Eine einfache Analogie zur Erklärung des Entscheidungsbaums gegenüber dem Random Forest
Beginnen wir mit einem Gedankenexperiment, das den Unterschied zwischen einem Entscheidungsbaum und einem Random-Forest-Modell veranschaulicht..
Angenommen, eine Bank muss einem Kunden einen kleinen Kreditbetrag genehmigen und die Bank muss schnell eine Entscheidung treffen. Die Bank prüft die Bonität und finanzielle Situation der Person und stellt fest, dass der vorherige Kredit noch nicht zurückgezahlt wurde. Deswegen, die Bank lehnt die Anfrage ab.
Aber hier ist das Problem: der Kreditbetrag war für die riesige Kasse der Bank zu gering und sie hätte ihn mit sehr geringem Risiko leicht bewilligen können. Deswegen, die Bank hat die Möglichkeit verloren, etwas Geld zu verdienen.
Jetzt, ein weiterer Kreditantrag wird in ein paar Tagen eintreffen, aber diesmal präsentiert die Bank eine andere Strategie: mehrere Entscheidungsprozesse. Manchmal, Überprüfen Sie zuerst die Kredithistorie und, manchmal, Überprüfen Sie zunächst die finanzielle Situation des Kunden und die Kreditsumme. Später, die Bank fasst die Ergebnisse dieser multiplen Entscheidungsprozesse zusammen und beschließt, dem Kunden den Kredit zu gewähren.
Auch wenn dieser Vorgang länger gedauert hat als der vorherige, die Bank hat von dieser Methode profitiert. Dies ist ein klassisches Beispiel, bei dem die kollektive Entscheidungsfindung einen einzelnen Entscheidungsprozess übertraf. Jetzt, hier ist meine frage an dich: Wissen Sie, was diese beiden Prozesse darstellen??

Das sind Entscheidungsbäume und ein Random Forest!! Wir werden diese Idee hier im Detail untersuchen, Wir werden uns mit den Hauptunterschieden zwischen diesen beiden Methoden befassen und die Schlüsselfrage beantworten: Welchen maschinellen Lernalgorithmus soll ich verwenden?
Inhaltsverzeichnis
- Kurze Einführung in Entscheidungsbäume
- Ein Überblick über Random Forests
- Random Forest Clash und Entscheidungsbaum (In Code!)
- Warum hat Random Forest einen Entscheidungsbaum übertroffen??
- Entscheidungsbaum versus Random Forest: Wann sollten Sie welchen Algorithmus wählen?
Kurze Einführung in Entscheidungsbäume
Ein Entscheidungsbaum ist ein überwachter maschineller Lernalgorithmus, der für Klassifikations- und Regressionsprobleme verwendet werden kann. Ein Entscheidungsbaum ist einfach eine Reihe von sequentiellen Entscheidungen, die getroffen werden, um ein bestimmtes Ergebnis zu erzielen.. Hier ist eine Illustration eines Entscheidungsbaums in Aktion (mit unserem Beispiel oben):
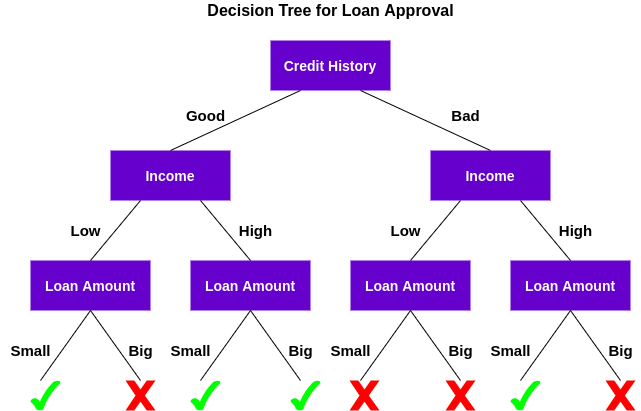
Lassen Sie uns verstehen, wie dieser Baum funktioniert.
Zuerst, Prüfen Sie, ob der Kunde eine gute Bonität hat. Darauf bezogen, teilt den Kunden in zwei Gruppen ein, nämlich, Kunden mit guter Bonität und Kunden mit schlechter Bonität. Später, prüft das Einkommen des Kunden und teilt es erneut in zwei Gruppen ein. Schließlich, überprüft den vom Kunden gewünschten Kreditbetrag. Nach den Ergebnissen der Überprüfung dieser drei Merkmale, der Entscheidungsbaum entscheidet, ob der Kredit des Kunden genehmigt werden soll oder nicht.
Die Eigenschaften / Attribute und Bedingungen können sich abhängig von den Daten und der Komplexität des Problems ändern, aber die Grundidee bleibt die gleiche. Dann, Ein Entscheidungsbaum trifft eine Reihe von Entscheidungen basierend auf einer Reihe von Merkmalen / in den Daten vorhandene Attribute, das war in diesem Fall die Kredithistorie, Einkommen und Kreditsumme.
Jetzt, fragst du dich vielleicht:
Warum hat der Entscheidungsbaum zuerst die Kreditwürdigkeit und nicht das Einkommen überprüft??
Dabei wird die Bedeutung des Merkmals bezeichnet und die Reihenfolge der zu prüfenden Merkmale anhand von Kriterien wie Gini-Verunreinigungsindex Ö Informationsgewinn. Eine Erläuterung dieser Konzepte würde den Rahmen unseres Artikels hier sprengen., Sie können sich jedoch eine der folgenden Ressourcen ansehen, um alles über Entscheidungsbäume zu erfahren:
Notiz: Die Idee hinter diesem Artikel ist der Vergleich von Entscheidungsbäumen und Random Forests. Deswegen, Ich werde nicht auf die Details der Grundlagen eingehen, aber ich werde die relevanten Links bereitstellen, falls Sie weiter nachforschen möchten.
Ein Überblick über Random Forest
Der Entscheidungsbaum-Algorithmus ist recht einfach zu verstehen und zu interpretieren. Aber oft, ein einzelner Baum reicht nicht aus, um effektive Ergebnisse zu erzielen. Hier kommt der Random Forest-Algorithmus ins Spiel..

Random Forest ist ein baumbasierter maschineller Lernalgorithmus, der die Leistungsfähigkeit mehrerer Entscheidungsbäume nutzt, um Entscheidungen zu treffen. Wie der Name schon sagt, es ist ein “Wald” von Bäumen!
Aber, Warum nennen wir es Wald “zufällig”? Das liegt daran, dass es ein Wald von . ist zufällig erstellte Entscheidungsbäume. Jeder Knoten im Entscheidungsbaum arbeitet an einer zufälligen Teilmenge von Merkmalen, um die Ausgabe zu berechnen. Der Random Forest kombiniert dann die Ausgabe einzelner Entscheidungsbäume, um die endgültige Ausgabe zu generieren.
In einfachen Worten:
Der Random-Forest-Algorithmus kombiniert die Ausgabe mehrerer Entscheidungsbäume (zufällig erstellt) um die endgültige Ausgabe zu generieren.
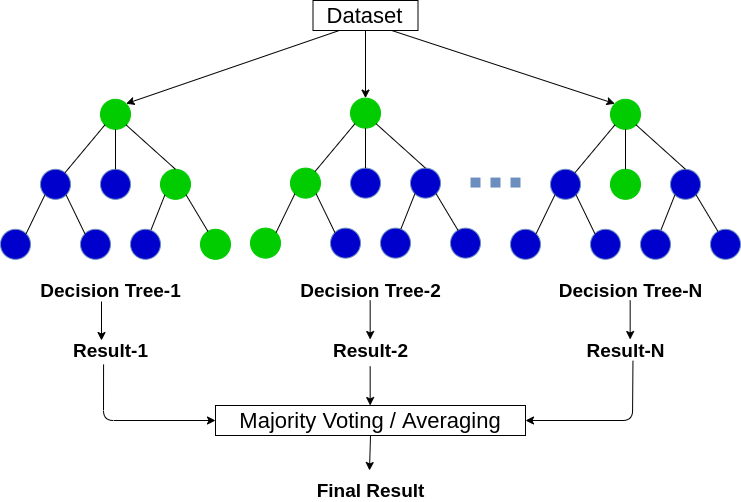
Dieser Prozess des Kombinierens der Ausgabe mehrerer einzelner Modelle (auch als schwache Schüler bekannt) benannt Gemeinsames Lernen. Wenn Sie mehr darüber erfahren möchten, wie der Random Forest und andere Ensemble-Lernalgorithmen funktionieren, siehe die folgenden Artikel:
Jetzt ist die Frage, Wie können wir entscheiden, welchen Algorithmus wir zwischen einem Entscheidungsbaum und einem Random Forest wählen?? Lassen Sie uns beide in Aktion sehen, bevor wir voreilige Schlüsse ziehen!!
Random Forest Clash und Entscheidungsbaum (In Code!)
In diesem Abschnitt, Wir werden Python verwenden, um ein binäres Klassifizierungsproblem zu lösen, indem wir sowohl einen Entscheidungsbaum als auch einen Random Forest verwenden. Wir vergleichen dann Ihre Ergebnisse und sehen, welches für unser Problem am besten geeignet ist..
Wir arbeiten an der Datensatz zur Kreditvorhersage de DataPeakers Plataforma DataHack. Dies ist ein binäres Klassifikationsproblem, bei dem wir anhand bestimmter Merkmale feststellen müssen, ob eine Person einen Kredit erhalten soll oder nicht.
Notiz: kann gehen DataHack Plattform und treten Sie in verschiedenen Online-Machine-Learning-Wettbewerben gegen andere an und gewinnen Sie spannende Preise.
Bereit zum Codieren?
Paso 1: Bibliotheken und Datensatz laden
Beginnen wir mit dem Importieren der erforderlichen Python-Bibliotheken und unseres Datensatzes:

Der Datensatz besteht aus 614 Reihen und 13 Merkmale, inklusive Kredithistorie, der bürgerliche staat, die Kreditsumme und das Geschlecht. Hier, die Zielvariable ist Darlehensstatus, die angibt, ob eine Person einen Kredit erhalten soll oder nicht.
Paso 2: Datenvorverarbeitung
Jetzt kommt der wichtigste Teil eines jeden Data-Science-Projekts: Data-Vorverarbeitung Ja feNaturtechnik. In diesem Abschnitt, Ich werde mich mit den kategorialen Variablen in den Daten befassen und auch die fehlenden Werte imputieren.
Die fehlenden Werte in den kategorialen Variablen werde ich mit dem Modus imputieren, und für stetige Variablen, mit dem Durchschnitt (für die jeweiligen Spalten). Was ist mehr, Wir werden die kategorialen Werte in den Daten mit einem Label versehen. Sie können diesen Artikel lesen, um mehr darüber zu erfahren Label-Codierung.

Paso 3: Erstellung von Testsets und Zügen
Jetzt, teilen wir den Datensatz in a 80:20 Beziehung für Training und Prüfung, beziehungsweise:
Werfen wir einen Blick auf die erstellten Zugformen und Testsätze:

Exzellent! Jetzt sind wir bereit für die nächste Phase, in der wir den Entscheidungsbaum und die Random-Forest-Modelle erstellen!!
Paso 4: Konstruktion und Bewertung des Modells
Da haben wir die Trainings- und Testsets, es ist Zeit, unsere Modelle zu trainieren und Kreditanträge zu klassifizieren. Zuerst, Wir werden einen Entscheidungsbaum auf diesem Datensatz trainieren:
Dann, Wir werden dieses Modell mit F1-Score bewerten. F1-Score ist das harmonische Mittel aus Präzision und Wiederfindung, das durch die Formel angegeben wird:
![]()
Mehr über diese und andere Bewertungskennzahlen erfahren Sie hier:
Lassen Sie uns die Leistung unseres Modells anhand des F1-Scores bewerten:
![]()
![]()
Hier, Sie können sehen, dass der Entscheidungsbaum in der Auswertung in der Stichprobe gut funktioniert, aber seine Leistung sinkt dramatisch in der Out-of-Sample-Auswertung. Warum denkst du ist das so? Leider, unser Entscheidungsbaummodell ist an die Trainingsdaten überangepasst. Wird der Random Forest dieses Problem lösen??
Erstellen eines zufälligen Waldmodells
Sehen wir uns ein zufälliges Waldmodell in Aktion an:
![]()
![]()
Hier, Wir können deutlich sehen, dass das Random-Forest-Modell in der Out-of-Sample-Auswertung viel besser abschneidet als der Entscheidungsbaum. Lassen Sie uns die Gründe dafür im nächsten Abschnitt diskutieren..
Warum hat unser Random-Forest-Modell den Entscheidungsbaum übertroffen??
Random Forest nutzt die Kraft mehrerer Entscheidungsbäume. Es tut Nein hängen von der Bedeutung des Merkmals ab, das durch einen einzelnen Entscheidungsbaum gegeben ist. Werfen wir einen Blick auf die Bedeutung der Funktion, die von verschiedenen Algorithmen verschiedenen Funktionen gegeben wird:
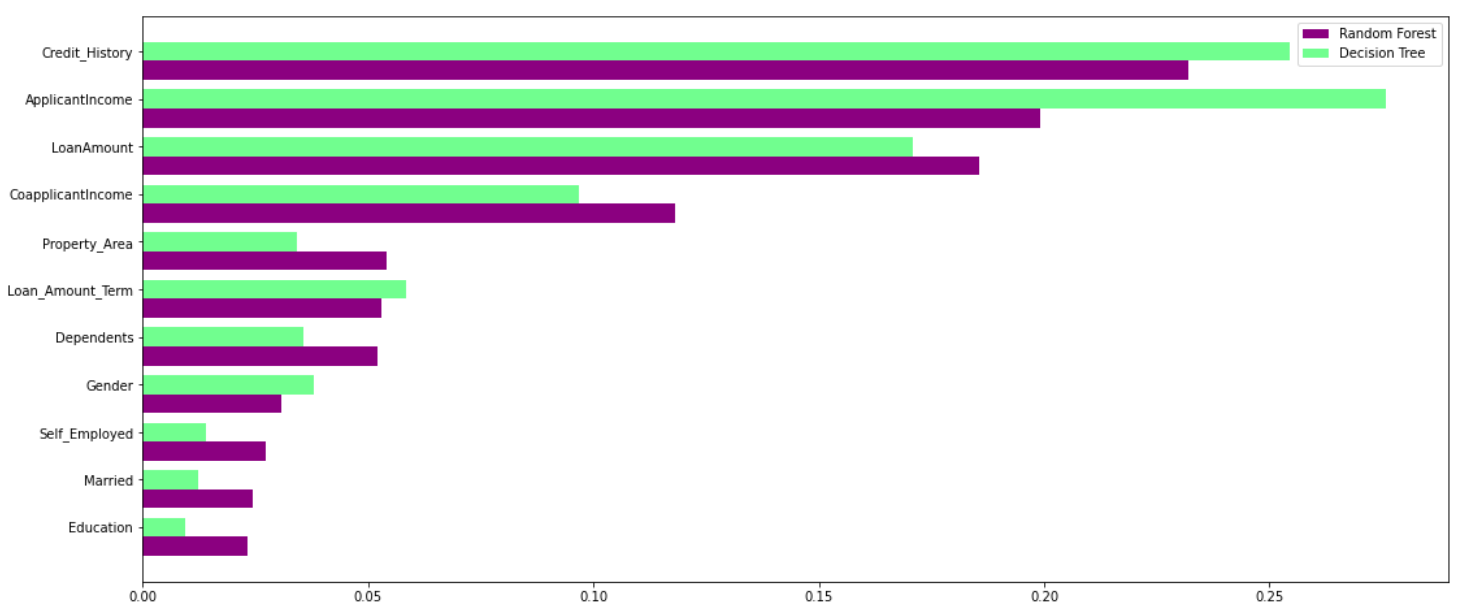
Wie Sie in der obigen Grafik deutlich sehen können, das Entscheidungsbaummodell legt großen Wert auf eine bestimmte Menge von Merkmalen. Aber der Random Forest wählt die Features während des Trainingsprozesses nach dem Zufallsprinzip aus. Deswegen, verlässt sich nicht stark auf bestimmte Funktionen. Dies ist eine Besonderheit des Zufallswaldes auf eingesackten Bäumen. Sie können mehr über die Tasche lesen.ing-Baum-Klassifikator hier.
Deswegen, Random Forest kann Daten besser verallgemeinern. Diese zufällige Auswahl von Merkmalen macht den Random Forest viel genauer als einen Entscheidungsbaum..
Dann, Welches sollte ich wählen: Entscheidungsbaum oder Random Forest?
Random Forest eignet sich für Situationen, in denen wir über einen großen Datensatz verfügen und die Interpretierbarkeit kein großes Problem darstellt.
Entscheidungsbäume sind viel einfacher zu interpretieren und zu verstehen. Da ein Random Forest mehrere Entscheidungsbäume kombiniert, wird schwieriger zu interpretieren. Hier ist die gute Nachricht: Es ist nicht unmöglich, einen Random Forest zu interpretieren. Hier ist ein Artikel, der über spricht interpretieren Sie die Ergebnisse eines Random-Forest-Modells:
Was ist mehr, Random Forest hat eine höhere Trainingszeit als ein einzelner Entscheidungsbaum. Sie müssen dies berücksichtigen, da wir die Anzahl der Bäume in einem zufälligen Wald erhöhen, die Zeit, die es braucht, um jeden von ihnen zu trainieren, erhöht sich auch. Dies kann oft entscheidend sein, wenn Sie mit einem engen Zeitplan an einem Machine-Learning-Projekt arbeiten..
Aber ich werde das sagen: trotz Instabilität und Abhängigkeit von einem bestimmten Merkmalssatz, Entscheidungsbäume sind wirklich nützlich, weil sie einfacher zu interpretieren und schneller zu trainieren sind. Jeder mit sehr geringen Kenntnissen in Data Science kann auch Entscheidungsbäume verwenden, um schnelle datengesteuerte Entscheidungen zu treffen..
Abschließende Anmerkungen
Das ist im Wesentlichen das, was Sie im Entscheidungsbaum angesichts der Random-Forstwirtschaft-Debatte wissen müssen.. Es kann schwierig werden, wenn Sie neu im maschinellen Lernen sind, aber dieser Artikel hätte die Unterschiede und Gemeinsamkeiten für dich verdeutlichen sollen.
Sie können mich mit Ihren Fragen und Gedanken im Kommentarbereich unten erreichen.





