Este artículo fue publicado como parte del Blogatón de ciencia de datos
En el mundo actual impulsado por la tecnología, cada segundo se genera una gran cantidad de datos. El monitoreo constante y el análisis correcto de dichos datos son necesarios para obtener información significativa y útil.
Tiempo real Los datos de sensores, dispositivos IoT, archivos de registro, redes sociales, etc. deben ser monitoreados de cerca y procesados de inmediato. Por lo tanto, para el análisis de datos en tiempo real, necesitamos un motor de transmisión de datos altamente escalable, confiable y tolerante a fallas.
Transmisión de datos
La transmisión de datos es una forma de recopilar datos de forma continua en tiempo real a partir de múltiples fuentes de datos en forma de flujos de datos. Se puede pensar en Datastream como una tabla que se agrega continuamente.
La transmisión de datos es esencial para manejar cantidades masivas de datos en vivo. Dichos datos pueden provenir de una variedad de fuentes como transacciones en línea, archivos de registro, sensores, actividades del jugador en el juego, etc.
Existen varias técnicas de transmisión de datos en tiempo real, como Apache KafkaApache Kafka es una plataforma de mensajería distribuida diseñada para manejar flujos de datos en tiempo real. Desarrollada originalmente por LinkedIn, ofrece alta disponibilidad y escalabilidad, lo que la convierte en una opción popular para aplicaciones que requieren procesamiento de grandes volúmenes de datos. Kafka permite a los desarrolladores publicar, suscribirse y almacenar registros de eventos, facilitando la integración de sistemas y la analítica en tiempo real...., Spark Streaming, Apache FlumeFlume es un software de código abierto diseñado para la recolección y transporte de datos. Utiliza un enfoque basado en flujos, lo que permite mover datos de diversas fuentes hacia sistemas de almacenamiento como Hadoop. Su arquitectura modular y escalable facilita la integración con múltiples orígenes de datos, lo que lo convierte en una herramienta valiosa para el procesamiento y análisis de grandes volúmenes de información en tiempo real.... etc. En esta publicación, discutiremos la transmisión de datos usando Spark Streaming.
Spark Streaming
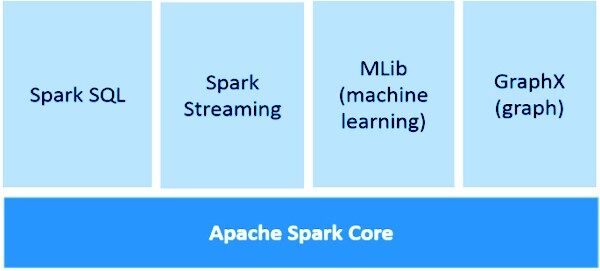
Spark Streaming es una parte integral de API central de Spark para realizar análisis de datos en tiempo real. Nos permite construir una aplicación de transmisión de flujos de datos en vivo escalable, de alto rendimiento y tolerante a fallas.
Spark Streaming admite el procesamiento de datos en tiempo real de varias fuentes de entrada y el almacenamiento de los datos procesados en varios receptores de salida.
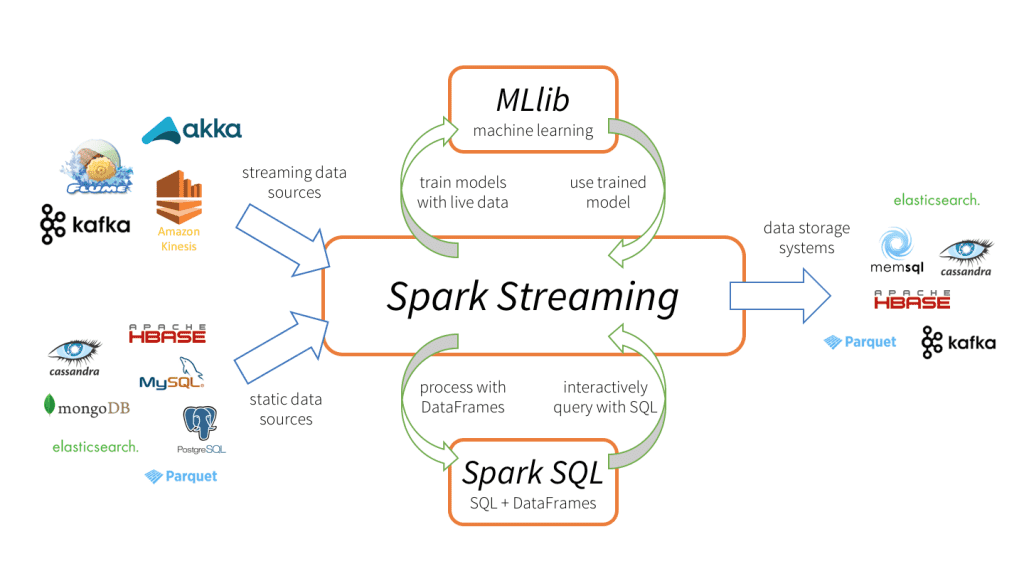
Spark Streaming tiene 3 componentes principales, como se muestra en la imagen de arriba.
-
Fuentes de datos de entrada: Fuentes de datos de transmisión (como Kafka, Flume, Kinesis, etc.), fuentes de datos estáticos (como MySQL, MongoDB, Cassandra, etc.), sockets TCP, Twitter, etc.
-
Motor Spark Streaming: Para procesar los datos entrantes utilizando varias funciones integradas, algoritmos complejos. Además, podemos consultar transmisiones en vivo, aplicar el aprendizaje automático usando Spark SQL y MLlib respectivamente.
-
Fregaderos de salida: Los datos procesados se pueden almacenar en sistemas de archivos, bases de datos (relacionales y NoSQL), paneles en vivo, etc.
Tales capacidades únicas de procesamiento de datos, formato de entrada y salida hacen Spark Streaming más atractivo, lo que conduce a una rápida adopción.
Ventajas de Spark Streaming
-
Marco de transmisión unificado para todas las tareas de procesamiento de datos (incluido el aprendizaje automático, procesamiento de gráficos, operaciones SQL) en flujos de datos en vivo.
-
Equilibrio de carga dinámico y mejor administración de recursos al equilibrar de manera eficiente la carga de trabajo entre los trabajadores y lanzar la tarea en paralelo.
-
Profundamente integrado con bibliotecas de procesamiento avanzadas como Spark SQL, MLlib, GraphX.
-
Recuperación más rápida de fallas al reiniciar las tareas fallidas en paralelo en otros nodos libres.
Conceptos básicos de Spark Streaming
Spark Streaming divide los flujos de datos de entrada en vivo en lotes que luego son procesados por Motor de chispa.

DStream (flujo discretizado)
DStream es una abstracción de alto nivel proporcionada por Spark Streaming, básicamente, significa el flujo continuo de datos. Se pueden crear a partir de fuentes de datos de transmisión (como Kafka, Flume, Kinesis, etc.) o realizando operaciones de alto nivel en otros DStreams.
Internamente, DStream es una secuencia de RDD y este fenómeno permite que Spark Streaming se integre con otros componentes de Spark como MLlib, GraphX, etc.

Al crear una aplicación de transmisión, también debemos especificar la duración del lote para crear nuevos lotes a intervalos de tiempo regulares. Normalmente, la duración del lote varía de 500 ms a varios segundos. Por ejemplo, son 3 segundos, luego los datos de entrada se recopilan cada 3 segundos.
Spark Streaming le permite escribir código en lenguajes de programación populares como Python, Scala y Java. Analicemos una aplicación de transmisión de muestra que usa PySpark.
Aplicación de muestra
Como comentamos anteriormente, Spark Streaming también permite recibir flujos de datos mediante sockets TCP. Así que vamos a escribir un programa de transmisión simple para recibir flujos de datos de texto en un puerto en particular, realizar una limpieza de texto básica (como eliminación de espacios en blanco, eliminación de palabras vacías, lematización, etc.) e imprimir el texto limpio en la pantalla.
Ahora comencemos a implementar esto siguiendo los pasos a continuación.
1. Creación de un contexto de transmisión y recepción de flujos de datos
StreamingContext es el principal punto de entrada para cualquier aplicación de transmisión. Se puede crear instanciando StreamingContext clase de pyspark.streaming módulo.
from pyspark import SparkContext from pyspark.streaming import StreamingContext
Mientras creaba StreamingContext podemos especificar la duración del lote, por ejemplo, aquí la duración del lote es de 3 segundos.
sc = SparkContext(appName = "Text Cleaning") strc = StreamingContext(sc, 3)
Una vez el StreamingContext se crea, podemos comenzar a recibir datos en forma de DStream a través del protocolo TCP en un puerto específico. Por ejemplo, aquí el nombre de host se especifica como «localhost» y el puerto utilizado es 8084.
text_data = strc.socketTextStream("localhost", 8084)
2. Realización de operaciones en flujos de datos
Después de crear un DStream objeto, podemos realizar operaciones en él según el requisito. Aquí, escribimos una función de limpieza de texto personalizada.
Esta función primero convierte el texto de entrada en minúsculas, luego elimina espacios adicionales, caracteres no alfanuméricos, enlaces / URL, palabras vacías y luego lematiza aún más el texto utilizando la biblioteca NLTK.
import re
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
def clean_text(sentence):
sentence = sentence.lower()
sentence = re.sub("s+"," ", sentence)
sentence = re.sub("W"," ", sentence)
sentence = re.sub(r"httpS+", "", sentence)
sentence=" ".join(word for word in sentence.split() if word not in stop_words)
sentence = [lemmatizer.lemmatize(token, "v") for token in sentence.split()]
sentence = " ".join(sentence)
return sentence.strip()
3. Iniciar el servicio de transmisión
El servicio de transmisión aún no ha comenzado. Utilizar el comienzo() función en la parte superior de la StreamingContext objeto para iniciarlo y seguir recibiendo datos de transmisión hasta que el comando de terminación (Ctrl + C o Ctrl + Z) no sea recibido por awaitTermination () función.
strc.start() strc.awaitTermination()
NOTA – El código completo se puede descargar desde aquí.
Ahora primero tenemos que ejecutar el ‘Carolina del Norte‘comando (Netcat Utility) para enviar los datos de texto desde el servidor de datos al servidor de transmisión Spark. Netcat es una pequeña utilidad disponible en sistemas similares a Unix para leer y escribir en conexiones de red mediante puertos TCP o UDP. Sus dos opciones principales son:
-
-l: Permitir Carolina del Norte para escuchar una conexión entrante en lugar de iniciar una conexión a un host remoto.
-
-k: Efectivo Carolina del Norte para permanecer atento a otra conexión después de que se complete la conexión actual.
Así que ejecuta lo siguiente Carolina del Norte comando en la terminal.
nc -lk 8083
De manera similar, ejecute el script pyspark en una terminal diferente usando el siguiente comando para realizar la limpieza de texto en los datos recibidos.
spark-submit streaming.py localhost 8083
Según esta demostración, cualquier texto escrito en la terminal (ejecutando netcat servidor) se limpiarán y el texto limpiado se imprimirá en otro terminal cada 3 segundos (duración del lote).


Notas finales
En este artículo, discutimos Spark Streaming, sus beneficios en la transmisión de datos en tiempo real y una aplicación de muestra (utilizando sockets TCP) para recibir las transmisiones de datos en vivo y procesarlas según el requisito.
Los medios que se muestran en este artículo sobre la implementación de modelos de aprendizaje automático que aprovechan CherryPy y Docker no son propiedad de DataPeaker y se utilizan a discreción del autor.





