
¡Los 7 libros imprescindibles para el aprendizaje profundo!
Este artículo fue publicado como parte del Blogatón de ciencia de datos “Algunas cosas nunca cambian, su esencia y aportes siguen siendo los mismos hasta
Este artículo fue publicado como parte del Blogatón de ciencia de datos “Algunas cosas nunca cambian, su esencia y aportes siguen siendo los mismos hasta

Este artículo fue publicado como parte del Blogatón de ciencia de datos. Introducción Pasos para su primer proyecto de ciencia de datos En este artículo,

Este post fue difundido como parte del Blogatón de ciencia de datos. Visión general Introducción Apache Spark es un marco de procesamiento de datos que

Este artículo fue publicado como parte del Blogatón de ciencia de datos. ¿Qué es el análisis de sentimiento? El inicio y el rápido desarrollo del

Este artículo fue publicado como parte del Blogatón de ciencia de datos. ¿Qué es un modelo estadístico? «El modelado es un arte, así como una
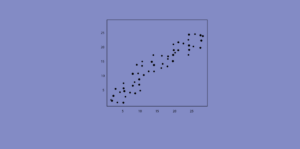
Este artículo fue publicado como parte del Blogatón de ciencia de datos. Introducción Regresión lineal: Figura 1.0: Visualización del modelo de regresión lineal básica El
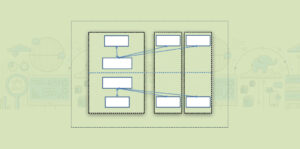
Visión general Familiarícese con el sistema de archivos distribuido de Hadoop (HDFS) Comprender los componentes de HDFS Introducción En la actualidad, es habitual tratar con
Este artículo fue publicado como parte del Blogatón de ciencia de datos Introducción , o «Colab» para abreviar, son Jupyter Notebooks alojados por Google que
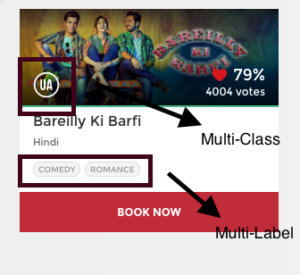
Introducción Por alguna razón, los problemas de regresión y clasificación acaban acaparando la mayor parte de la atención en el mundo del aprendizaje automático. La

En este artículo, aprenderemos cómo podemos manejar variables de categorías múltiples utilizando la técnica de ingeniería de funciones One Hot Encoding. Pero antes de continuar,



