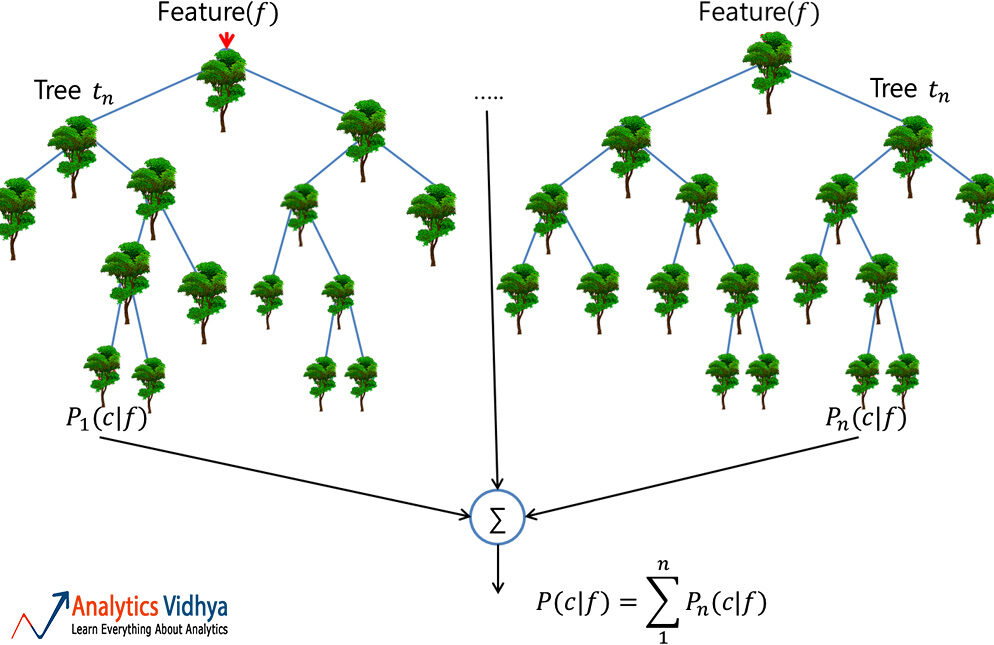
Bosque aleatorio
Un bosque aleatorio es un conjunto confiable de múltiples árboles de decisión (o CART); aunque más popular para la clasificación que las aplicaciones de regresión. Aquí, los árboles individuales se construyen mediante ensacado (es decir, agregación de bootstraps que no son más que múltiples conjuntos de datos de trenes creados mediante muestreo de registros con reemplazo) y se dividen usando menos características. El bosque diverso resultante de árboles no correlacionados exhibe una variación reducida; por lo tanto, es más robusto frente al cambio de datos y traslada su precisión de predicción a nuevos datos.
Sin embargo, el algoritmo no funciona bien para conjuntos de datos que tienen muchos valores atípicos, algo que debe abordarse antes de la construcción del modelo.
Tiene amplias aplicaciones en los campos financiero, minorista, aeronáutico y muchos otros.
Bayes ingenuo
Si bien es posible que no nos demos cuenta de esto, ¡este es el algoritmo que se usa más comúnmente para filtrar correos electrónicos no deseados!
Aplica lo que se conoce como probabilidad posterior usando el Teorema de Bayes para hacer la categorización de los datos no estructurados. Y al hacerlo, asume ingenuamente que los predictores son independientes, lo que puede no ser cierto.
El modelo funciona bien con un pequeño conjunto de datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina...., siempre que estén presentes todas las clases del predictor categórico.
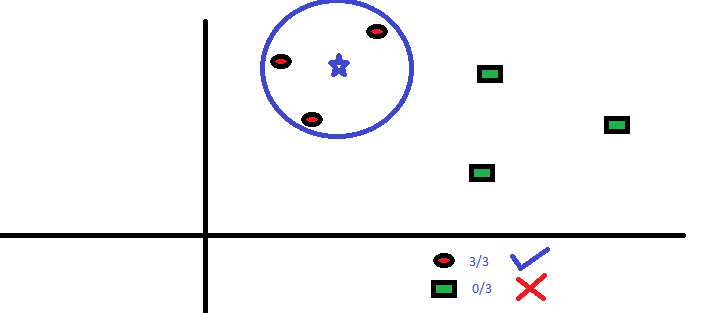
KNN
El algoritmo K-Nemost Neighbor (KNN) predice basándose en el número especificado (k) de los puntos de datos vecinos más cercanos. Aquí, el preprocesamiento de los datos es significativo ya que afecta directamente las mediciones de distancia. A diferencia de otros, el modelo no tiene fórmula matemática, ni capacidad descriptiva.
Aquí, el parámetro ‘k’ debe elegirse sabiamente; ya que un valor más bajo que el óptimo conduce a un sesgo, mientras que un valor más alto afecta la precisión de la predicción.
Es un modelo simple y bastante preciso que se prefiere principalmente para conjuntos de datos más pequeños, debido a los enormes cálculos involucrados en los predictores continuos.
En un nivel simple, KNN puede usarse en un entorno predictor bivariado, por ejemplo, altura y peso, para determinar el sexo dada una muestra.
Poniendolo todo junto
El rendimiento de un modelo depende principalmente de la naturaleza de los datos. Dado que los conjuntos de datos comerciales tienen múltiples predictores y son complejos, es difícil identificar un algoritmo que siempre funcione bien. Por lo tanto, la práctica habitual es probar varios modelos y encontrar el adecuado.
Como comparación de alto nivel, los aspectos más destacados que se encuentran generalmente para cada uno de los algoritmos anteriores se anotan a continuación en algunos parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... comunes; para que sirva como instantánea de referencia rápida.
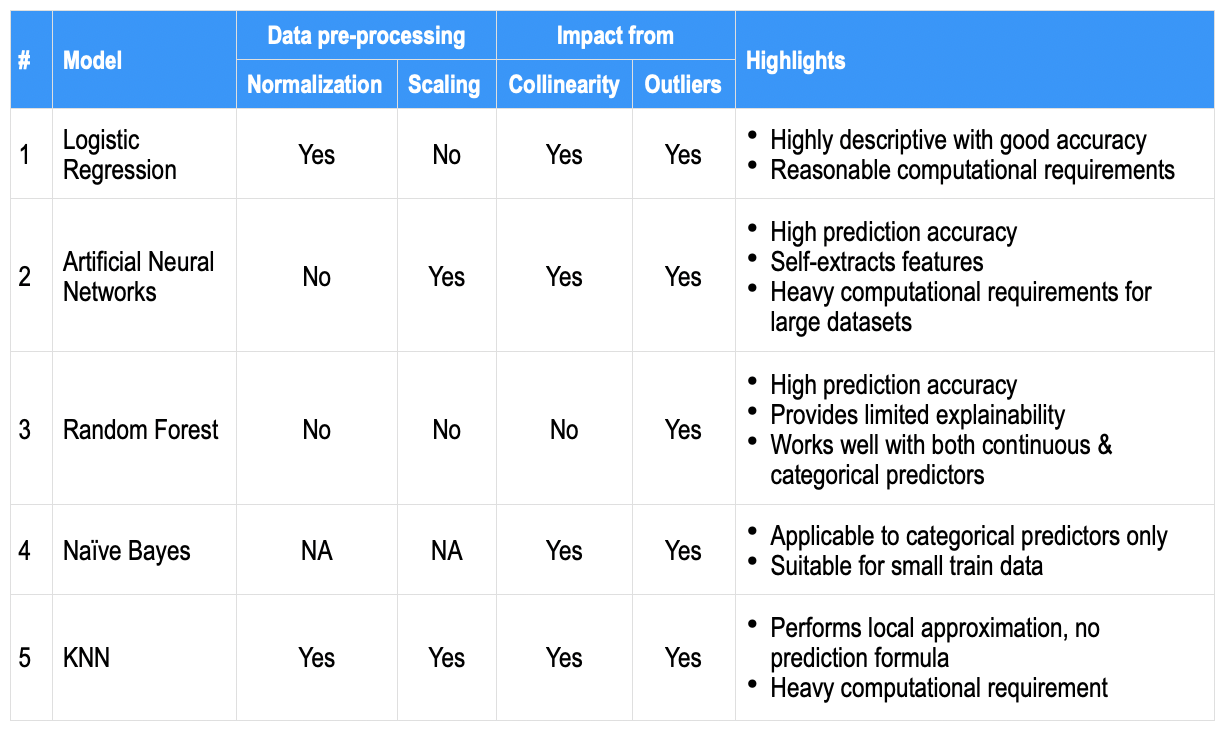
Además, existen múltiples palancas, por ejemplo, equilibrio de datos, imputación, validación cruzada, conjunto entre algoritmos, conjunto de datos de trenes más grande, etc. además del ajuste de hiperparámetros del modelo, que pueden utilizarse para ganar precisión. Si bien la precisión de la predicción puede ser lo más deseable, las empresas también buscan los predictores destacados que contribuyen (es decir, un modelo descriptivo o su explicabilidad resultante).
Finalmente, el aprendizaje automático permite a los humanos decidir cuantitativamente, predecir y mirar más allá de lo obvio, aunque a veces también en aspectos previamente desconocidos.





