
El desafío del desajuste y el sobreajuste en el aprendizaje automático
Inevitablemente, se enfrentará a esta pregunta en una entrevista con un científico de datos:
¿Puede explicar qué es el desajuste y el sobreajuste en el contexto del aprendizaje automático? Descríbalo de una manera que inclusive una persona sin conocimientos técnicos pueda comprender.
¡Su capacidad para explicar esto de una manera no técnica y fácil de comprender bien podría elegir su idoneidad para el rol de ciencia de datos!
Inclusive cuando estamos trabajando en un aprendizaje automático proyecto, a menudo nos enfrentamos a situaciones en las que nos encontramos con un rendimiento inesperado o diferencias en la tasa de error entre el conjunto de entrenamiento y el conjunto de prueba (como se muestra a continuación). ¿Cómo puede un modelo funcionar tan bien en el conjunto de entrenamiento y tan mal en el conjunto de prueba?

Esto sucede con mucha frecuencia siempre que trabajo con modelos predictivos basados en árboles. Debido a la forma en que funcionan los algoritmos, ¡puedes imaginar lo complicado que es evitar caer en la trampa del sobreajuste!
Al mismo tiempo, puede ser bastante abrumador cuando no podemos hallar el motivo subyacente por la que nuestro modelo predictivo muestra esta conducta anómalo.
Esta es mi experiencia personal: pregúntele a cualquier científico de datos experimentado sobre esto, por lo general comienzan hablando de una gama de términos elegantes como sobreajuste, desajuste, sesgo y variación. Pero poco se habla sobre la intuición detrás de estos conceptos de aprendizaje automático. Rectifiquemos eso, ¿de acuerdo?
Tomemos un ejemplo para comprender el ajuste insuficiente frente al sobreajuste
Quiero explicar estos conceptos usando un ejemplo del mundo real. Mucha gente habla sobre el ángulo teórico, pero creo que eso no es suficiente: necesitamos visualizar cómo funcionan verdaderamente el ajuste insuficiente y el ajuste excesivo.
Entonces, volvamos a nuestros días universitarios para esto.
Considere una clase de matemáticas que consta de 3 estudiantes y un profesor.
Ahora, en cualquier salón de clases, podemos dividir ampliamente a los estudiantes en 3 categorías. Hablaremos de ellos uno por uno.

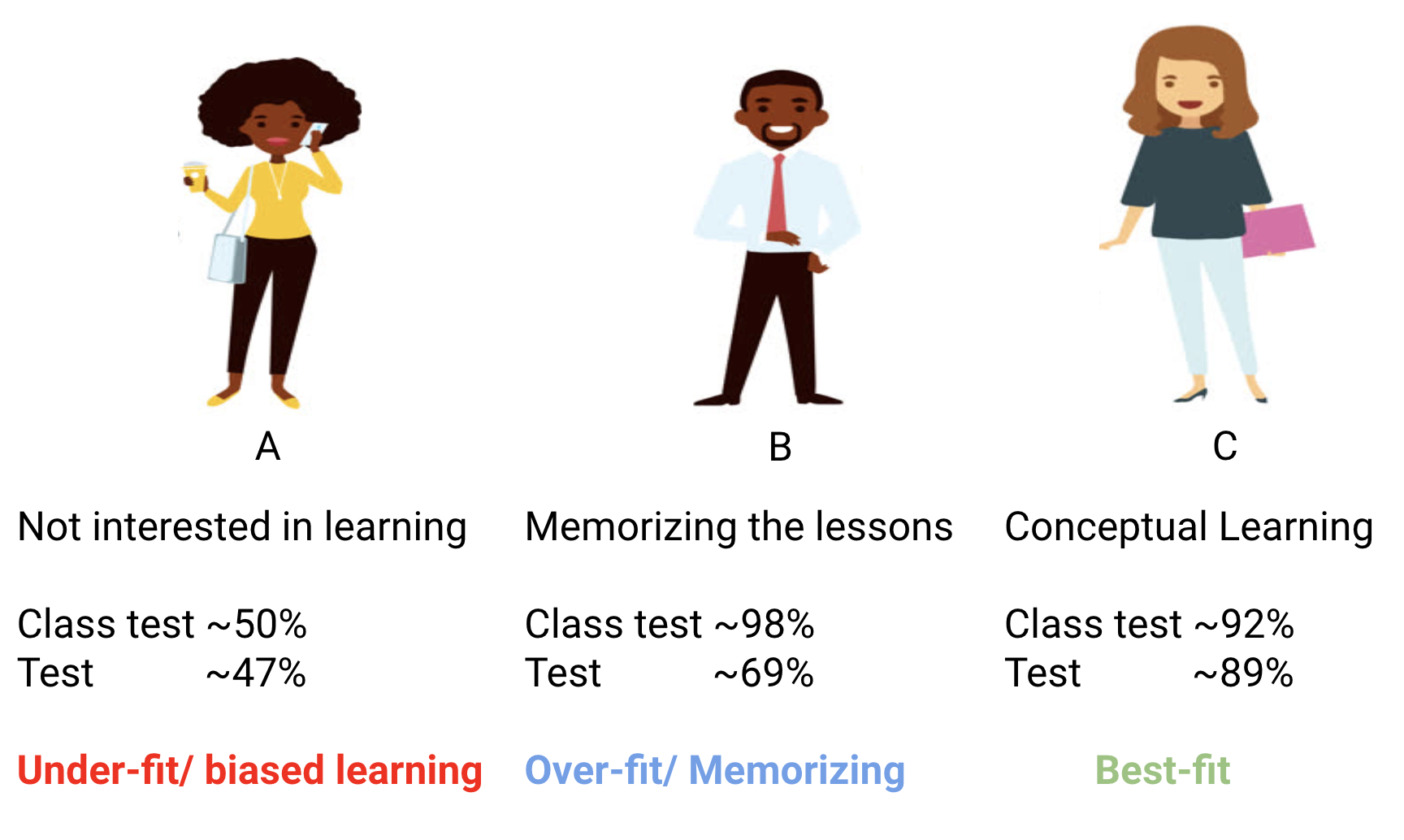
Digamos que el estudiante A se parece a un estudiante al que no le gustan las matemáticas. No le interesa lo que se enseña en la clase y es por ello que no presta mucha atención al profesor y al contenido que está enseñando.

Consideremos al estudiante B. Es el estudiante más competitivo que se centra en memorizar todas y cada una de las preguntas que se enseñan en clase en lugar de enfocarse en los conceptos clave. Simplemente, no le interesa aprender el enfoque de resolución de problemas.

En resumen, tenemos a la estudiante ideal C. Ella está puramente interesada en aprender los conceptos clave y el enfoque de resolución de problemas en la clase de matemáticas en lugar de simplemente memorizar las soluciones presentadas.

Todos sabemos por experiencia lo que sucede en un aula. El profesor primero da conferencias y enseña a los estudiantes sobre los problemas y cómo resolverlos. Al final del día, el profesor simplemente realiza una prueba basada en lo que enseñó en la clase.
El estorbo viene en las pruebas semester3 que la escuela establece. Aquí es donde surgen nuevas preguntas (datos invisibles). Los estudiantes no han visualizado estas preguntas antes y ciertamente no las han resuelto en el aula. ¿Suena familiar?
Entonces, analicemos lo que sucede cuando el maestro toma una prueba en el aula al final del día:

- El estudiante A, que estaba distraído en su propio mundo, simplemente adivinó las respuestas y obtuvo aproximadamente un 50% de calificaciones en la prueba.
- Por otra parte, el estudiante que memorizó todas y cada una de las preguntas enseñadas en el aula fue capaz de responder casi todas las preguntas de memoria y, por eso, obtuvo un 98% de calificaciones en la prueba de la clase.
- Para la alumna C, en realidad resolvió todas las preguntas usando el enfoque de resolución de problemas que aprendió en el aula y obtuvo una puntuación del 92%.
Podemos inferir claramente que el estudiante que simplemente memoriza todo está obteniendo mejores resultados sin mucha dificultad.
Ahora aquí está el giro. Veamos además lo que sucede durante la prueba mensual, cuando los alumnos disponen que enfrentarse a nuevas preguntas desconocidas que el profesor no enseña en clase.

- En el caso del estudiante A, las cosas no cambiaron mucho y aún responde preguntas correctamente al azar ~ 50% del tiempo.
- En el caso del Estudiante B, su puntuación se redujo significativamente. ¿Puedes adivinar por qué? Esto se debe a que siempre memorizó los problemas que se le enseñaron en la clase, pero esta prueba mensual contenía preguntas que nunca antes había visto. Por eso, su rendimiento bajó significativamente.
- En el caso del Estudiante C, la puntuación se mantuvo más o menos igual. Esto se debe a que se centró en aprender el enfoque de resolución de problemas y, por eso, pudo aplicar los conceptos que aprendió para solucionar las preguntas desconocidas.
¿Cómo se relaciona esto con el desajuste y el sobreajuste en el aprendizaje automático?
Tal vez se pregunte cómo se relaciona este ejemplo con el problema que encontramos a lo largo del entrenamiento y los puntajes de las pruebas del clasificador del árbol de decisión. ¡Buena pregunta!
Entonces, trabajemos en conectar este ejemplo con los resultados del clasificador del árbol de decisiones que les mostré previamente.

Primero, el trabajo en clase y la prueba de clase se asemejan a los datos de entrenamiento y el pronóstico sobre los datos de entrenamiento en sí, respectivamente. Por otra parte, la prueba semestral representa el conjunto de pruebas de nuestros datos que guardamos a un lado antes de entrenar nuestro modelo (o datos no vistos en un proyecto de aprendizaje automático del mundo real).
Ahora, recuerde nuestro clasificador de árbol de decisiones que mencioné previamente. Dio una puntuación perfecta en el conjunto de entrenamiento, pero tuvo problemas con el conjunto de prueba. Comparando eso con los ejemplos de estudiantes que acabamos de discutir, el clasificador establece una analogía con el estudiante B que trató de memorizar todas y cada una de las preguntas del conjunto de capacitación.
De manera semejante, nuestro clasificador de árbol de decisión intenta aprender todos y cada uno de los puntos de los datos de entrenamiento, pero sufre radicalmente cuando encuentra un nuevo punto de datos en el conjunto de prueba. No es capaz de generalizarlo bien.
Esta situación en la que un modelo dado tiene un rendimiento demasiado bueno en los datos de entrenamiento, pero el rendimiento cae significativamente sobre el conjunto de prueba se denomina modelo de sobreajuste.
A modo de ejemplo, modelos no paramétricos como árboles de decisión, KNN y otros algoritmos basados en árboles son muy propensos a sobreajustarse. Estos modelos pueden aprender relaciones muy complejas que pueden resultar en un sobreajuste. El siguiente gráfico resume este concepto:
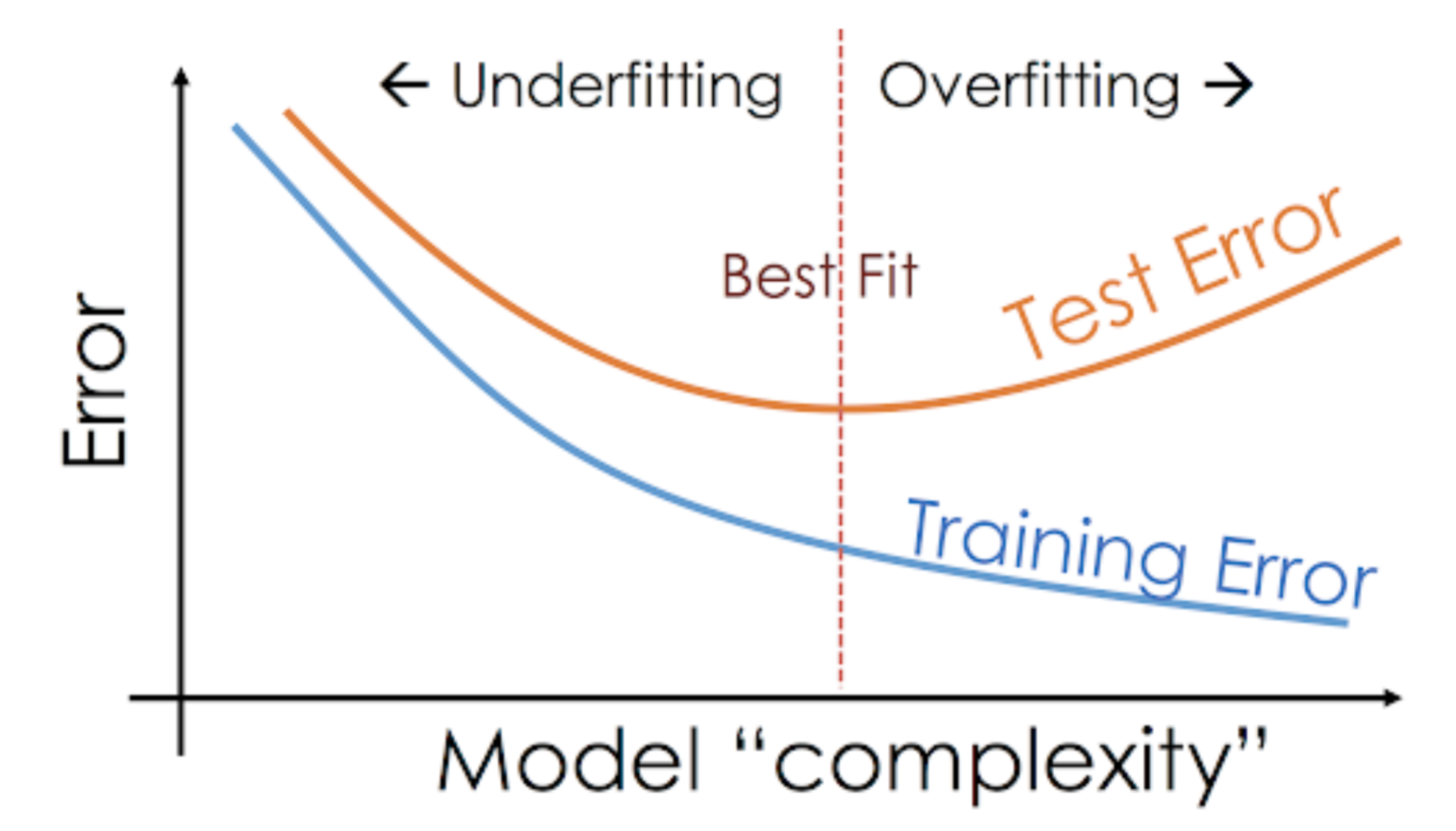
Por otra parte, si el modelo se está desempeñando mal durante la prueba y el tren, entonces lo llamamos un modelo que no se adapta bien. Un ejemplo de esta situación sería la construcción de un modelo de regresión lineal sobre datos no lineales.

Notas finales
Espero que esta breve intuición haya aclarado cualquier duda que pueda haber tenido sobre los modelos que no se ajustan, sobreajustan y mejor se ajustan y cómo funcionan o se comportan bajo el capó.
No dude en enviarme cualquier pregunta o comentario a continuación.





