
Bühne 1: Jede globale Bank hat heute mehr als 100 Millionen von Kunden machen jeden Monat Milliarden von Transaktionen.
Bühne 2: Social-Media-Websites oder E-Commerce-Websites verfolgen das Kundenverhalten auf der Website und geben dann Informationen weiter / relevantes Produkt.
Herkömmliche Systeme haben Schwierigkeiten, diese Größenordnung in der erforderlichen Geschwindigkeit und auf kosteneffektive Weise zu bewältigen.
Hier helfen Big-Data-Plattformen.. In diesem Artikel, wir präsentieren Ihnen die faszinierende Welt von Hadoop. Hadoop ist nützlich beim Umgang mit riesigen Datenmengen. Es kann den Prozess nicht beschleunigen, aber es gibt uns die Möglichkeit, parallele Verarbeitungsleistung zu nutzen, um große Datenmengen zu verarbeiten. Zusammenfassend, Hadoop gibt uns die Möglichkeit, mit der Komplexität von hohe Lautstärke, Geschwindigkeit und Datenvielfalt (im Volksmund bekannt als 3V).
Beachten Sie, dass, zusätzlich zu Hadoop, es gibt andere Big-Data-Plattformen, zum Beispiel, NoSQL (MongoDB ist am beliebtesten), wir werden sie später sehen.
Einführung in Hadoop
Hadoop ist ein komplettes Ökosystem von Open-Source-Projekten, das uns den Rahmen für den Umgang mit Big Data bietet.. Beginnen wir mit einem Brainstorming zu den potenziellen Herausforderungen im Umgang mit Big Data (in traditionellen Systemen) und dann sehen wir uns die Kapazität der Hadoop-Lösung an.
Folgende Herausforderungen fallen mir beim Umgang mit Big Data ein:
1. Hohe Kapitalinvestition in die Anschaffung eines Servers mit hoher Rechenleistung.
2. Viel Zeit investiert
3. Bei einer langen Anfrage, Stellen Sie sich vor, im letzten Schritt tritt ein Fehler auf. Sie werden viel Zeit mit diesen Iterationen verschwenden.
4. Schwierigkeiten beim Generieren von Abfragen zum Programm
So löst Hadoop all diese Probleme:
1. Hohe Kapitalinvestition in den Erwerb eines Hochdurchsatzservers: Hadoop-Cluster laufen auf normaler Basishardware und verwalten mehrere Kopien, um die Datenzuverlässigkeit zu gewährleisten. Ein Maximum von 4500 Maschinen zusammen mit Hadoop.
2. Viel Zeit investiert : Der Prozess ist in Teile unterteilt und läuft parallel, Zeit sparen. Ein Maximum von 25 Petabyte (1 PB = 1000 TB) Daten mit Hadoop.
3. Bei einer langen Anfrage, Stellen Sie sich vor, im letzten Schritt tritt ein Fehler auf. Sie werden viel Zeit mit diesen Iterationen verschwenden : Hadoop sichert Datensätze auf allen Ebenen. Führt auch Abfragen auf doppelte Datensätze aus, um Prozessverluste im Falle eines einzelnen Fehlers zu vermeiden. Diese Schritte machen die Hadoop-Verarbeitung präziser und genauer.
4. Schwierigkeiten beim Generieren von Abfragen zum Programm : Abfragen in Hadoop sind so einfach wie das Programmieren in einer beliebigen Sprache. Sie müssen nur die Art und Weise ändern, wie Sie eine Abfrage erstellen, um die parallele Verarbeitung zu ermöglichen.
Hadoop-Hintergrund
Mit einer Zunahme der Internetdurchdringung und Internetnutzung, Die von Google erfassten Daten sind von Jahr zu Jahr exponentiell gestiegen. Nur um Ihnen eine Schätzung dieser Zahl zu geben, In 2007 Google hat durchschnittlich 270 PB Daten pro Monat. Die gleiche Zahl stieg auf 20000 PB jeden Tag in 2009. Offensichtlich, Google brauchte eine bessere Plattform, um so riesige Datenmengen zu verarbeiten. Google hat ein Programmiermodell namens MapReduce implementiert, das könnte diese verarbeiten 20000 PB pro Tag. Google hat diese MapReduce-Operationen auf einem speziellen Dateisystem namens Google File System ausgeführt (GFS). Leider, GFS ist nicht Open Source.
Doug Cutting und Yahoo! Reverse Engineering des GFS-Modells und Aufbau eines verteilten Hadoop-Dateisystems (HDFS) parallel. Die Software oder das Framework, das HDFS und MapReduce unterstützt, wird als Hadoop bezeichnet. Hadoop ist Open Source und wird von Apache vertrieben.
Vielleicht interessiert es dich: Einführung in MapReduce
Hadoop-Verarbeitungs-Framework
Ziehen wir eine Analogie aus unserem täglichen Leben, um zu verstehen, wie Hadoop funktioniert. Die Basis der Pyramide eines jeden Unternehmens sind die Personen, die einzelne Steuerzahler sind. Sie können Analysten sein, Programmierer, Handarbeit, Köche, etc. Die Verwaltung Ihrer Arbeit ist der Projektmanager. Der Projektleiter ist für den erfolgreichen Abschluss der Aufgabe verantwortlich. Arbeit muss verteilt werden, reibungslose Koordination zwischen ihnen, etc. Was ist mehr, die meisten dieser Unternehmen haben einen Personalleiter, wer ist mehr daran interessiert, den Kader zu behalten.

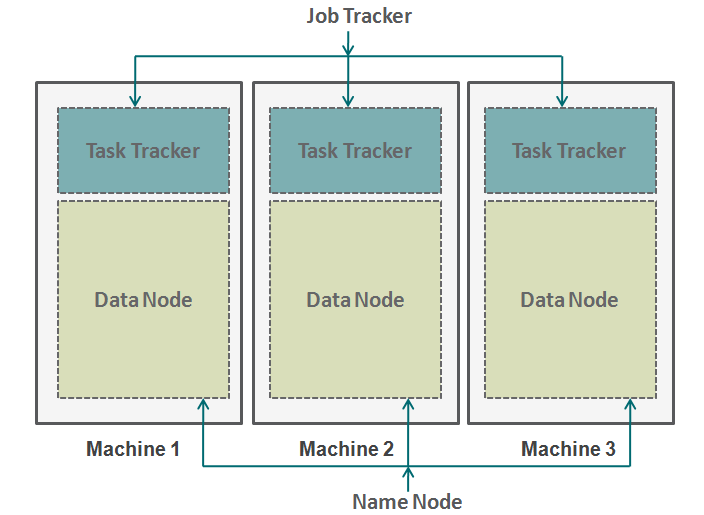
Hadoop funktioniert in einem ähnlichen Format. Unten haben wir die Maschinen parallel angeordnet. Diese Maschinen entsprechen in unserer Analogie dem einzelnen Steuerzahler. Jede Maschine hat einen Datenknoten und einen Jobtracker. Der Datenknoten wird auch als HDFS bezeichnet (Hadoop verteiltes Dateisystem) und Task-Tracker ist auch als Kartenverkleinerer bekannt.
Der Datenknoten enthält den gesamten Datensatz und der Aufgabentracker führt alle Operationen aus. Sie können sich den Aufgabentracker als Ihre Arme und Beine vorstellen, damit Sie eine Aufgabe und einen Datenknoten als Ihr Gehirn ausführen können, mit allen Informationen, die Sie verarbeiten möchten. Diese Maschinen arbeiten in Silos und es ist sehr wichtig, sie zu koordinieren. Aufgaben-Tracker (Projektleiter in unserer Analogie) an verschiedenen Maschinen werden durch einen Jobtracker koordiniert. Job Tracker stellt sicher, dass jeder Vorgang abgeschlossen ist und wenn auf einem Knoten ein Prozessfehler auftritt, Sie müssen einem Aufgaben-Tracker eine doppelte Aufgabe zuweisen. Der Jobtracker verteilt zudem die gesamte Aufgabe auf alle Maschinen.
Zweitens, ein benannter Knoten koordiniert alle Datenknoten. Es regelt die Verteilung der Daten, die an jede Maschine gehen. Es überprüft auch jede Art von Spülung, die in einer Maschine aufgetreten ist. Wenn ein solches Debugging auftritt, findet doppelte Daten, die an einen anderen Datenknoten gesendet wurden und dupliziert sie erneut. Sie können sich diesen Namensknoten als den People Manager in unserer Analogie vorstellen, die sich mehr um die Beibehaltung des gesamten Datensatzes kümmert.
Wann Sie Hadoop nicht verwenden sollten?
Bis jetzt, Wir haben gesehen, wie Hadoop den Umgang mit Big Data möglich gemacht hat. In einigen Szenarien wird die Hadoop-Implementierung jedoch nicht empfohlen. Unten sind einige dieser Szenarien:
- Datenzugriff mit geringer Latenz: schneller Zugriff auf kleine Datenmengen
- Änderung mehrerer Daten: Hadoop ist nur dann am besten geeignet, wenn es uns hauptsächlich um das Lesen von Daten und nicht um das Schreiben von Daten geht.
- Viele kleine Dateien: Hadoop passt besser in Szenarien, wo wir wenige, aber große Dateien haben.
Abschließende Anmerkungen
Dieser Artikel gibt Ihnen einen Einblick, wie Hadoop beim Umgang mit riesigen Datenmengen zur Rettung kommt. Es ist sehr wichtig zu verstehen, wie Hadoop funktioniert, bevor Sie mit der Codierung beginnen. Dies liegt daran, dass Sie die Art und Weise ändern müssen, wie Sie an einen Code denken. Jetzt müssen Sie darüber nachdenken, die Parallelverarbeitung zu aktivieren. Sie können in Hadoop viele verschiedene Arten von Prozessen ausführen, aber Sie müssen alle diese Codes in eine Kartenreduktionsfunktion umwandeln. In den nächsten Artikeln, wir erklären, wie Sie Ihre einfache Logik in Hadoop-basierte Map-Reduce-Logik umwandeln können. Wir werden auch spezifische Fallstudien in der Sprache R durchführen, um ein solides Verständnis der Hadoop-Anwendung zu erlangen..
War der Artikel hilfreich für dich? Teilen Sie uns alle praktischen Hadoop-Anwendungen mit, die Ihnen bei der Arbeit begegnet sind. Teilen Sie uns Ihre Meinung zu diesem Artikel im unten stehenden Feld mit..





