En la era de Big Data, Python se ha convertido en el lenguaje más buscado. En este artículo, concentrémonos en un aspecto particular de Python que lo convierte en uno de los lenguajes de programación más poderosos: el multiprocesamiento.
Ahora, antes de sumergirnos en lo esencial del multiprocesamiento, le sugiero que lea mi artículo anterior sobre Threading en Python, ya que puede proporcionar un mejor contexto para el artículo actual.
Supongamos que eres un estudiante de primaria a quien se le ha encomendado la abrumadora tarea de multiplicar 1200 pares de números como tarea. Supongamos que es capaz de multiplicar un par de números en 3 segundos. Luego, en total, se necesitan 1200 * 3 = 3600 segundos, que es 1 hora para resolver toda la tarea. Pero tienes que ponerte al día con tu programa de televisión favorito en 20 minutos.
¿Qué harías? Un estudiante inteligente, aunque deshonesto, llamará a tres amigos más que tienen una capacidad similar y dividirá la tarea. Entonces tendrás 250 tareas de multiplicaciones en tu plato, que completarás en 250 * 3 = 750 segundos, es decir, 15 minutos. Por lo tanto, usted, junto con sus otros 3 amigos, finalizará la tarea en 15 minutos, dándole 5 minutos de tiempo para tomar un refrigerio y sentarse a ver su programa de televisión. La tarea solo tomó 15 minutos cuando 4 de ustedes trabajaron juntos, lo que de otra manera habría tomado 1 hora.
Esta es la ideología básica del multiprocesamiento. Si tiene un algoritmo que se puede dividir en diferentes trabajadores (procesadores), entonces puede acelerar el programa. Hoy en día, las máquinas vienen con 4,8 y 16 núcleos, que luego se pueden implementar en paralelo.
Procesamiento múltiple en ciencia de datos
El multiprocesamiento tiene dos aplicaciones cruciales en la ciencia de datos.
1. Procesos de entrada-salida
Cualquier canalización de datos intensivos tiene procesos de entrada y salida en los que millones de bytes de datos fluyen por todo el sistema. Por lo general, el proceso de lectura (entrada) de datos no llevará mucho tiempo, pero el proceso de escritura de datos en los almacenes de datos lleva mucho tiempo. El proceso de escritura se puede realizar en paralelo, ahorrando una gran cantidad de tiempo.
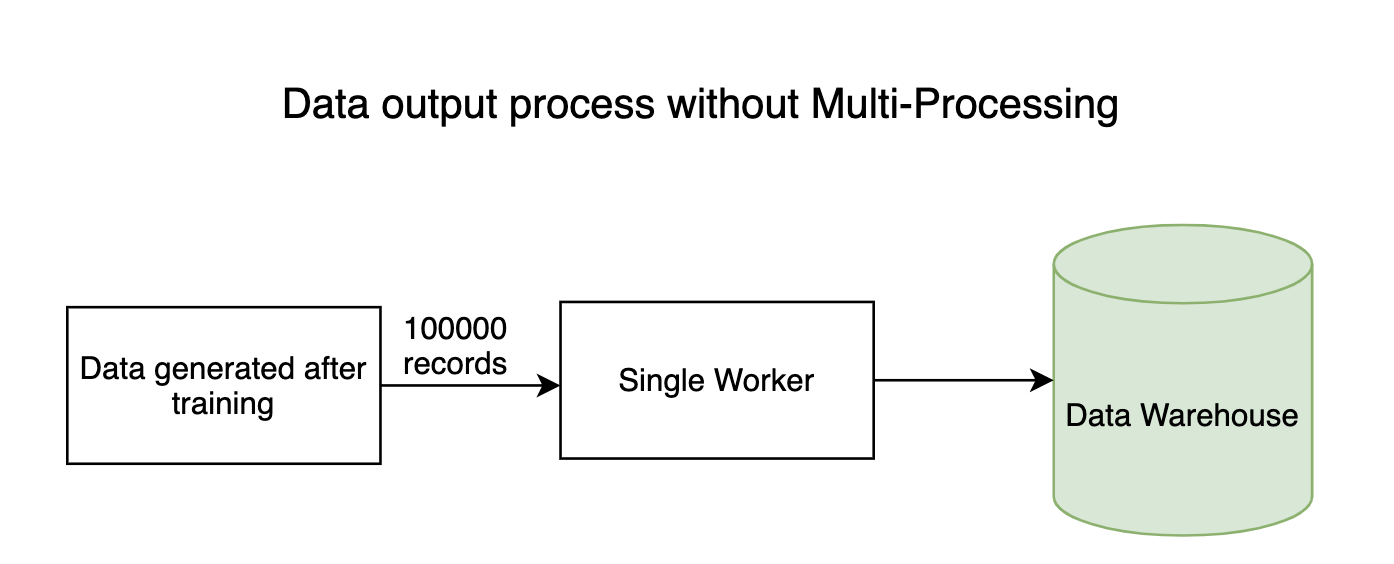
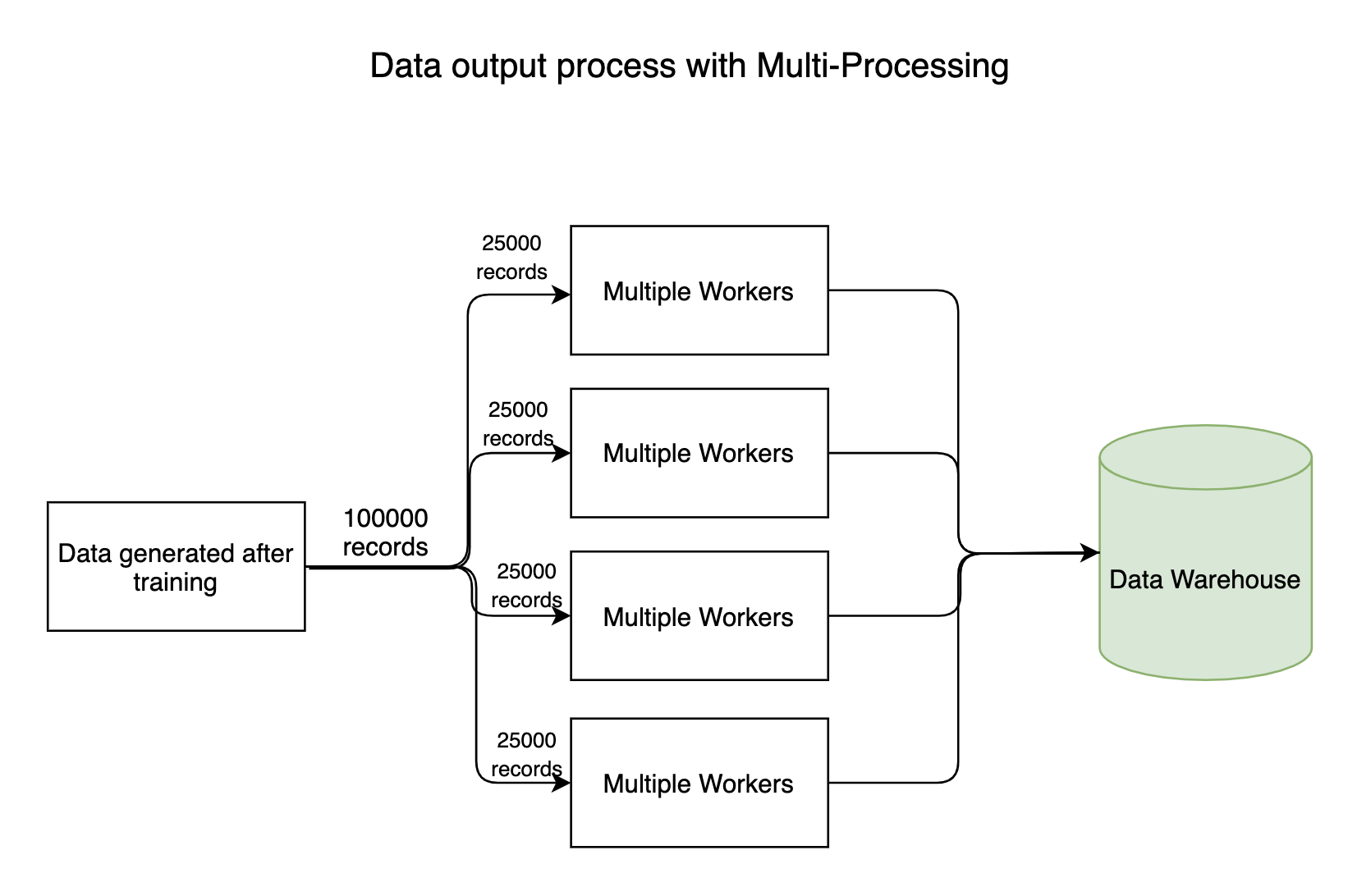
2. Modelos de formación
Aunque no todos los modelos se pueden entrenar en paralelo, pocos modelos tienen características inherentes que les permitan entrenarse mediante el procesamiento en paraleloEl procesamiento en paralelo es una técnica que permite ejecutar múltiples operaciones simultáneamente, dividiendo tareas complejas en subtareas más pequeñas. Esta metodología optimiza el uso de recursos computacionales y reduce el tiempo de procesamiento, siendo especialmente útil en aplicaciones como el análisis de grandes volúmenes de datos, simulaciones y renderización gráfica. Su implementación se ha vuelto esencial en sistemas de alto rendimiento y en la computación moderna..... Por ejemplo, el algoritmo Random Forest implementa varios árboles de decisión para tomar una decisión acumulativa. Estos árboles se pueden construir en paralelo. De hecho, la API de sklearn viene con un parámetro llamado n_jobs, que ofrece una opción para utilizar varios trabajadores.
Procesamiento múltiple en Python usando Proceso clase-
Ahora pongamos nuestras manos en el multiprocesamiento biblioteca en Python.
Eche un vistazo al siguiente código
import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
sleepy_man()
sleepy_man()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
El código anterior es simple. La función hombre_soñoliento duerme por un segundo y llamamos a la función dos veces. Registramos el tiempo necesario para las dos llamadas a funciones e imprimimos los resultados. La salida es como se muestra a continuación.
Starting to sleep Done sleeping Starting to sleep Done sleeping Done in 2.0037 seconds
Esto se espera ya que llamamos a la función dos veces y registramos el tiempo. El flujo se muestra en el diagrama siguiente.
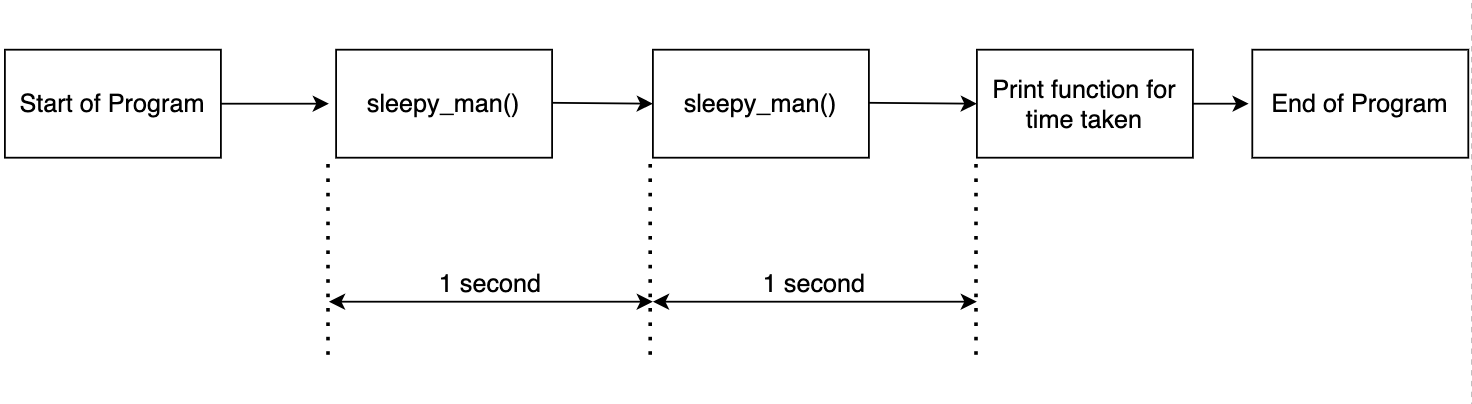
Ahora incorporemos multiprocesamiento en el código.
import multiprocessing import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
p1 = multiprocessing.Process(target= sleepy_man)
p2 = multiprocessing.Process(target= sleepy_man)
p1.start()
p2.start()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
Aquí multiprocesamiento.Proceso (target = sleepy_man) define una instancia multiproceso. Pasamos la función requerida para ser ejecutada, hombre_soñoliento, como argumento. Activamos las dos instancias por p1.start ().
La salida es la siguiente:
Done in 0.0023 seconds Starting to sleep Starting to sleep Done sleeping Done sleeping
Ahora note una cosa. La declaración de impresión del registro de tiempo se ejecutó primero. Esto se debe a que, junto con las instancias multiproceso activadas para el hombre_soñoliento función, el código principal de la función se ejecutó por separado en paralelo. El diagrama de flujo que se muestra a continuación aclarará las cosas.
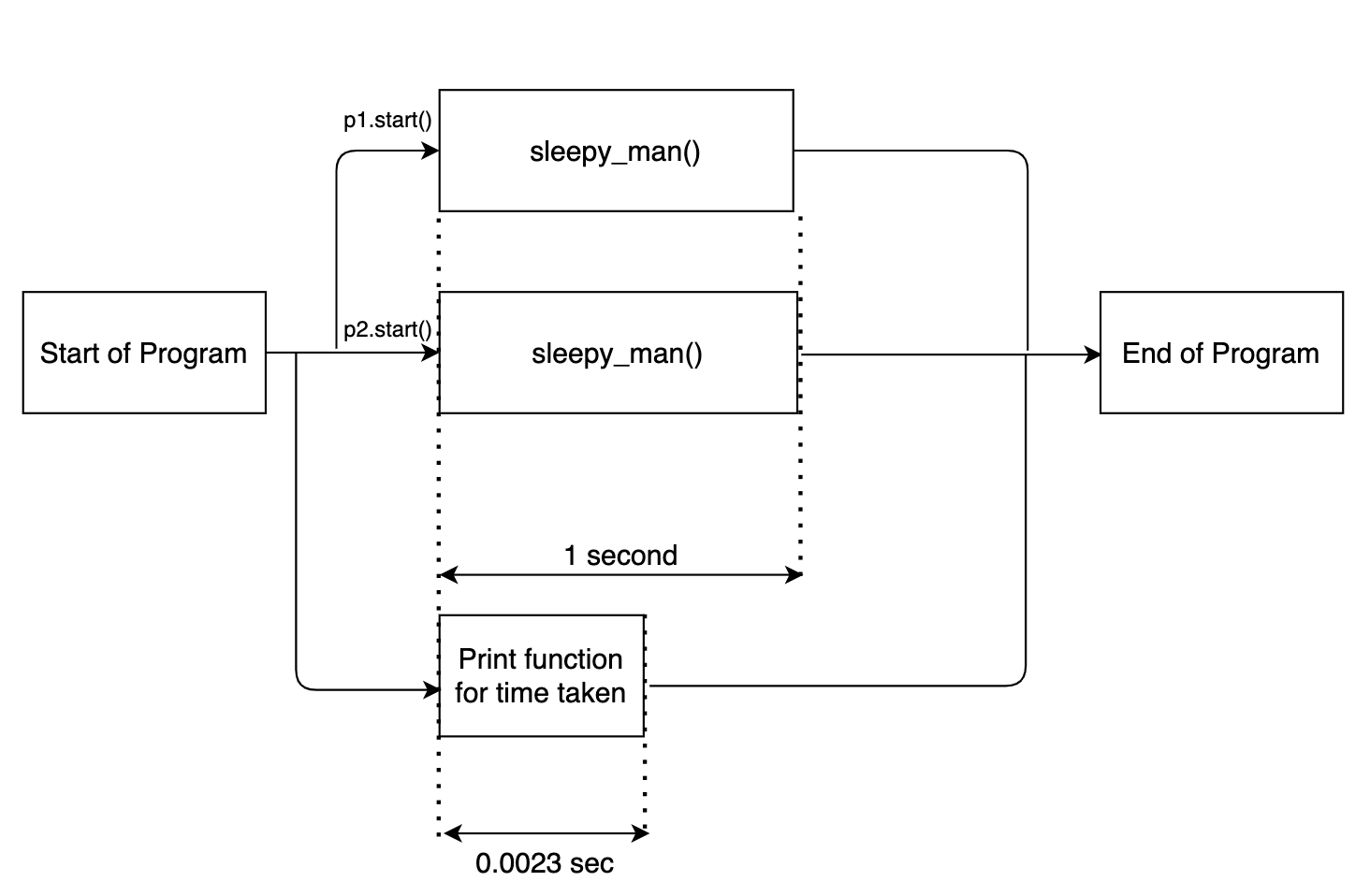
Para ejecutar el resto del programa después de que se ejecuten las funciones multiproceso, necesitamos ejecutar la función entrar().
import multiprocessing
import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
p1 = multiprocessing.Process(target= sleepy_man)
p2 = multiprocessing.Process(target= sleepy_man)
p1.start()
p2.start()
p1.join()
p2.join()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
Ahora, el resto del bloque de código solo se ejecutará después de que se realicen las tareas de multiprocesamiento. La salida se muestra a continuación.
Starting to sleep Starting to sleep Done sleeping Done sleeping Done in 1.0090 seconds
El diagrama de flujo se muestra a continuación.
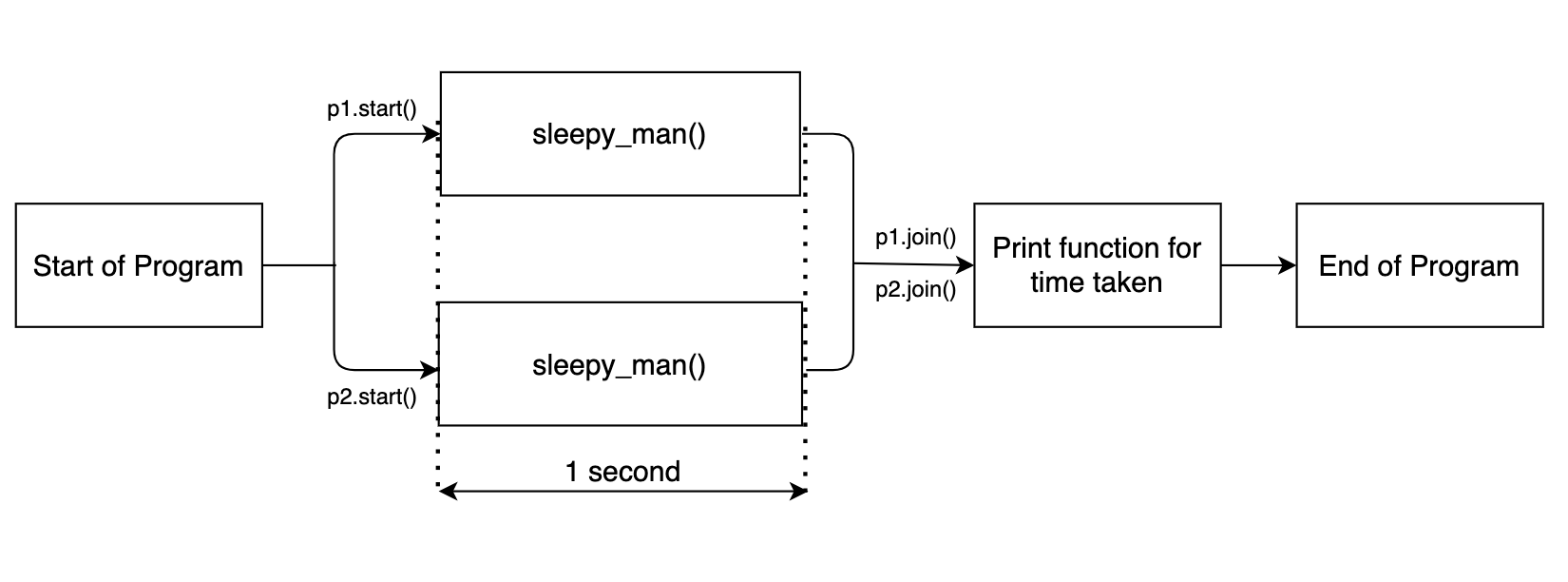
Dado que las dos funciones de suspensión se ejecutan en paralelo, la función en conjunto toma alrededor de 1 segundo.
Podemos definir cualquier número de instancias de multiprocesamiento. Mira el código a continuación. Define 10 instancias de multiprocesamiento diferentes utilizando un bucle for a.
import multiprocessing
import time
def sleepy_man():
print('Starting to sleep')
time.sleep(1)
print('Done sleeping')
tic = time.time()
process_list = []
for i in range(10):
p = multiprocessing.Process(target= sleepy_man)
p.start()
process_list.append(p)
for process in process_list:
process.join()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
La salida del código anterior se muestra a continuación.
Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done in 1.0117 seconds
Aquí, las diez ejecuciones de funciones se procesan en paralelo y, por lo tanto, todo el programa toma solo un segundo. Ahora mi máquina no tiene 10 procesadores. Cuando definimos más procesos que nuestra máquina, la biblioteca de multiprocesamiento tiene una lógica para programar los trabajos. Así que no tienes que preocuparte por eso.
También podemos pasar argumentos a la Proceso función usando argumentos.
import multiprocessing
import time
def sleepy_man(sec):
print('Starting to sleep')
time.sleep(sec)
print('Done sleeping')
tic = time.time()
process_list = []
for i in range(10):
p = multiprocessing.Process(target= sleepy_man, args = [2])
p.start()
process_list.append(p)
for process in process_list:
process.join()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
La salida del código anterior se muestra a continuación.
Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Starting to sleep Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done sleeping Done in 2.0161 seconds
Dado que pasamos un argumento, el hombre_soñoliento función durmió durante 2 segundos en lugar de 1 segundo.
Procesamiento múltiple en Python usando Piscina clase-
En el último fragmento de código, ejecutamos 10 procesos diferentes usando un bucle for a. En lugar de eso, podemos usar el Piscina método para hacer lo mismo.
import multiprocessing
import time
def sleepy_man(sec):
print('Starting to sleep for {} seconds'.format(sec))
time.sleep(sec)
print('Done sleeping for {} seconds'.format(sec))
tic = time.time()
pool = multiprocessing.Pool(5)
pool.map(sleepy_man, range(1,11))
pool.close()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
multiprocesamiento Piscina (5) define el número de trabajadores. Aquí definimos el número como 5. pool.map () es el método que desencadena la ejecución de la función. Llamamos pool.map (hombre_soñoliento, rango (1,11)). Aquí, hombre_soñoliento es la función que se llamará con los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... para las ejecuciones de funciones definidas por rango (1,11) (generalmente se pasa una lista). La salida es la siguiente:
Starting to sleep for 1 seconds Starting to sleep for 2 seconds Starting to sleep for 3 seconds Starting to sleep for 4 seconds Starting to sleep for 5 seconds Done sleeping for 1 seconds Starting to sleep for 6 seconds Done sleeping for 2 seconds Starting to sleep for 7 seconds Done sleeping for 3 seconds Starting to sleep for 8 seconds Done sleeping for 4 seconds Starting to sleep for 9 seconds Done sleeping for 5 seconds Starting to sleep for 10 seconds Done sleeping for 6 seconds Done sleeping for 7 seconds Done sleeping for 8 seconds Done sleeping for 9 seconds Done sleeping for 10 seconds Done in 15.0210 seconds
Piscina class es una mejor manera de implementar multiprocesamiento porque distribuye las tareas a los procesadores disponibles utilizando el programa Primero en entrar, primero en salir. Es casi similar a la arquitectura map-reduce, en esencia, asigna la entrada a diferentes procesadores y recopila la salida de todos los procesadores como una lista. Los procesos en ejecución se almacenan en la memoria y otros procesos que no se ejecutan se almacenan fuera de la memoria.
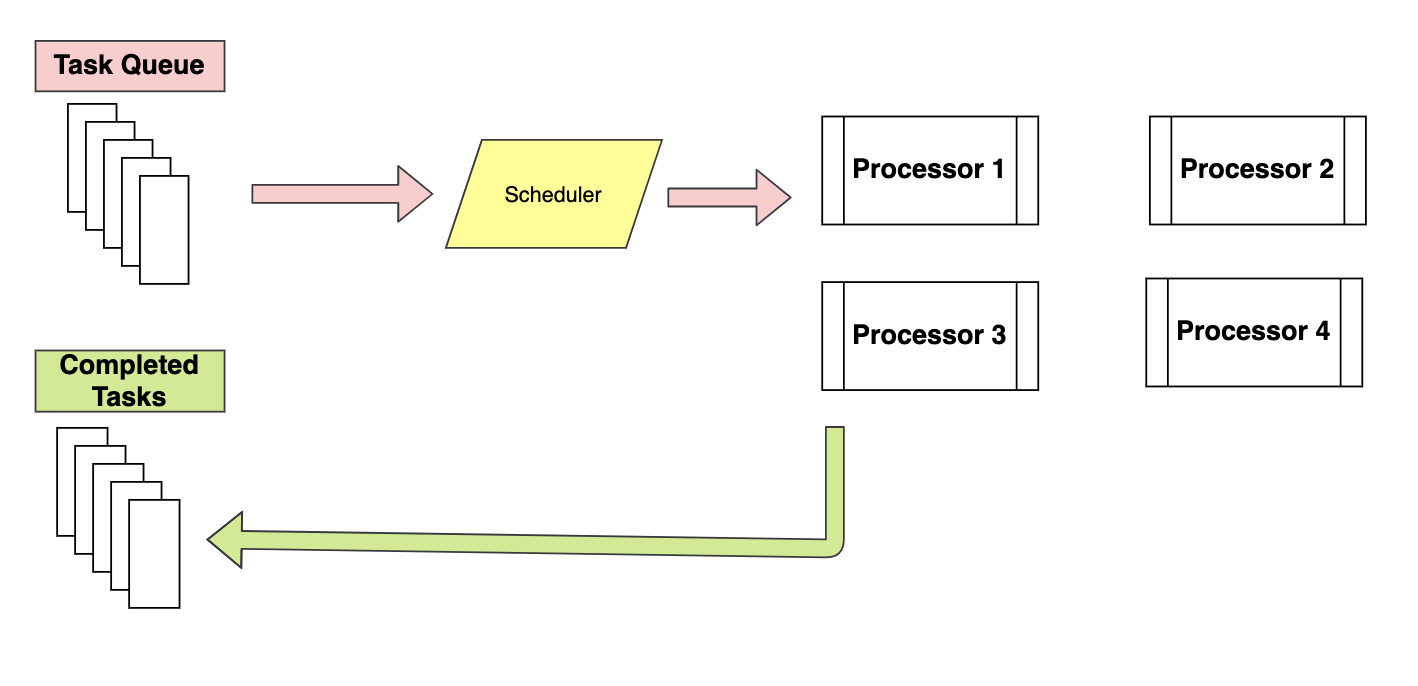
Mientras en Proceso clase, todos los procesos se ejecutan en memoria y se programan la ejecución mediante la política FIFO.
Comparando el desempeño del tiempo para calcular números perfectos-
Hasta ahora, jugamos con multiprocesamiento funciones en dormir funciones. Ahora tomemos una función que verifica si un número es un Número Perfecto o no. Para aquellos que no lo saben, un número es un número perfecto si la suma de sus divisores positivos es igual al número en sí. Enumeraremos los números perfectos menores o iguales que 100000. Lo implementaremos de 3 formas: usando un bucle for regular, usando multiprocess.Process () y multiprocess.Pool ().
Usando un regular para un bucle
import time
def is_perfect(n):
sum_factors = 0
for i in range(1, n):
if (n % i == 0):
sum_factors = sum_factors + i
if (sum_factors == n):
print('{} is a Perfect number'.format(n))
tic = time.time()
for n in range(1,100000):
is_perfect(n)
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
El resultado del programa anterior se muestra a continuación.
6 is a Perfect number 28 is a Perfect number 496 is a Perfect number 8128 is a Perfect number Done in 258.8744 seconds
Usando una clase de proceso
import time
import multiprocessing
def is_perfect(n):
sum_factors = 0
for i in range(1, n):
if(n % i == 0):
sum_factors = sum_factors + i
if (sum_factors == n):
print('{} is a Perfect number'.format(n))
tic = time.time()
processes = []
for i in range(1,100000):
p = multiprocessing.Process(target=is_perfect, args=(i,))
processes.append(p)
p.start()
for process in processes:
process.join()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
El resultado del programa anterior se muestra a continuación.
6 is a Perfect number 28 is a Perfect number 496 is a Perfect number 8128 is a Perfect number Done in 143.5928 seconds
Como pudo ver, logramos una reducción del 44,4% en el tiempo cuando implementamos multiprocesamiento usando Proceso class, en lugar de un bucle for regular.
Usando una clase Pool
import time
import multiprocessing
def is_perfect(n):
sum_factors = 0
for i in range(1, n):
if(n % i == 0):
sum_factors = sum_factors + i
if (sum_factors == n):
print('{} is a Perfect number'.format(n))
tic = time.time()
pool = multiprocessing.Pool()
pool.map(is_perfect, range(1,100000))
pool.close()
toc = time.time()
print('Done in {:.4f} seconds'.format(toc-tic))
El resultado del programa anterior se muestra a continuación.
6 is a Perfect number 28 is a Perfect number 496 is a Perfect number 8128 is a Perfect number Done in 74.2217 seconds
Como puede ver, en comparación con un bucle for regular, logramos una reducción del 71,3% en el tiempo de cálculo, y en comparación con el Proceso clase, logramos una reducción del 48,4% en el tiempo de cálculo.
Por lo tanto, es muy evidente que al implementar un método adecuado desde el multiprocesamiento biblioteca, podemos lograr una reducción significativa en el tiempo de cálculo.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





