Notiz: Dieser Artikel wurde ursprünglich veröffentlicht auf 10 Oktober 2014 und der 27 Marsch 2018.
Überblick
- Den nächsten Nachbarn verstehen (KNN): einer der beliebtesten maschinellen Lernalgorithmen
- Erfahren Sie, wie kNN in Python funktioniert
- Wählen Sie den richtigen Wert von k in einfachen Worten
Einführung
In den vier Jahren meiner Data Science Karriere, Ich habe mehr gebaut als 80% von Klassifikationsmodellen und nur ein 15-20% Regressionsmodelle. Diese Verhältnisse lassen sich mehr oder weniger auf die gesamte Branche verallgemeinern. Der Grund für diese Neigung zu Klassifizierungsmodelle ist, dass die meisten analytischen Probleme eine Entscheidung beinhalten.
Zum Beispiel, ob sich ein Kunde abnutzt oder nicht, wenn wir für digitale Kampagnen zu Client X gehen, ob der Kunde ein hohes Potenzial hat oder nicht, etc. Diese Analysen sind aufschlussreicher und direkt mit einer Implementierungs-Roadmap verknüpft.

In diesem Artikel, Wir sprechen über ein anderes weit verbreitetes maschinelles Lernen. Klassifizierungstechnikmich genannt K-nächste Nachbarn (KNN). Unser Fokus wird hauptsächlich darauf liegen, wie der Algorithmus funktioniert und wie sich der Eingabeparameter auf den Output auswirkt / Vorhersage.
Notiz: Menschen, die es vorziehen, durch Videos zu lernen, können dasselbe durch unseren kostenlosen Kurs lernen – K-Nearest Neighbours-Algorithmus (KNN) in Python und R. Und wenn Sie ein absoluter Anfänger in Data Science und Machine Learning sind, Sehen Sie sich unser Certified BlackBelt-Programm an:
Inhaltsverzeichnis
- Wann verwenden wir den KNN-Algorithmus?
- Wie funktioniert der KNN-Algorithmus?
- Wie wählen wir den K-Faktor?
- Brechen sie ab – KNN-Pseudocode
- Python-Implementierung von Grund auf neu
- Vergleich unseres Modells mit scikit-learn
Wann verwenden wir den KNN-Algorithmus?
KNN kann für prädiktive Klassifizierungs- und Regressionsprobleme verwendet werden. Aber trotzdem, am häufigsten bei Klassifizierungsproblemen in der Industrie verwendet. Um jede Technik zu bewerten, wir schauen uns normalerweise an 3 wichtige Aspekte:
1. Einfache Interpretation der Ausgabe
2. Berechnungszeit
3. Vorhersagekraft
Nehmen wir einige Beispiele, um KNN auf die Waage zu stellen:
 KNN-Algorithmus-Messen über alle Betrachtungsparameter. Es wird häufig wegen seiner einfachen Interpretation und der geringen Rechenzeit verwendet.
KNN-Algorithmus-Messen über alle Betrachtungsparameter. Es wird häufig wegen seiner einfachen Interpretation und der geringen Rechenzeit verwendet.
Wie funktioniert der KNN-Algorithmus?
Nehmen wir einen einfachen Fall, um diesen Algorithmus zu verstehen. Unten ist eine Erweiterung der roten Kreise (RC) und grüne Quadrate (GS):
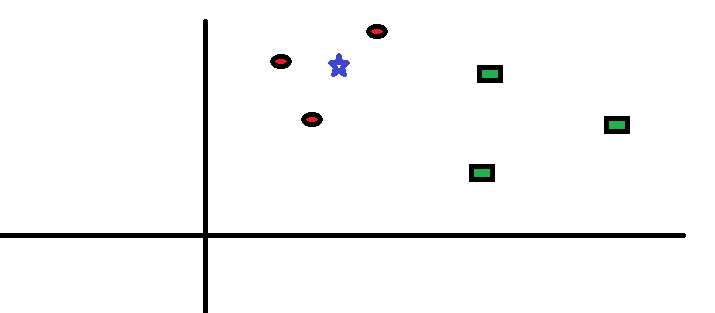 Er will die Klasse des blauen Sterns herausfinden (BS). BS kann RC oder GS sein und sonst nichts. Der Algorithmus “K” de KNN ist der nächste Nachbar, für den wir stimmen wollen. Nehmen wir an, K = 3. Deswegen, Jetzt machen wir einen Kreis mit BS als Mittelpunkt, der so groß ist, dass er nur drei Datenpunkte in der Ebene einschließt. Bitte beachten Sie das folgende Diagramm für weitere Details:
Er will die Klasse des blauen Sterns herausfinden (BS). BS kann RC oder GS sein und sonst nichts. Der Algorithmus “K” de KNN ist der nächste Nachbar, für den wir stimmen wollen. Nehmen wir an, K = 3. Deswegen, Jetzt machen wir einen Kreis mit BS als Mittelpunkt, der so groß ist, dass er nur drei Datenpunkte in der Ebene einschließt. Bitte beachten Sie das folgende Diagramm für weitere Details:
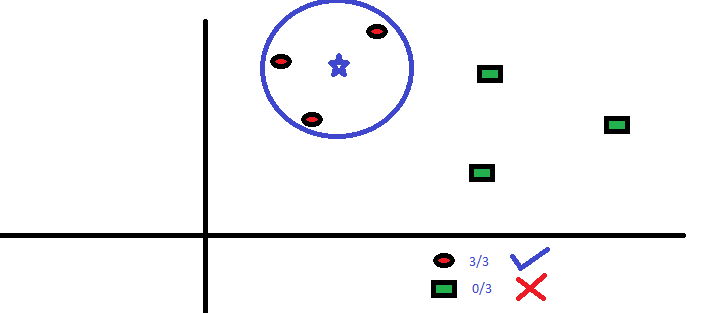 Die drei nächsten Punkte zu BS sind alle RC. Deswegen, mit einem guten Maß an Selbstvertrauen, wir können sagen, dass die BS zur RC-Klasse gehören sollte. Hier, Die Wahl wurde sehr offensichtlich, da die drei Stimmen der nächsten Nachbarn an RC gingen. Die Wahl des Parameters K ist bei diesem Algorithmus sehr wichtig. Dann, Wir werden verstehen, welche Faktoren zu berücksichtigen sind, um das beste K . zu ermitteln.
Die drei nächsten Punkte zu BS sind alle RC. Deswegen, mit einem guten Maß an Selbstvertrauen, wir können sagen, dass die BS zur RC-Klasse gehören sollte. Hier, Die Wahl wurde sehr offensichtlich, da die drei Stimmen der nächsten Nachbarn an RC gingen. Die Wahl des Parameters K ist bei diesem Algorithmus sehr wichtig. Dann, Wir werden verstehen, welche Faktoren zu berücksichtigen sind, um das beste K . zu ermitteln.
Wie wählen wir den K-Faktor?
Versuchen wir zunächst zu verstehen, was genau K den Algorithmus beeinflusst. Wenn wir das letzte Beispiel sehen, seit der 6 Trainingsbeobachtungen bleiben konstant, mit einem gegebenen K-Wert können wir für jede Klasse Grenzen setzen. Diese Grenzen werden RC von GS trennen. Auf die gleiche Weise, Versuchen wir, die Wirkung des Wertes zu sehen “K” in den Grenzen der Klasse. Im Folgenden sind die unterschiedlichen Grenzen aufgeführt, die die beiden Klassen mit unterschiedlichen Werten von K . trennen.
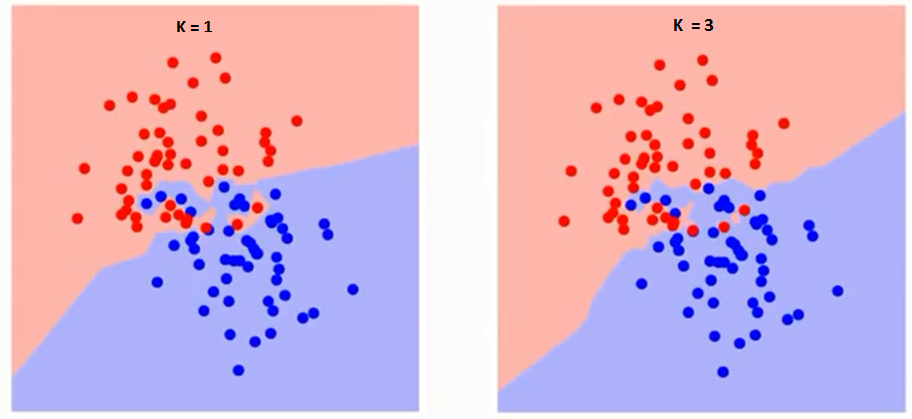
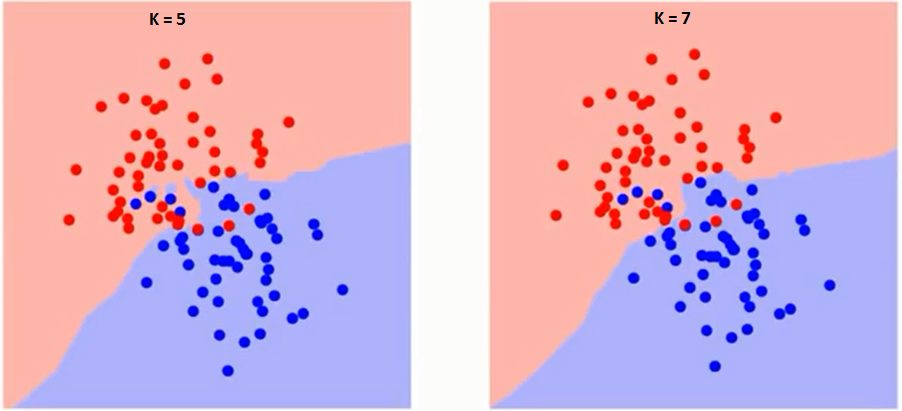
Wenn man genau hinschaut, Sie können sehen, dass der Grenzwert mit zunehmendem Wert von K glatter wird. Mit zunehmendem K ins Unendliche, es wird endlich ganz blau oder ganz rot, abhängig von der Gesamtmehrheit. Die Trainingsfehlerrate und die Validierungsfehlerrate sind zwei Parameter, die wir benötigen, um auf verschiedene K-Werte zuzugreifen.. Unten ist die Kurve für die Trainingsfehlerrate mit einem variablen Wert von K:
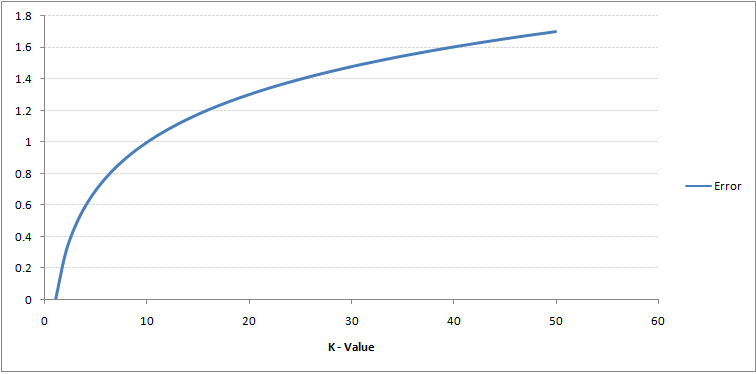 Wie du siehst, die Fehlerrate in K = 1 ist für die Trainingsstichprobe immer null. Dies liegt daran, dass der Punkt, der jedem Trainingsdatenpunkt am nächsten liegt, sich selbst ist, also ist die Vorhersage immer genau mit K = 1. Wenn die Validierungsfehlerkurve ähnlich gewesen wäre, unsere Wahl für K wäre gewesen 1. Unten ist die Validierungsfehlerkurve mit einem variablen Wert von K:
Wie du siehst, die Fehlerrate in K = 1 ist für die Trainingsstichprobe immer null. Dies liegt daran, dass der Punkt, der jedem Trainingsdatenpunkt am nächsten liegt, sich selbst ist, also ist die Vorhersage immer genau mit K = 1. Wenn die Validierungsfehlerkurve ähnlich gewesen wäre, unsere Wahl für K wäre gewesen 1. Unten ist die Validierungsfehlerkurve mit einem variablen Wert von K:
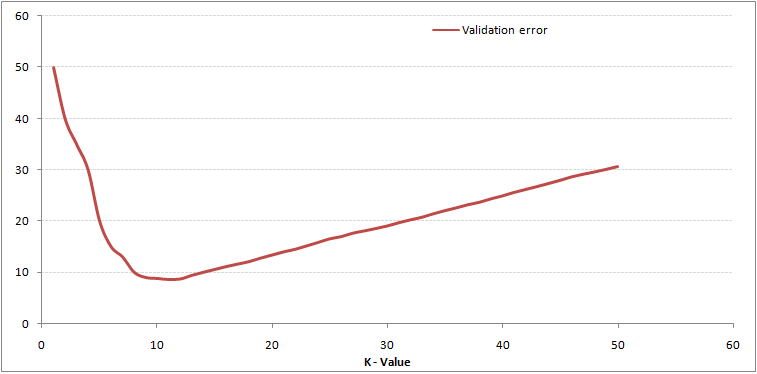 Damit ist die Geschichte geklärt. Und K = 1, wir haben die grenzen überschritten. Deswegen, die Fehlerquote nimmt zunächst ab und erreicht ein Minimum. Nach dem Mindestpunkt, steigt mit steigendem K. Um den optimalen Wert von K . zu erhalten, kann Training und anfängliche Datensatzvalidierung trennen. Zeichnen Sie nun die Validierungsfehlerkurve, um den optimalen Wert von K . zu erhalten. Dieser Wert von K sollte für alle Vorhersagen verwendet werden.
Damit ist die Geschichte geklärt. Und K = 1, wir haben die grenzen überschritten. Deswegen, die Fehlerquote nimmt zunächst ab und erreicht ein Minimum. Nach dem Mindestpunkt, steigt mit steigendem K. Um den optimalen Wert von K . zu erhalten, kann Training und anfängliche Datensatzvalidierung trennen. Zeichnen Sie nun die Validierungsfehlerkurve, um den optimalen Wert von K . zu erhalten. Dieser Wert von K sollte für alle Vorhersagen verwendet werden.
Die oben genannten Inhalte können mit unserem kostenlosen Kurs intuitiver verstanden werden: Algorithmus der nächsten Nachbarn (KNN) in Python und R
Brechen sie ab – KNN-Pseudocode
Wir können ein KNN-Modell implementieren, indem wir die folgenden Schritte ausführen:
- Lade Daten
- Initialisieren Sie den Wert von k
- Um die vorhergesagte Klasse zu erhalten, wiederholen von 1 bis zur Gesamtzahl der Trainingsdatenpunkte
- Berechnen Sie den Abstand zwischen den Testdaten und jeder Zeile der Trainingsdaten. Hier verwenden wir die euklidische Distanz als unsere Distanzmetrik, da es die beliebteste Methode ist. Die anderen Metriken, die verwendet werden können, sind Chebyshev, Kosinus, etc.
- Sortieren Sie die berechneten Entfernungen in aufsteigender Reihenfolge basierend auf den Entfernungswerten
- Holen Sie sich die ersten k Zeilen der geordneten Matrix
- Holen Sie sich die häufigste Klasse aus diesen Zeilen
- Gibt die vorhergesagte Klasse zurück
Python-Implementierung von Grund auf neu
Wir werden den beliebten Iris-Datensatz verwenden, um unser KNN-Modell zu erstellen. Sie können es herunterladen von hier.
Vergleich unseres Modells mit scikit-learn
von sklearn.neighbors importieren KNeighborsClassifier wieher = KNeighborsClassifier(n_nachbarn=3) wieher.fit(data.iloc[:,0:4], Daten['Name']) # Vorhergesagte Klasse drucken(wieher.vorhersagen(Prüfung)) -> ['Iris-Virginica'] # 3 nächste Nachbarn drucken(nachbar.nachbarn(Prüfung)[1]) -> [[141 139 120]]
Wir können sehen, dass beide Modelle dieselbe Klasse vorhergesagt haben ('Iris-Virginica') und die gleichen nächsten Nachbarn ( [141 139 120] ). Deswegen, Wir können daraus schließen, dass unser Modell wie erwartet funktioniert.
Implementierung von kNN in R
Paso 1: Importieren Sie die Daten
Paso 2: Daten überprüfen und Datenzusammenfassung berechnen
Produktion
#Top-Beobachtungen in den Daten KelchblattLänge KelchblattBreite BlütenblattLänge BlütenblattBreite Name 1 5.1 3.5 1.4 0.2 Iris-seidig 2 4.9 3.0 1.4 0.2 Iris-seidig 3 4.7 3.2 1.3 0.2 Iris-seidig 4 4.6 3.1 1.5 0.2 Iris-seidig 5 5.0 3.6 1.4 0.2 Iris-seidig 6 5.4 3.9 1.7 0.4 Iris-setosa #Überprüfe die Abmessungen der Daten [1] 150 5 #Fassen Sie die Daten zusammen KelchblattLänge KelchblattBreite BlütenblattLänge BlütenblattBreite Name Mindest. :4.300 Mindest. :2.000 Mindest. :1.000 Mindest. :0.100 Iris-seidig :50 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 Iris-Versicolor:50 Median :5.800 Median :3.000 Median :4.350 Median :1.300 Iris-Virginica :50 Bedeuten :5.843 Bedeuten :3.054 Bedeuten :3.759 Bedeuten :1.199 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800 Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Paso 3: Teile die Daten
Paso 4: Berechnen Sie die euklidische Distanz
Paso 5: schreibe die Funktion zur Vorhersage von kNN
Paso 6: Berechnung des Labels (Name) für K = 1
Produktion
Für K=1 [1] "Iris-Virginica"
Auf die gleiche Weise, kann andere Werte von K . berechnen.
Vergleich unserer Vorhersagefunktion kNN mit der Bibliothek “Klasse”
Produktion
Für K=1 [1] "Iris-Virginica"
Wir können sehen, dass beide Modelle dieselbe Klasse vorhergesagt haben ('Iris-Virginica').
Abschließende Anmerkungen
Der KNN-Algorithmus ist einer der einfachsten Klassifikationsalgorithmen. Auch bei dieser Einfachheit, kann sehr wettbewerbsfähige Ergebnisse liefern. Der KNN-Algorithmus kann auch für Regressionsprobleme verwendet werden. Der einzige Unterschied zu der diskutierten Methodik besteht darin, dass Durchschnittswerte der nächsten Nachbarn verwendet werden, anstatt für die nächsten Nachbarn zu stimmen.. KNN kann in einer einzigen Zeile in R . kodiert werden. Ich muss noch untersuchen, wie wir den KNN-Algorithmus in SAS verwenden können.
War der Artikel hilfreich für dich? Haben Sie in letzter Zeit andere Tools für maschinelles Lernen verwendet?? Planen Sie, KNN bei Ihren geschäftlichen Problemen einzusetzen?? Wenn ja, Sag uns, wie du es vorhast.





