Einführung
Explorative Datenanalyse ist heute eine der Best Practices in der Datenwissenschaft. Beim Berufseinstieg in Data Science, Menschen kennen im Allgemeinen den Unterschied zwischen Datenanalyse und explorativer Datenanalyse nicht. Es gibt keinen großen Unterschied zwischen den beiden, aber sie haben beide unterschiedliche zwecke.

Explorative Datenanalyse (EDA): explorative Datenanalyse ist eine Ergänzung Inferenzstatistik, was bei Regeln und Formeln eher starr ist. Auf fortgeschrittenem Niveau, Bei der EDA geht es darum, den Datensatz aus verschiedenen Blickwinkeln zu betrachten, zu beschreiben und dann zusammenzufassen.
Datenanalyse: Datenanalyse ist die Statistik und Wahrscheinlichkeit, Trends im Datensatz zu entdecken. Wird verwendet, um historische Daten mithilfe einiger Analysetools anzuzeigen. Hilft, Informationen aufzuschlüsseln, um Metriken zu transformieren, Zahlen und Fakten zu Verbesserungsinitiativen.
Explorative Datenanalyse (EDA)
Wir werden einen Datensatz untersuchen und eine explorative Datenanalyse in Python durchführen. Sie können unsere Python-Kurs online um mit Python an Bord zu kommen.
Die wichtigsten Themen, die behandelt werden sollen, sind wie folgt:
– Fehlenden Wert behandeln
– Duplikate entfernen
– Behandlung von Ausreißern
– Normalisierung und Skalierung (numerische Variablen)
– Codierung kategorialer Variablen (Dummy-Variablen)
– Bivariate Analyse
# Bibliotheken importieren

# Laden des Datensatzes
Wir werden die Excel-Datei von EDA-Autos mit Pandas laden. Dafür, Wir werden die read_excel-Datei verwenden.
Boxplot nach Entfernen von Ausreißern
# Grundlegende Datenexploration
In diesem Schritt, Wir führen die folgenden Operationen durch, um zu überprüfen, woraus der Datensatz besteht. Wir werden folgende Dinge prüfen:
– Datensatz-Manager
– die Form des Datensatzes
– Datensatzinformationen
– Datensatzzusammenfassung
- Die Kopffunktion zeigt Ihnen die besten Datensätze im Datensatz an. Standardmäßig, Python zeigt dir nur die 5 Hauptregister.
-
Das Shape-Attribut teilt uns eine Reihe von Beobachtungen und Variablen mit, die wir im Datensatz haben. Es wird verwendet, um die Dimension der Daten zu überprüfen. Der Automobildatensatz hat 303 Beobachtungen und 13 Variablen im Datensatz.

-
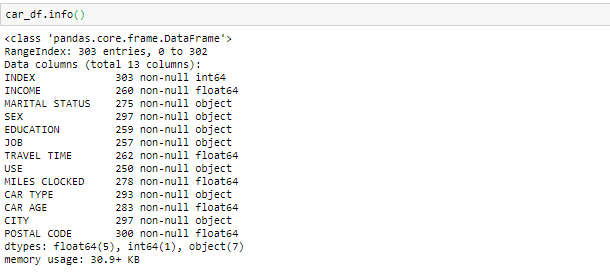
die Info () verwendet, um Informationen über Daten und Datentypen jedes jeweiligen Attributs zu überprüfen.

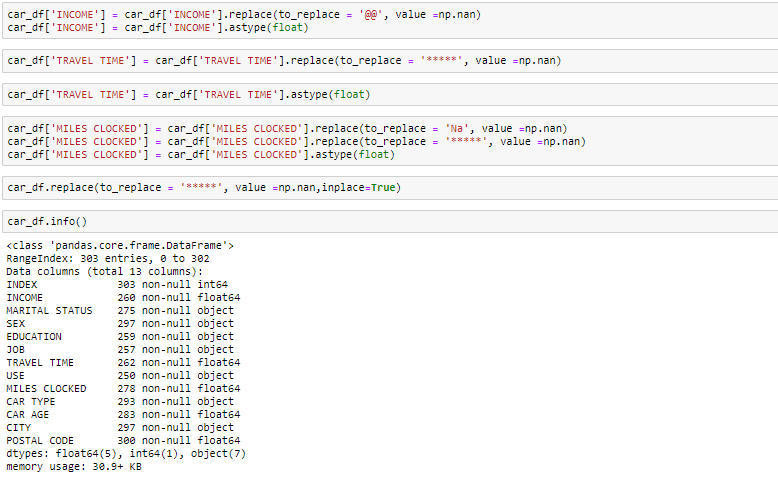
Indem Sie sich die Daten in der Hauptfunktion und in den Informationen ansehen, wir wissen, dass die Variable Einkommen und die Reisezeit vom Datentyp Floating anstelle des Objekts sind. Dann machen wir es zum Schwimmer. Was ist mehr, es gibt einige ungültige Werte wie @@ und ‘*"In den Daten, die wir als fehlende Werte behandeln".

-
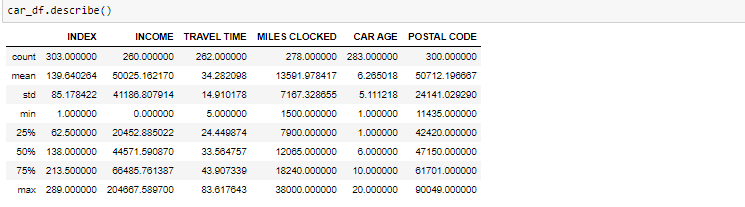
Die beschriebene Methode hilft zu sehen, wie die Daten für numerische Werte verteilt wurden. Wir können den Mindestwert deutlich sehen, Mittelwerte, verschiedene Perzentilwerte und Maximalwerte.


Umgang mit fehlenden Werten
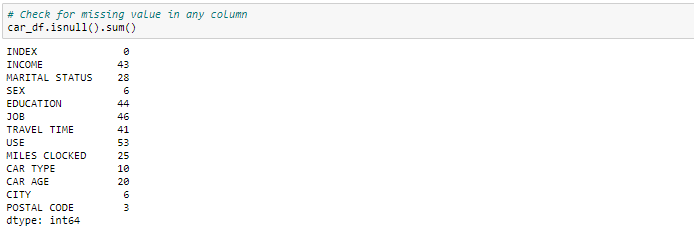
Wir können sehen, dass wir in den jeweiligen Spalten mehrere fehlende Werte haben. Es gibt mehrere Möglichkeiten, mit fehlenden Werten im Datensatz umzugehen. Und welche Technik Sie verwenden sollten, wenn es wirklich von der Art der Daten abhängt, mit denen Sie es zu tun haben.
- Eliminieren Sie fehlende Werte: in diesem Fall, wir eliminieren die fehlenden Werte dieser Variablen. Bei sehr wenigen fehlenden Werten, kann sie löschen.
- Mit Mittelwert imputieren: für die numerische Spalte, fehlende Werte kannst du durch Mittelwerte ersetzen. Vor dem Ersetzen durch den Mittelwert, Es ist ratsam zu überprüfen, dass die Variable keine Extremwerte aufweisen sollte. dh Ausreißer.
- Mit Medianwert imputieren: für die numerische Spalte, fehlende Werte kannst du auch durch Medianwerte ersetzen. Falls Sie extreme Werte haben, als Ausreißer, Es ist ratsam, die Medianmethode zu verwenden.
- Mit Moduswert imputieren: für die kategoriale Spalte, Sie können fehlende Werte durch Moduswerte ersetzen, nämlich, das häufige.
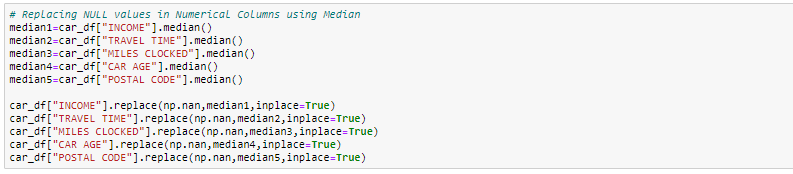
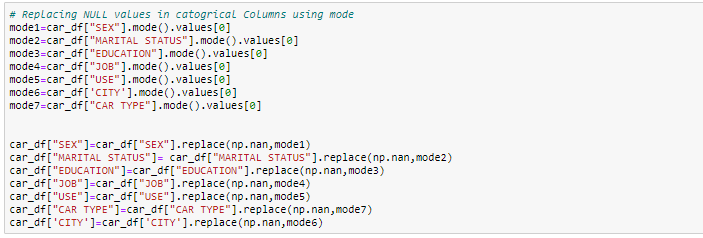
In dieser Übung, wir werden die numerischen Spalten durch Medianwerte ersetzen und, für kategoriale Spalten, wir werden die fehlenden Werte löschen.

Umgang mit doppelten Datensätzen
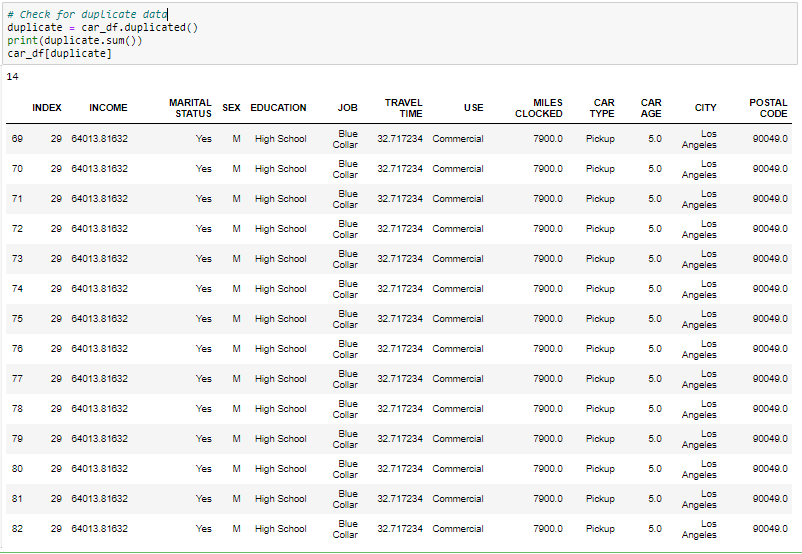
Seit wir ... Haben 14 doppelte Datensätze in den Daten, Wir werden es aus dem Datensatz entfernen, um nur unterschiedliche Datensätze zu erhalten. Nach dem Entfernen des Duplikats, Wir prüfen, ob die Duplikate aus dem Datensatz entfernt wurden oder nicht.
![]()

Umgang mit Ausreißern
Ausreißer, als die extremsten Beobachtungen, kann das Maximum oder Minimum der Stichprobe enthalten, die beiden, je nachdem ob sie extrem hoch oder niedrig sind. Aber trotzdem, das Maximum und das Minimum der Stichprobe sind nicht immer Ausreißer, da sie möglicherweise nicht ungewöhnlich weit von anderen Beobachtungen entfernt sind.
Ausreißer identifizieren wir in der Regel mit Hilfe des Boxplots, Hier zeigt das Boxplot also einige der Datenpunkte außerhalb des Datenbereichs.
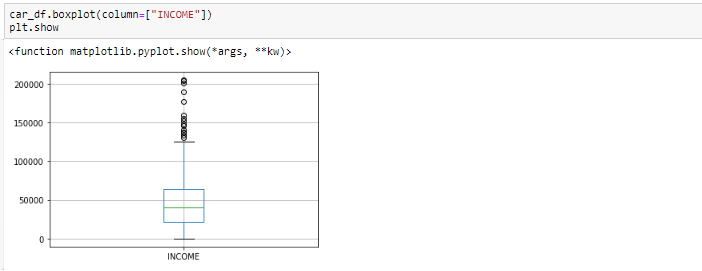
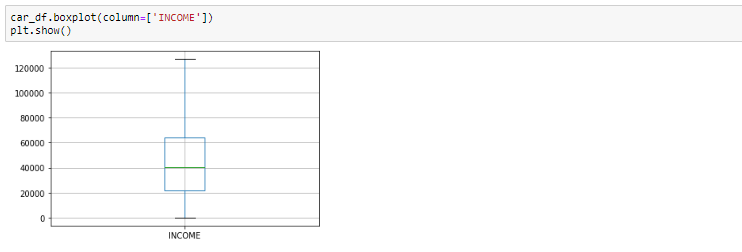
Boxplot vor dem Entfernen von Ausreißern
Blick auf den Boxplot, es scheint, dass die Variablen INCOME, haben Ausreißer in den Variablen. Diese Ausreißer müssen berücksichtigt werden und es gibt mehrere Möglichkeiten, damit umzugehen:
- Entfernen Sie den Ausreißer
- Ersetzen Sie den Ausreißer mit dem IQR
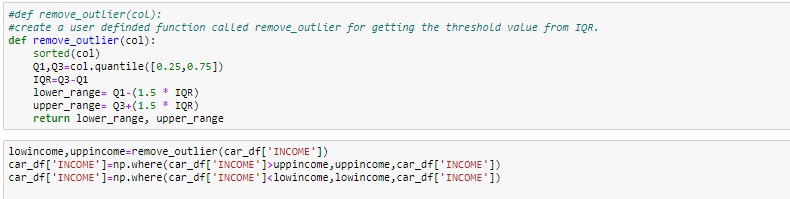
#Boxplot Nach dem Entfernen des Ausreißers
Bivariate Analyse
Wenn wir über bivariate Analyse sprechen, bedeutet analysieren 2 Variablen. Da wir wissen, dass es numerische und kategoriale Variablen gibt, Es gibt eine Möglichkeit, diese Variablen wie unten gezeigt zu analysieren:
-
Numerisch vs. numerisch
1. Ausbreitungsdiagramm
2. Liniendiagramm
3. Heatmap für Korrelation
4. Gemeinschaftsgrundstück -
Kategorial vs. Numerisch
1. Balkengrafik
2. Violinrahmen
3. Kategorialer Boxplot
4.warmes Grundstück -
Zwei kategoriale Variablen
1. Balkengrafik
2. Gruppiertes Balkendiagramm
3. Punktdiagramm
Wenn wir den Zusammenhang finden müssen-
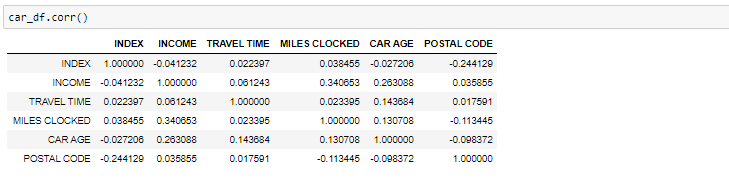
Korrelation zwischen allen Variablen
Normalisieren und skalieren
Häufig, die Variablen im Datensatz haben unterschiedliche Skalen, nämlich, eine Variable ist in Millionen und andere in nur 100. Zum Beispiel, in unserem Datensatz, Einkommen hat Werte in Tausend und Alter nur zweistellig. Da die Daten dieser Variablen unterschiedliche Skalen haben, Es ist schwierig, diese Variablen zu vergleichen.
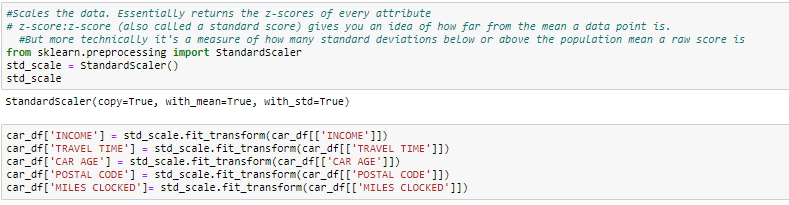
Die Skala der Eigenschaften (auch als Datennormalisierung bekannt) ist die Methode zur Standardisierung des Merkmalsumfangs der Daten. Da der Bereich der Datenwerte stark variieren kann, wird ein notwendiger Schritt in der Datenvorverarbeitung bei der Verwendung von maschinellen Lernalgorithmen.
Bei dieser Methode, wir konvertieren Variablen mit unterschiedlichen Messskalen in eine einzige Skala. StandardScaler normalisiert die Daten mit der Formel (x-Mittelwert) / Standardabweichung. Wir werden dies nur für numerische Variablen tun.
CODIERUNG
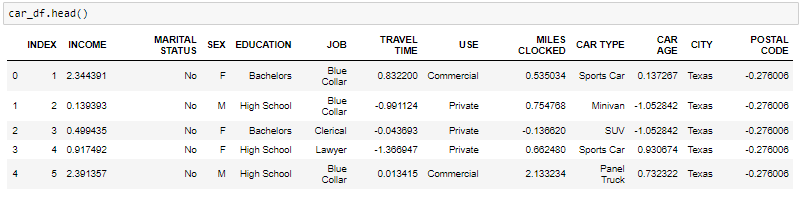
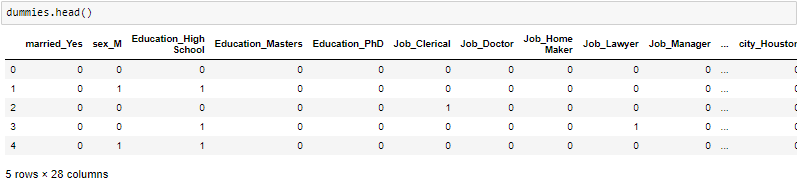
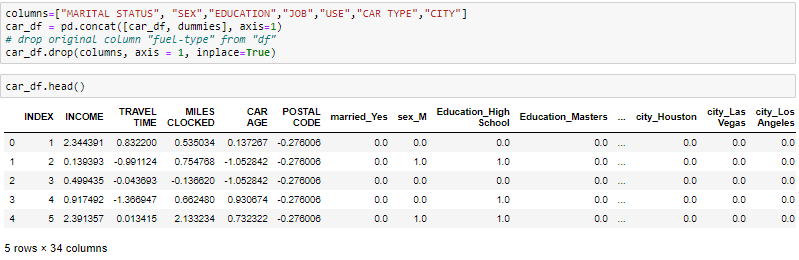
One-Hot-Encoding wird verwendet, um Dummy-Variablen zu erstellen, um die Kategorien in einer kategorialen Variablen in den Merkmalen jeder Kategorie zu ersetzen und sie mithilfe von . darzustellen 1 Ö 0 je nach Vorhandensein oder Fehlen des kategorialen Werts im Register.
Das ist notwendig, da maschinelle Lernalgorithmen nur mit numerischen Daten arbeiten. Aus diesem Grund ist es notwendig, die kategoriale Spalte in eine numerische umzuwandeln.
get_dummies ist die Methode, die für jede kategoriale Variable eine Dummy-Variable erstellt.

Über den Autor

Ritika Singh | – Datenwissenschaftler
Ich bin von Beruf Data Scientist und Blogger aus Leidenschaft. Ich arbeite seit mehr als an Machine-Learning-Projekten 2 Jahre. Hier finden Sie Artikel zum Thema „Maschinelles Lernen“, Statistiken, Tiefes Lernen, NLP und Künstliche Intelligenz".





