Dieser Artikel wurde im Rahmen der Data Science Blogathon.
“Um auf dem Markt zu gewinnen, Du musst am Arbeitsplatz gewinnen” –Steve Jobs, Gründer von Apple Inc..
Einführung
Warum verwenden wir logistische Regression, um die Fluktuation von Mitarbeitern zu analysieren??
Wenn ein Mitarbeiter ein Unternehmen bleibt oder verlässt, deine antwort ist einfach binomial, nämlich, könnte sein “JAWOHL” Ö “NEIN”. Dann, Wir können sehen, dass unsere abhängige Variable Mitarbeiterabwanderung nur eine kategoriale Variable ist. Im Fall einer kategorialen abhängigen Variablen, Wir können keine lineare Regression verwenden, dann, Wir müssen "LOGISTISCHE REGRESSION“.
Methodik
Hier, ich werde tragen 5 Einfache Schritte zur Analyse der Mitarbeiterabwanderung mit R-Software
- DATENSAMMLUNG
- DATENVORBEARBEITUNG
- AUFTEILEN DER DATEN IN ZWEI TEILE “AUSBILDUNG” Ja “TESTS”
- BAUEN SIE DAS MODELL MIT “TRAININGSDATENSATZ”
- MACHEN SIE DEN PRÄZISIONSTEST MIT DEM “TESTDATENSATZ”
Datenexploration
Dieser Datensatz wird von der IBM Personalabteilung gesammelt. Der Datensatz enthält 1470 Beobachtungen und 35 Variablen. Innerhalb 35 Variablen, "Verschleiß" ist die abhängige Variable.
Ein kurzer Blick auf den Datensatz:
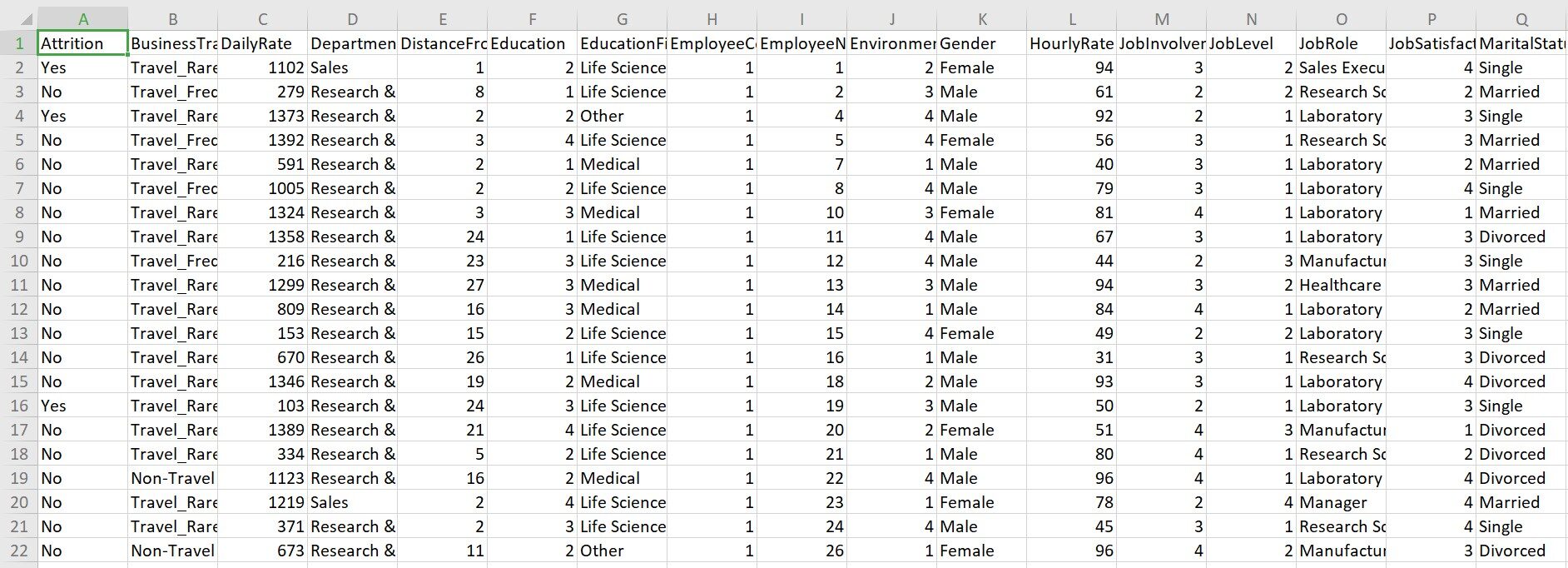
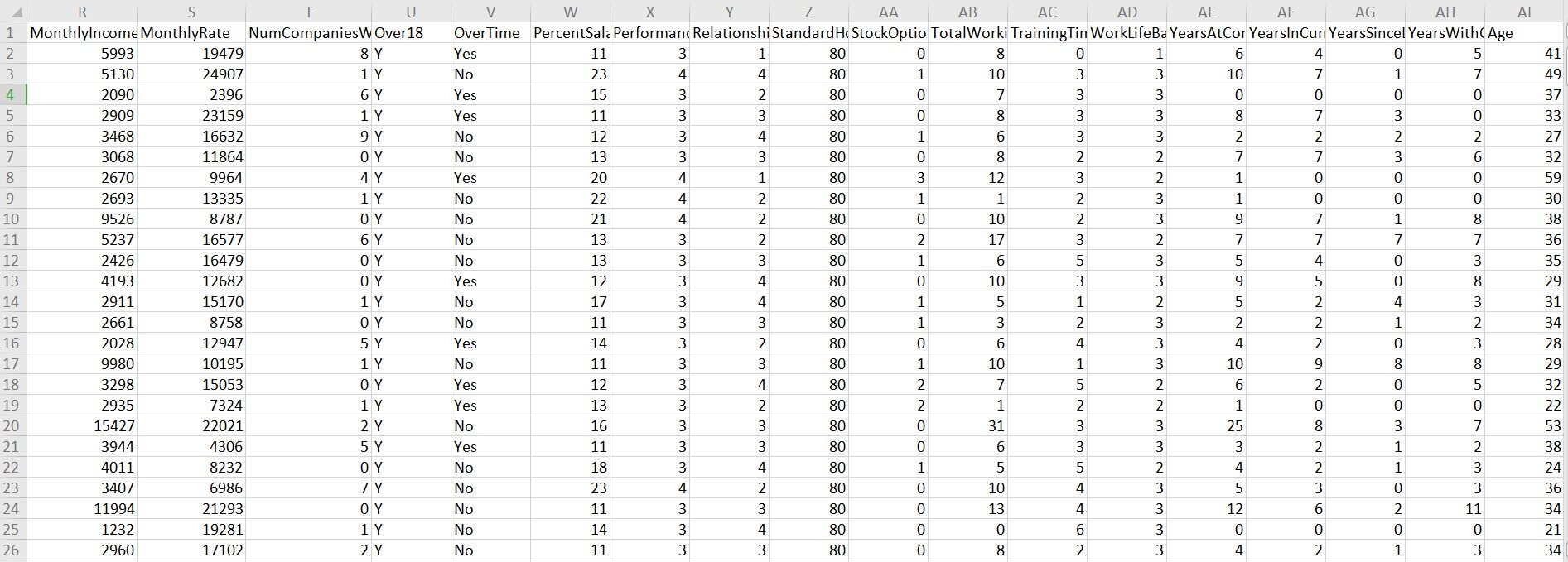
Guck mal:
Datenaufbereitung
-
Datentypen ändern:
Zuerst, wir müssen den Datentyp der abhängigen Variablen ändern “Tragen”. Es wird in Form von "Ja" und "Nein" angegeben., nämlich, ist eine kategoriale Variable. Um ein geeignetes Modell zu erstellen, müssen wir es in numerische Form umwandeln. Dafür, Wir weisen den Wert zu 1 auf "Ja" und den Wert 0 auf "Nein" und wir werden es in numerisch umwandeln.
JOB_Atrition$Atrition[JOB_Attrition$Attrition=="Jawohl"]=1 JOB_Atrition$Atrition[JOB_Attrition$Attrition=="Nein"]=0 JOB_Attrition$Attrition=as.numeric(JOB_Atrition$Atrition)
nächste, Wir ändern alle Variablen von “Charakter” ein “Faktor”
Es gibt 8 Zeichenvariablen: Geschäftsreise, Abteilung, Ausbildung, Bildungsbereich, Geschlecht, Tätigkeitsbereich, Familienstand, im Laufe der Zeit. Die Spaltennummern sind 2, 4, 6, 7, 11, 15, 17, 22 beziehungsweise.
JOB_Atrition[,C(2,4,6,7,11,15,17,22)]=lappig(JOB_Atrition[,C(2,4,6,7,11,15,17,22)],as.faktor)
Schließlich, es gibt noch eine andere Variable “Über 18” die alle Eingänge hat wie “Ja”. Es ist auch eine Zeichenvariable. Wir werden in numerisch umwandeln, da es nur eine Ebene hat, so dass die Umwandlung in einen Faktor kein gutes Ergebnis liefert. Dafür, Wir weisen den Wert zu 1 zu "Y" und wir werden es in numerisch umwandeln.
JOB_Attrition$Over18[JOB_Attrition$Over18=="Ja"]=1 JOB_Attrition$Over18=as.numeric(JOB_Attrition$Over18)
Teilen Sie den Datensatz in “Ausbildung” Ja “nachweisen”
In jeder Regressionsanalyse, wir müssen den Datensatz aufteilen in 2 Teile:
- TRAININGSDATENSATZ
- TESTDATENSATZ
Mit Hilfe des Trainingsdatensatzes, Wir erstellen unser Modell und testen seine Genauigkeit anhand des Testdatensatzes.
set.seed(1000)
ranuni=Probe(x=c("Ausbildung","Testen"),Größe=neu(JOB_Atrition),ersetzen=T,prob=c(0.7,0.3))
TrainingData=JOB_Atrition[ranuni =="Ausbildung",]
TestingData=JOB_Attrition[ranuni =="Testen",]
jetzt(Trainingsdaten)
jetzt(Testdaten)
Wir haben den gesamten Datensatz erfolgreich in zwei Teile geteilt. Jetzt haben wir 1025 Trainingsdaten und 445 Testdaten.
Modell bauen
Jetzt bauen wir das Modell mit ein paar einfachen Schritten wie folgt auf:
- Identifizieren Sie die unabhängigen Variablen
- Integrieren Sie die abhängige Variable “Tragen” im Modell.
- Transformieren Sie den Datentyp des Modells “Charakter” ein “Formel”
- Integrieren Sie TRAINING-Daten in die Formel und erstellen Sie das Modell
unabhängige Variablen = Spaltennamen(JOB_Atrition[,2:35])
unabhängige Variablen
Modell=einfügen(unabhängige Variablen,zusammenbrechen="+")
Modell
Modell_1=einfügen("Abrieb~",Modell)
Modell_1
Klasse(Modell_1)
Formel=als.Formel(Modell_1)
Formel
Produktion:

Nächste, Wir werden "Trainingsdaten" mit der Funktion "glm" in die Formel einbeziehen und ein logistisches Regressionsmodell erstellen..
Trainingsmodell1=glm(Formel = Formel,data=Trainingsdaten,Familie="Binomial-")
Jetzt, wir werden das modell von der “Schritt-für-Schritt-Auswahl”Methode, um signifikante Variablen aus dem Modell zu erhalten. Durch Ausführen des Codes erhalten wir eine Ausgabeliste, in der Variablen basierend auf unserer Bedeutung des Modells hinzugefügt und entfernt werden. Der Wert von AIC auf jeder Ebene spiegelt die Güte des jeweiligen Modells wider. Da der Wert weiter sinkt, man erhält ein besser passendes logistisches Regressionsmodell.
Die Anwendung der Zusammenfassung auf das endgültige Modell liefert uns die Liste der endgültigen signifikanten Variablen und ihrer jeweiligen wichtigen Informationen..
Trainingsmodell1=Schritt(Objekt = Trainingsmodell1,Richtung = "beide") Zusammenfassung(Trainingsmodell1)
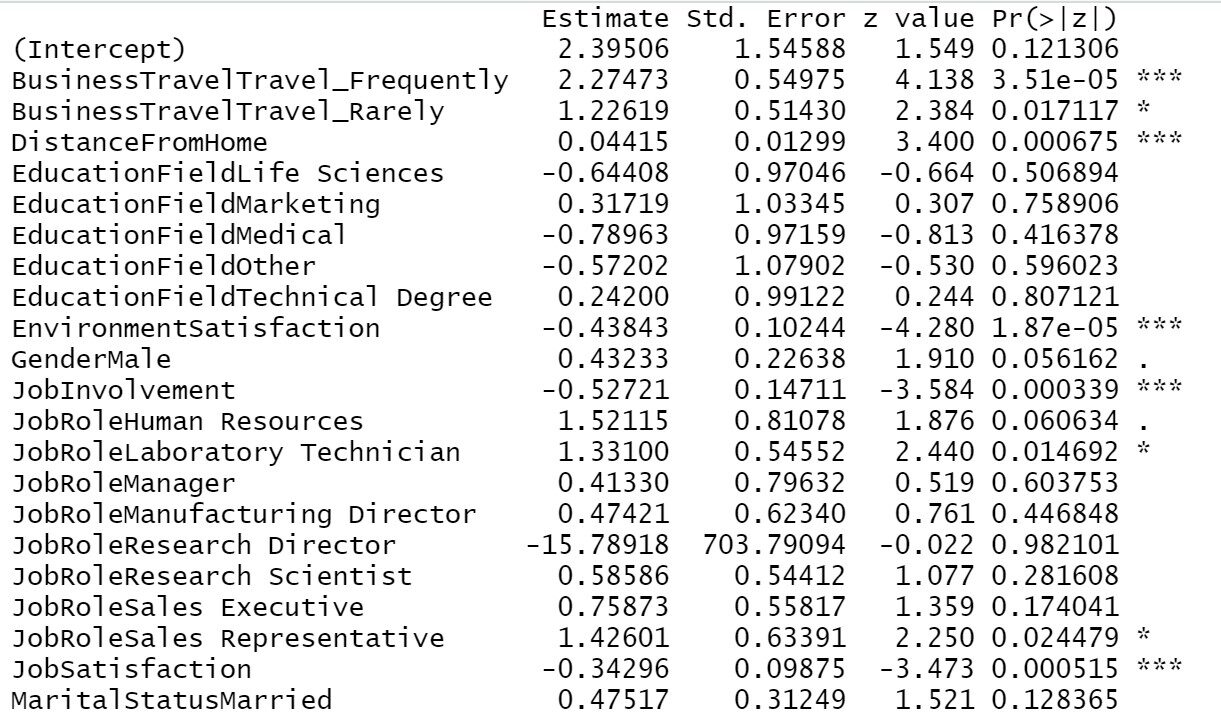
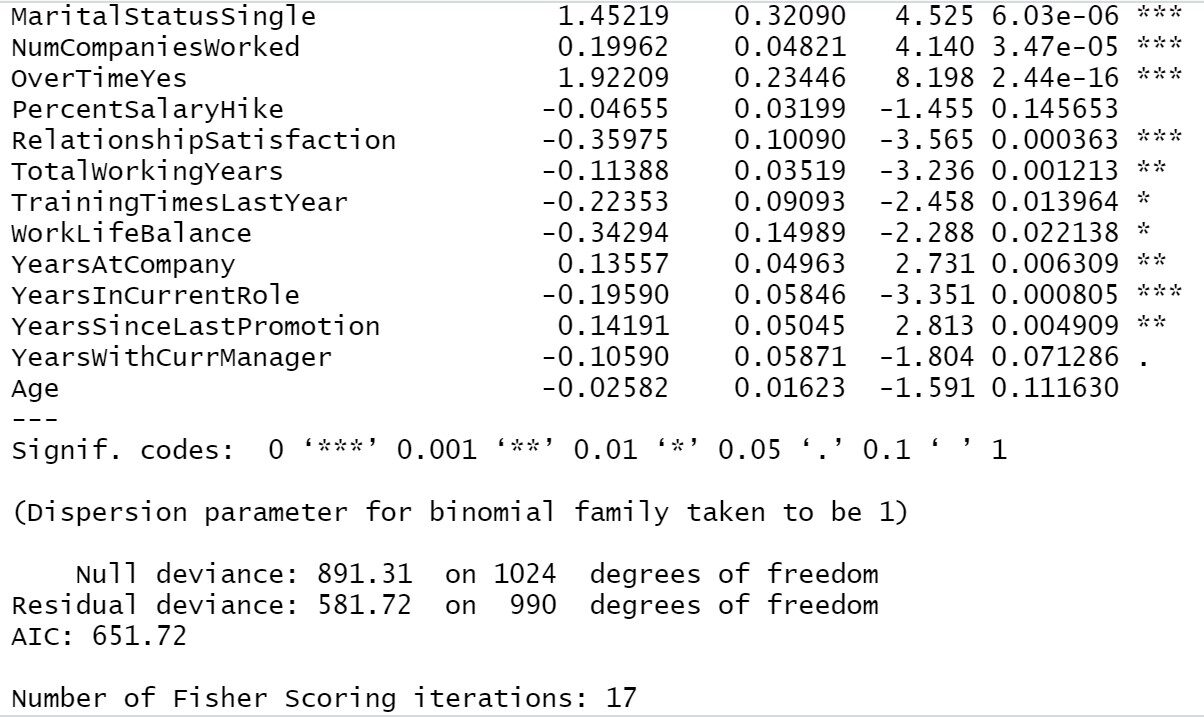
Aus unserem vorherigen Ergebnis können wir sehen, Geschäftsreise, Entfernung von zu Hause, Zufriedenheit mit der Umwelt, Arbeitnehmerbeteiligung, Arbeitszufriedenheit, Familienstand, Anzahl der Firmen gearbeitet, Im Laufe der Zeit, Zufriedenheit in Beziehungen, Gesamtarbeitsjahre, Jahre im Unternehmen, Jahre seit der letzten Aktion, Jahre in der jetzigen Position All dies sind die wichtigsten Variablen bei der Bestimmung der Mitarbeiterfluktuation. Beschäftigt sich das Unternehmen hauptsächlich mit diesen Bereichen, die Wahrscheinlichkeit, einen Mitarbeiter zu verlieren, ist geringer.
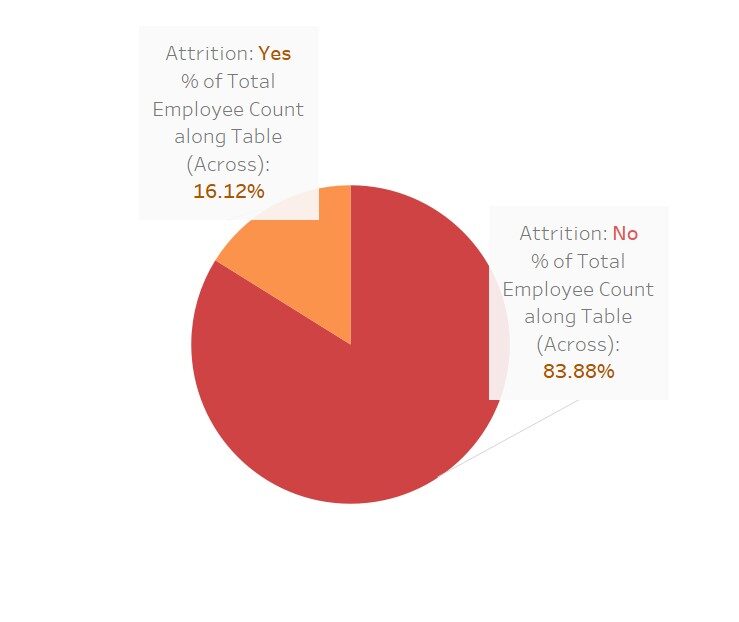
Eine schnelle Visualisierung, um zu sehen, wie stark sich diese Variablen auf die “tragen”
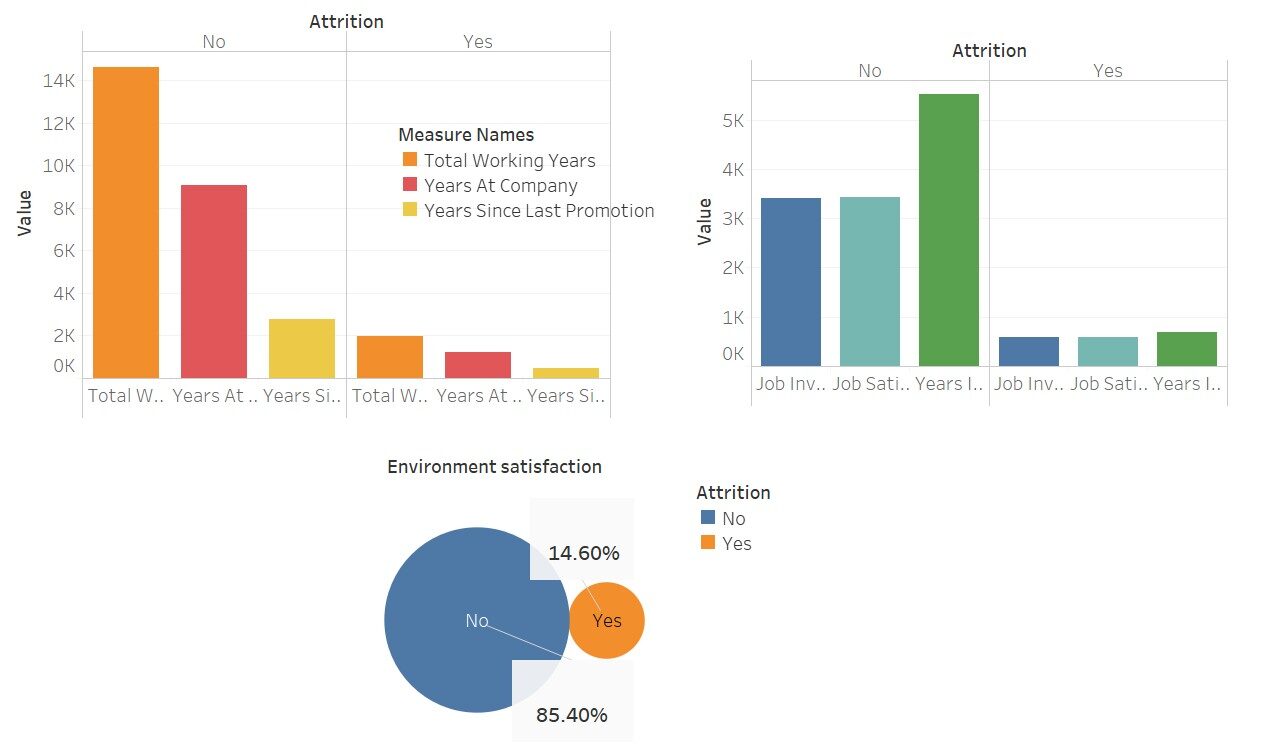
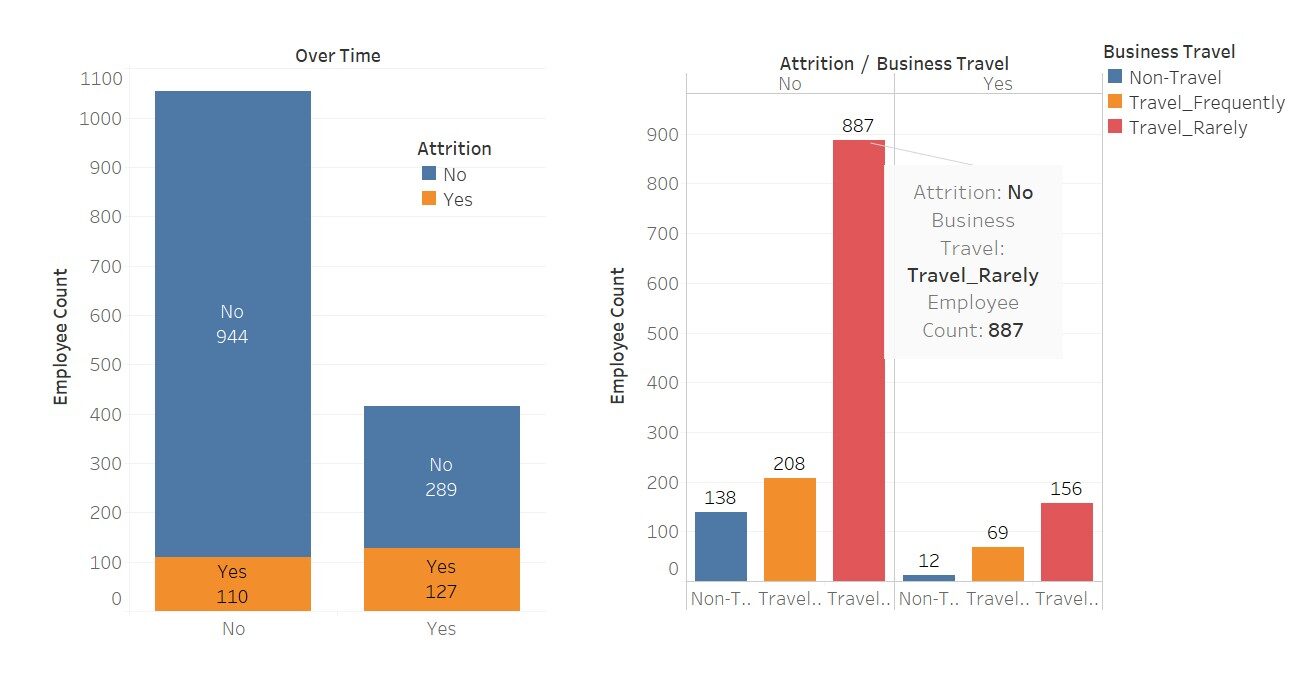
Hier habe ich Tableau für diese Visualisierungen verwendet; nicht schön Diese Software macht unsere Arbeit einfach einfacher.
Jetzt, wir können erkennen die Hoshmer-Lemes-Show Anpassungstest des Datensatzes, um die Genauigkeit der vorhergesagten Wahrscheinlichkeit des Modells zu beurteilen.
Die Hypothese ist:
H0: Das Modell passt gut.
H1: Das Modell passt nicht gut.
Und, p-Wert> 0,05 wir akzeptieren H0 und lehnen H1 ab.
Um den Test in R durchzuführen, müssen wir installieren die mkMisc Paket.
HLgof.test(fit=Trainingsmodell1$fitted.values,obs=Trainingsmodell1$y)

Hier, Wir können sehen, dass der p-Wert größer ist als 0.05, deshalb akzeptieren wir H0. Jetzt, es ist erwiesen, dass unser Modell gut angepasst ist.
Generieren einer ROC-Kurve für Trainingsdaten
Eine weitere Technik zur Analyse der Anpassungsgüte der logistischen Regression ist die ROC-Maßnahmen (Betriebseigenschaften des Empfängers). ROC-Maßnahmen sind sensitiv, Spezifität 1, falsch positiv und falsch negativ. Die beiden Maße, die wir ausgiebig verwenden, sind Sensitivität und Spezifität.. Die Empfindlichkeit misst die Güte der Genauigkeit des Modells, während die Spezifität die Schwäche des Modells misst.
Dazu müssen wir in R ein Paket installieren ProC.
Tausch = Rock(response=Trainingsmodell1$y,Prädiktor = Trainingmodel1$fitted.values,Plot=T) tauschen $ auc
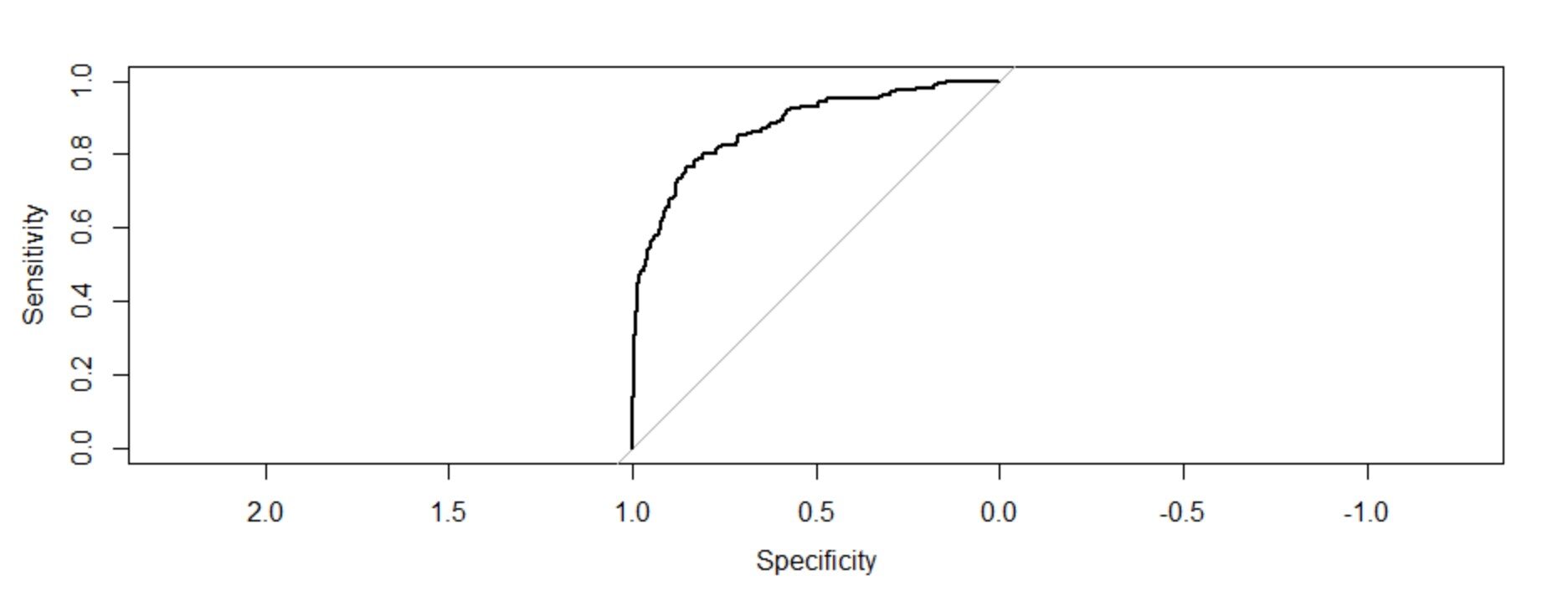
Die Fläche unter der Kurve: 0.8759
Interpretation der Figur:
Das Diagramm dieser beiden Messungen gibt uns ein konkaves Diagramm, das zeigt, wie die Sensitivität zunimmt 1 – die Spezifität nimmt zu, aber mit abnehmender Geschwindigkeit. Der C-Wert (AUC) o der Wert des Konkordanzindex ist das Maß für die Fläche unter der ROC-Kurve. Wenn c = 0,5, hätte bedeutet, dass das Modell nicht perfekt unterscheiden kann 0 Ja 1 Antworten. Dies impliziert dann, dass das ursprüngliche Modell nicht genau sagen kann, welche Mitarbeiter gehen und wer bleiben wird..
Aber hier können wir sehen, dass unser Wert c viel größer ist als 0.5. es ist 0,8759. Unser Modell kann perfekt unterscheiden zwischen 0 Ja 1. Deswegen, wir können erfolgreich schlussfolgern, dass es sich um ein gut angepasstes Modell handelt.
Erstellen der Bestenliste für den Trainingsdatensatz:
trpred=ifelse(test=Trainingsmodell1$fitted.values>0.5,ja = 1,nein=0) Tisch(Trainingsmodell1$y,trpred)
Die obigen Codesätze, der vorhergesagte Wert der Wahrscheinlichkeit größer als 0, .5, dann ist der Wert des Staates 1, sonst ist es 0. nach diesem Kriterium, Dieser Code benennt die Antworten neu “Jawohl” Ja “Nein” von “Tragen”. Jetzt, Es ist wichtig, den Prozentsatz der Vorhersagen zu verstehen, die der anfänglichen Annahme aus dem Datensatz entsprechen. Hier vergleichen wir das Paar (1-1) Ja (0-0).
Verfügen über 1025 Trainingsdaten. Wir haben vorausgesagt {(839 + 78) / 1025} * 100 =89% korrekt.
Vergleich des Ergebnisses mit den Testdaten:
Jetzt vergleichen wir das Modell mit den Testdaten. Es ist wie ein Präzisionstest.
testpred=predict.glm(object=Trainingmodel1,newdata=TestingData,Typ = "Antwort") testpred tsroc=roc(response=TestingData$Atrition,Prädiktor = Testpred,Plot=T) tsroc $ auc
Jetzt, wir haben Testdaten in das Trainingsmodell integriert und wir werden den ROC sehen.
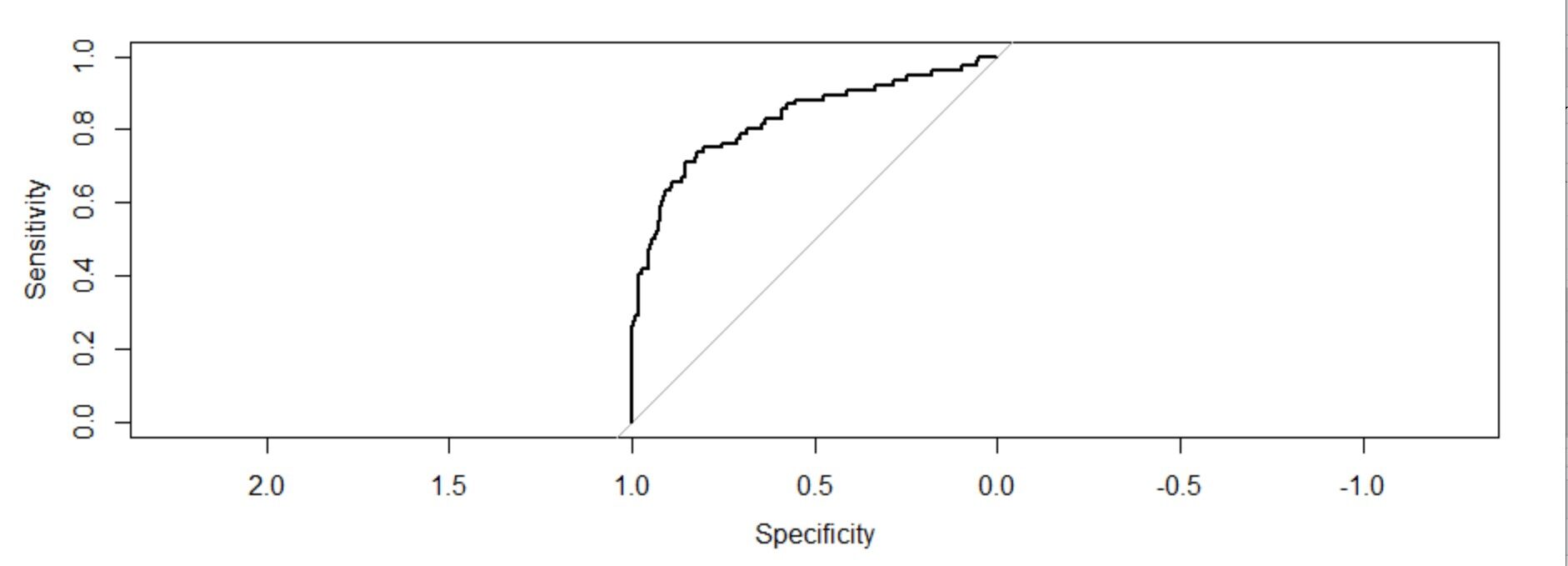
Die Fläche unter der Kurve: 0,8286 (c-Wert). Es ist auch weit überlegen 0,5. Es ist auch ein gut ausgestattetes Modell.
Erstellen Sie die Klassifizierungstabelle für den Testdatensatz
testpred=ifelse(test=testpred>0.5,ja=1,nein=0) Tisch(TestingData$Atrition,testpred)

Verfügen über 445 Testdaten. wir haben richtig vorhergesagt {(362 + 28) / 445} * 100 =87,64%.
Während, Wir können sagen, dass unser logistisches Regressionsmodell ein sehr gut angepasstes Modell ist. Mit diesem Modell können beliebige Daten zur Mitarbeiterabwanderung analysiert werden.
Was denkst du ist ein gutes Modell? Kommentiere unten
FAZIT:
Wir haben erfolgreich gelernt, die Mitarbeiterfluktuation mittels „LOGISTISCHER REGRESSION“ mit Hilfe der R-Software zu analysieren. Nur mit ein paar Codes und einem richtigen Datensatz, ein Unternehmen kann leicht nachvollziehen, um welche Bereiche es sich kümmern muss, um den Arbeitsplatz für seine Mitarbeiter komfortabler zu gestalten und die Energie seiner Humanressourcen für einen längeren Zeitraum wiederherzustellen.
Das empfohlene Bild stammt von trainingjournal.com
Link zu meinem LinkedIn-Profil:
https://www.linkedin.com/in/tiasa-patra-37287b1b4/





