En el artículo anterior, discutimos el ecosistema de Hadoop (enlace). También hablamos sobre las dos herramientas de Hadoop más utilizadas, es decir, PIGEl cerdo, un mamífero domesticado de la familia Suidae, es conocido por su versatilidad en la agricultura y la producción de alimentos. Originario de Asia, su cría se ha extendido por todo el mundo. Los cerdos son omnívoros y poseen una alta capacidad de adaptación a diversos hábitats. Además, juegan un papel importante en la economía, proporcionando carne, cuero y otros productos derivados. Su inteligencia y comportamiento social también son... y HIVEHive es una plataforma de redes sociales descentralizada que permite a sus usuarios compartir contenido y conectar con otros sin la intervención de una autoridad central. Utiliza tecnología blockchain para garantizar la seguridad y la propiedad de los datos. A diferencia de otras redes sociales, Hive permite a los usuarios monetizar su contenido a través de recompensas en criptomonedas, lo que fomenta la creación y el intercambio activo de información..... Ambos idiomas tienen sus seguidores y no existe una preferencia específica entre los dos, en general. Sin embargo, en los casos en los que el equipo que utiliza estas herramientas está más orientado a la programación, a veces se elige PIG por encima de HIVE, ya que les da más libertad durante la codificación. En los casos en que el equipo no sea muy experto en programación, HIVE probablemente sea una mejor opción, dada su similitud con las consultas SQL. Las consultas sobre PIG están escritas en PIG latin. En este artículo le presentaremos PIG Latin utilizando un sencillo ejemplo práctico.
Instalación de PIG
El motor PIG opera en el servidor del cliente. Es simplemente un intérprete que convierte su código simple en operaciones complejas de reducción de mapas. Este mapreduceMapReduce es un modelo de programación diseñado para procesar y generar grandes conjuntos de datos de manera eficiente. Desarrollado por Google, este enfoque Divide el trabajo en tareas más pequeñas, las cuales se distribuyen entre múltiples nodos en un clúster. Cada nodo procesa su parte y luego se combinan los resultados. Este método permite escalar aplicaciones y manejar volúmenes masivos de información, siendo fundamental en el mundo del Big Data.... ahora se maneja en la red distribuida de Hadoop. Tenga en cuenta que toda la red ni siquiera sabrá que la consulta se ejecutó desde un motor PIG. PIG solo permanece en la interfaz de usuario y está destinado a facilitar al usuario la codificación.

Siga los siguientes pasos en su shell para instalar PIG:
Para instalar sistemas compatibles con Pig On Red Hat:
$ sudo yum install pig
Para instalar Pig en sistemas SLES:
$ sudo zypper install pig
Para instalar Pig en Ubuntu y otros sistemas Debian:
$ sudo apt-get install pig
Si está pensando en ejecutar Pig en Windows, solo debería hacer que una máquina virtual se ejecute en Linux y luego trabajar en ella. Puede utilizar VMWare Player u Oracle VirtualBox para iniciar uno.
Después de instalar el paquete PIG, puede comenzar con el grunt shell.
To start the Grunt Shell (MRv1):
$ export PIG_CONF_DIR=/usr/lib/pig/conf $ export PIG_CLASSPATH=/usr/lib/hbase/hbase-0.94.2-cdh4.2.1-security.jar:/usr/lib/ zookeeper"Zookeeper" es un videojuego de simulación lanzado en 2001, donde los jugadores asumen el rol de un cuidador de zoológico. La misión principal consiste en gestionar y cuidar diversas especies de animales, asegurando su bienestar y la satisfacción de los visitantes. A lo largo del juego, los usuarios pueden diseñar y personalizar su zoológico, enfrentando desafíos que incluyen la alimentación, el hábitat y la salud de los animales..../zookeeper-3.4.5-cdh4.2.1.jar $ pig 2012-02-08 23:39:41,819 [main] INFO org.apache.pig.Main - Logging error messages to: /home/arvind/pig-0.9.2-cdh4b1/bin/pig_1328773181817.log 2012-02-08 23:39:41,994 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to hadoop file system at: hdfsHDFS, o Sistema de Archivos Distribuido de Hadoop, es una infraestructura clave para el almacenamiento de grandes volúmenes de datos. Diseñado para ejecutarse en hardware común, HDFS permite la distribución de datos en múltiples nodos, garantizando alta disponibilidad y tolerancia a fallos. Su arquitectura se basa en un modelo maestro-esclavo, donde un nodo maestro gestiona el sistema y los nodos esclavos almacenan los datos, facilitando el procesamiento eficiente de información...://localhost/ ... grunt> To start the Grunt Shell (YARNYARN es un gestor de paquetes para JavaScript que permite la instalación y gestión eficiente de dependencias en proyectos de desarrollo. Desarrollado por Facebook, se caracteriza por su rapidez y seguridad en comparación con otros gestores. YARN utiliza un sistema de caché para optimizar las instalaciones y proporciona un archivo de bloqueo para garantizar la consistencia de las versiones de las dependencias en diferentes entornos de desarrollo....):
$ export PIG_CONF_DIR=/usr/lib/pig/conf
$ export PIG_CLASSPATH=/usr/lib/hbase/hbase-0.94.2-cdh4.2.1 -security.jar:/usr/lib/zookeeper/zookeeper-3.4.5-cdh4.2.1.jar
$ pig ... grunt>
Una vez que vea «gruñido>», puede comenzar a codificar en PIG.
Antecedentes del caso
Usted es el líder de análisis en una tienda minorista llamada XYZ. XYZ mantiene un registro de todos los clientes que compran en esta tienda. Su tarea para este ejercicio es crear una nueva columna llamada impuesto sobre la venta, que es el 5% de la venta. Luego, filtre las personas para quienes el monto del impuesto es menor a $ 35. Una vez realizada esta subconjunto, elija los 2 principales clientes con el menor número de clientes. A continuación se muestra una tabla de muestra para la tienda minorista que se guarda en forma de .csv.
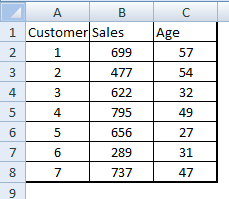
Escribir una consulta en PIG Latin
Construyamos esta consulta paso a paso. Los siguientes son los pasos que debe seguir:
Paso 1 : Cargue el conjunto de datos en el formato comprensible de PIG y almacenamiento temporal desde donde la consulta PIG puede hacer referencia directamente a la tabla
Sales = LOAD 'dataset.csv' USING PigStorage (',') AS (Customer,Sales);
Tenga en cuenta que el comando anterior no carga la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... edad. Mientras trabaja con Big Data, debe ser muy específico sobre las variables que necesita usar y, por lo tanto, asegúrese de elegir solo aquellas variables que son importantes para usted en el código.
Paso 2: crea una nueva tabla con valores de impuestos.
Tax = FOREACH Sales GENERATE Customer,Sales,Sales*0.05 as Tax : float;
El comando anterior genera una nueva tabla llamada impuestos que tiene las tres columnas. La tabla ahora tendrá un aspecto similar al siguiente:
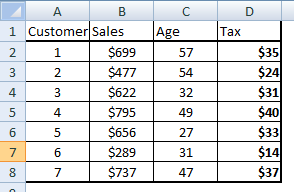 Paso 3: Subconjine toda la tabla en el cliente con un valor de impuestos por debajo de $ 35.
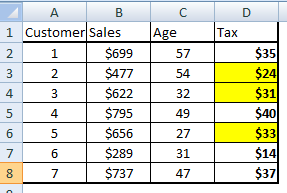
Paso 3: Subconjine toda la tabla en el cliente con un valor de impuestos por debajo de $ 35.
Lowtax = FILTER Tax BY Tax < $35;
El resultado de este comando se verá elija las celdas amarillas en la siguiente tabla:
 Paso 4: Ahora necesitamos ordenar la tabla de subconjuntos por Cliente (ID) y elegir los dos Clientes principales.
Paso 4: Ahora necesitamos ordenar la tabla de subconjuntos por Cliente (ID) y elegir los dos Clientes principales.
sortedcust = ORDER Lowtax BY Customer;
top_two = LIMIT sortedcust 2;
Paso 5: almacene el archivo temporal en un archivo csv permanente
STORE sortedcust INTO 'salesreport' USING PIGSTORAGE (',');
En este paso, nuestra tarea se completa y obtendrá los números de cliente requeridos con todos los detalles. A continuación, se muestra el código completo que se puede ejecutar de una vez:
Sales = LOAD 'dataset.csv' USING PigStorage (',') AS (Customer,Sales);
Tax = FOREACH Sales GENERATE Customer,Sales,Sales*0.05 as Tax : float;
Lowtax = FILTER Tax BY Tax < $35;
sortedcust = ORDER Lowtax BY Customer;
top_two = LIMIT sortedcust 2;
STORE sortedcust INTO 'salesreport' USING PIGSTORAGE (',');
Notas finales
En este artículo, aprendimos cómo escribir códigos básicos en PIG Latin. Sin embargo, hemos restringido este artículo a declaraciones simples de filtrado y ordenación, también hablaremos sobre fusiones más complejas y otras declaraciones en algunos de los próximos artículos.
¿Le resultó útil el artículo? Comparta con nosotros cualquier aplicación práctica de PIG que haya encontrado en su trabajo. Háganos saber su opinión sobre este artículo en el cuadro a continuación.





