This post was released as part of the Data Science Blogathon
Introduction
As a data scientist, web scraping is one of the vital skills you need to master, and you should look for useful data, collect and pre-process data so that your results are meaningful and accurate.
Before we dive into the tools that could aid in data mining activities, let us confirm that this activity is legal given that web scraping has been a gray legal area. The court of EE. UU. Fully legalized web scraping of publicly available data on 2020. It means that if you found information online (like wiki posts), then it is legal to scrape the data.
Even so, When you do it, be sure to:
- Not to reuse or republish the data in a manner that violates copyright.
- That you comply with the terms of service of the web portal you are scraping.
- That you have a fair tracking rate.
- Do not try to extract private parts of the web portal.
As long as it does not violate the above terms, your web scraping activity will be on the legal side.
I think some of you might have used BeautifulSoup and requests to collect the data and pandas to analyze it for your projects. This post will give you five web scraping tools that do not include BeautifulSoup; is free to use and collects the data for your next project.
The creator of Common Crawl created this tool because it assumes that everyone should have the ability to explore and perform analysis of the data around them and discover useful information.. They contribute high-quality data that was only open to large institutions and research institutes to any prying mind at no cost to encourage their open source beliefs..
You can use this tool without worrying about fees or any other financial difficulties. If you are a student, a newbie diving into data science or just an eager person who loves to explore knowledge and discover new trends, this tool would be useful. Make web page raw data and word extracts available as open data sets. It also offers resources for instructors that teach data analysis and support for non-code-based use cases..
Go through website for more information on using data sets and alternatives for extracting the data.
Crawly is another alternative, especially if you just need to extract simple data from a web portal or if you want to extract data in CSV format so that you can examine it without writing any code. User must enter a URL, an email identification to send the extracted data, the format of the required data (choose between CSV or JSON) and ready, the extracted data is in your inbox for use.
One can use JSON data and parse it using Pandas and Matplotlib, or any other programming language. If you are a newbie to data science and web scraping, not a programmer, this is good and has its limitations. A limited set of HTML tags including title can be extracted, Author, Image url and editor.
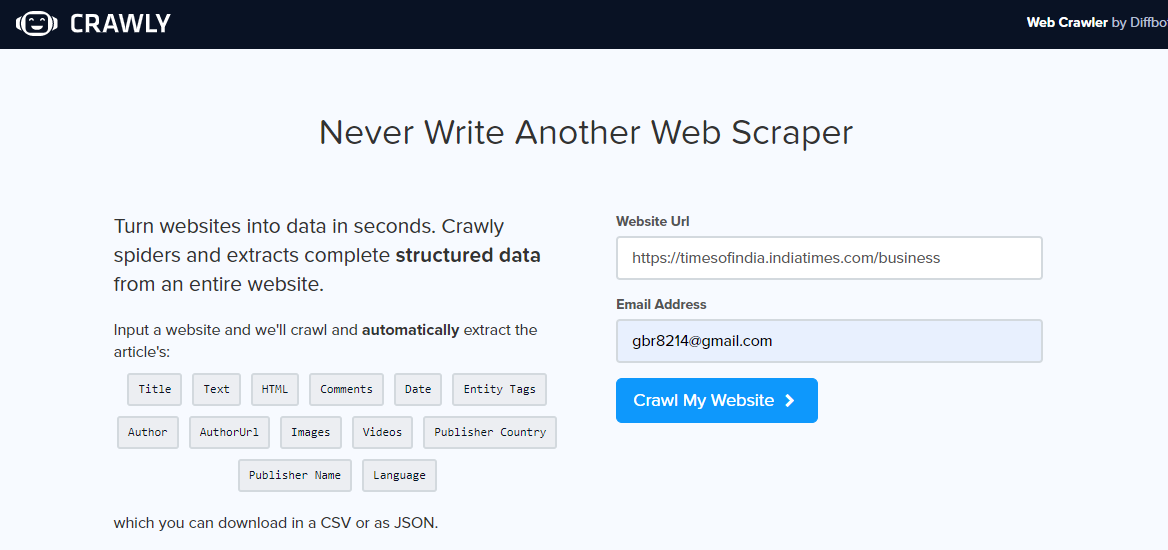
Once you have opened the tracking web portal, enter url to scrape, select the data format and your email ID to receive the data. Check your inbox to see the data.
The content grabber is a flexible tool if you like to scratch a web page and don't want to specify other parameters, user can do it using its simple GUI. Even so, provides the option of full control of extraction parameters to customize.
User can schedule scraping of information from the web automatically, is one of its advantages. Nowadays, we all know that web pages are updated regularly, so frequent content extraction would be helpful.
Offers various extracted data formats like CSV, JSON a SQL Server o MySQL.
A quick example to scrape the data
You can use this tool to visually navigate the web portal and click on data items in the order you want to collect them.. It will automatically detect the correct action type and provide default names for each command as it builds the agent based on the specified content items.
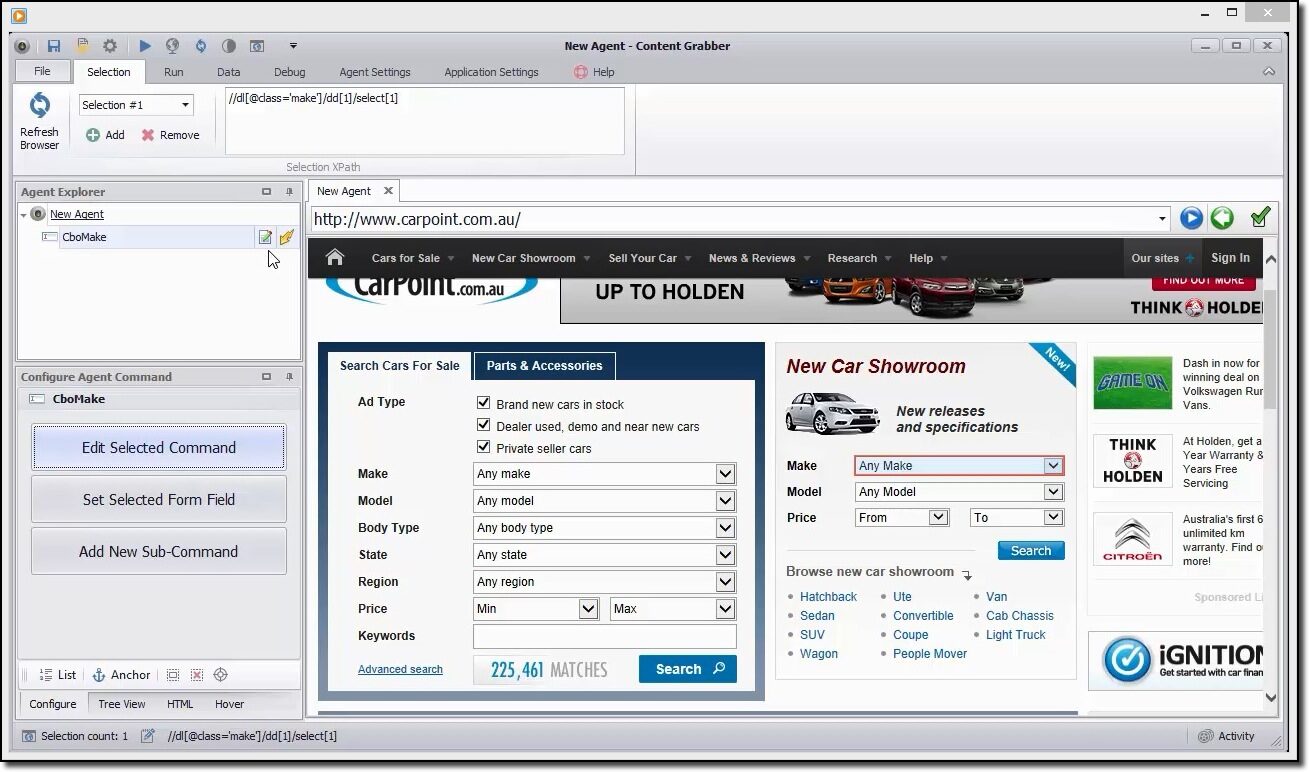
This tool is a collection of commands that are executed in order until they are completed. The order of execution is updated in the Agent Explorer panel. You can use the configuration agent command panel to customize the command based on your particular data requirements.. Users can also add new commands.
ParseHub is a powerful web scraping tool that anyone can use for free. Offers safe and accurate data extraction with the ease of one click. Users can also determine extraction times to maintain the relevance of their remains..
One of its strengths is that it can erase even the most complicated web pages without problems.. User can specify instructions such as search forms, login to websites and click on maps or images for later data collection.
Users can also enter with many links and keywords, where they can extract relevant information in seconds. To end, you can use the REST API to download the extracted data for analysis in CSV or JSON formats. Users can also export the collected information as a Google or Tableau sheet..
Ecommerce scraping web portal example
Once the installation is done, open a new project on ParseHub, use ecommerce url and page will render in app.
- Click on the product name of the first result on the page once the site has loaded. When you select the product, turns green to indicate that it has been chosen.
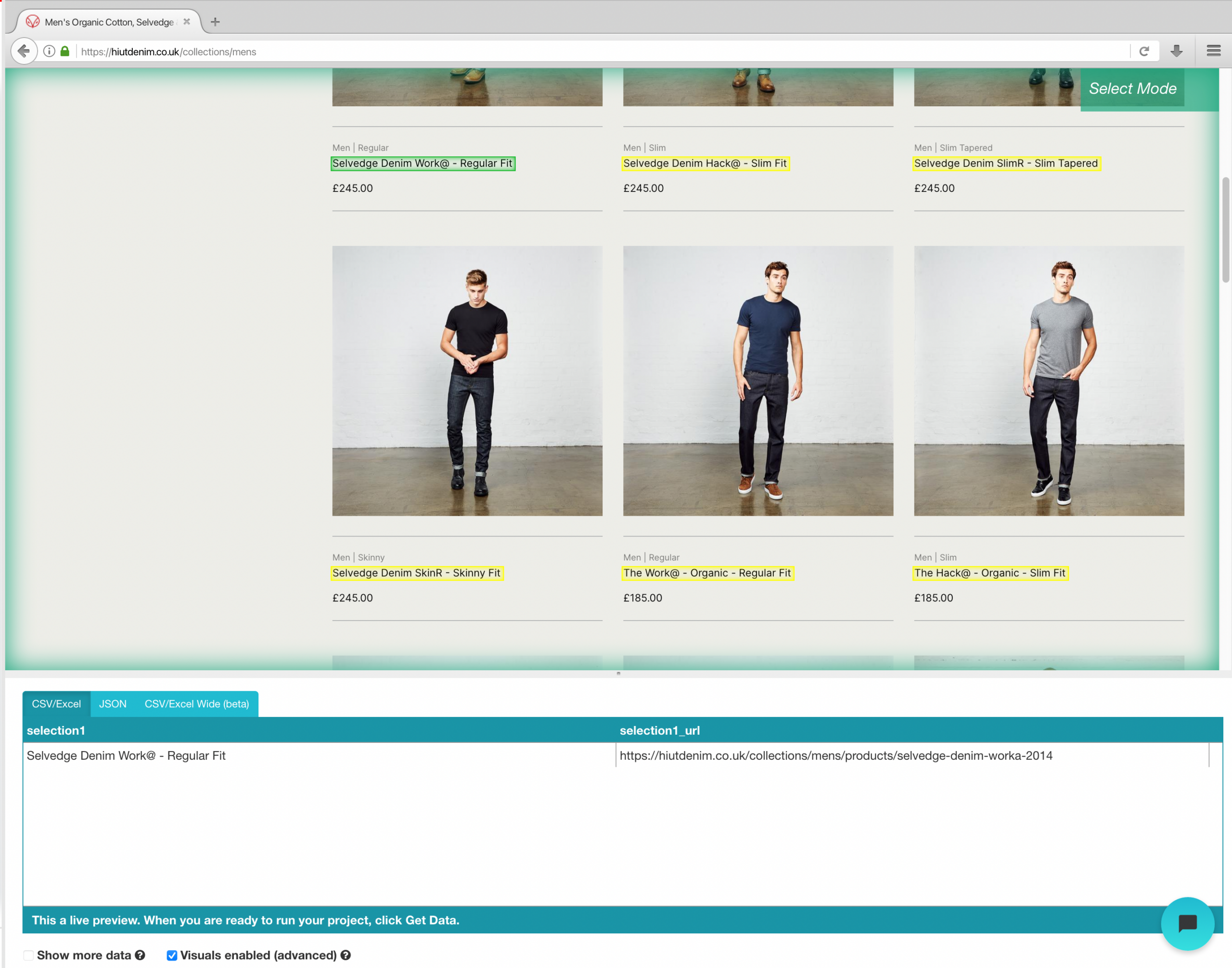
- Yellow will be used to highlight the rest of the product names. Select the second option from the list. Green will now be used to highlight all objects.
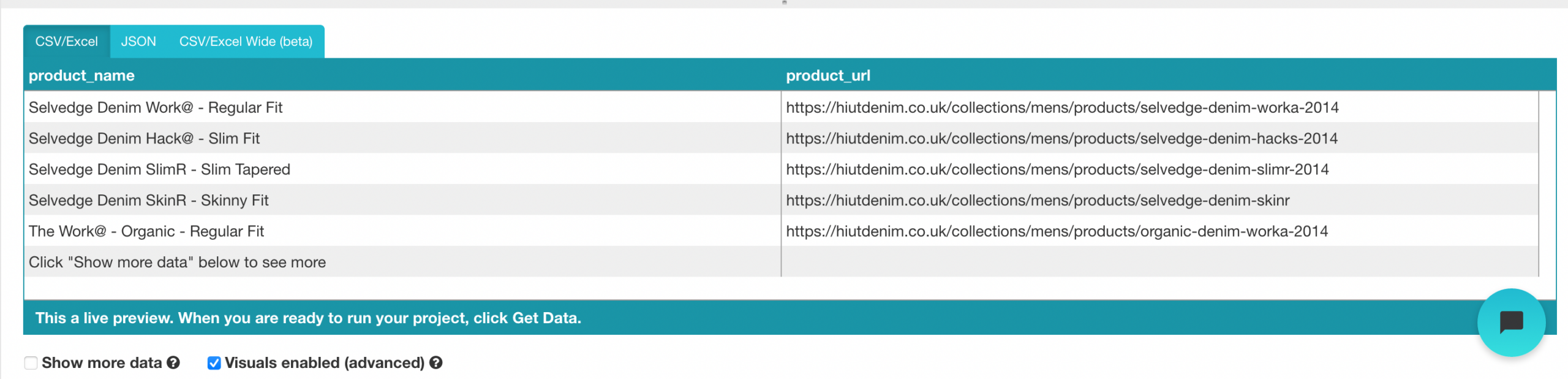
- Change the name of your choice to “product” in the left sidebar. You can now see the product name and url pulled by ParseHub.
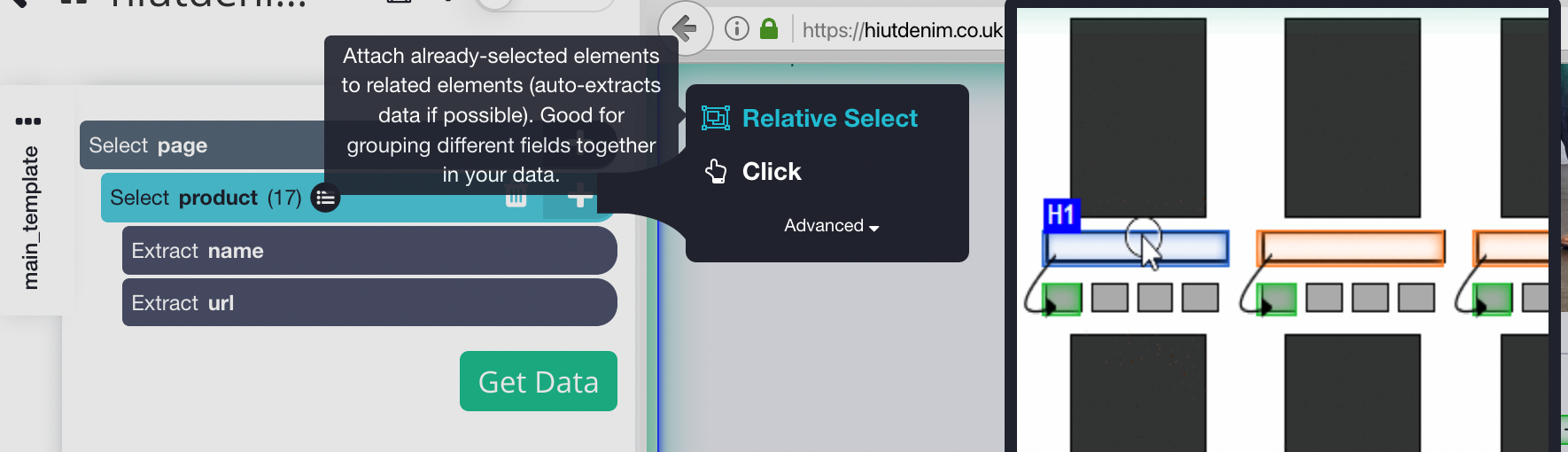
- Click on the PLUS sign (+) next to the product selection in the left sidebar and select the Relative selection command.
- Click on the first product name on the page, followed by the price of the product, using the Relative Selection command. An arrow will appear connecting the two options. This step needs to be repeated several times to train Parsehub in what you want to extract.
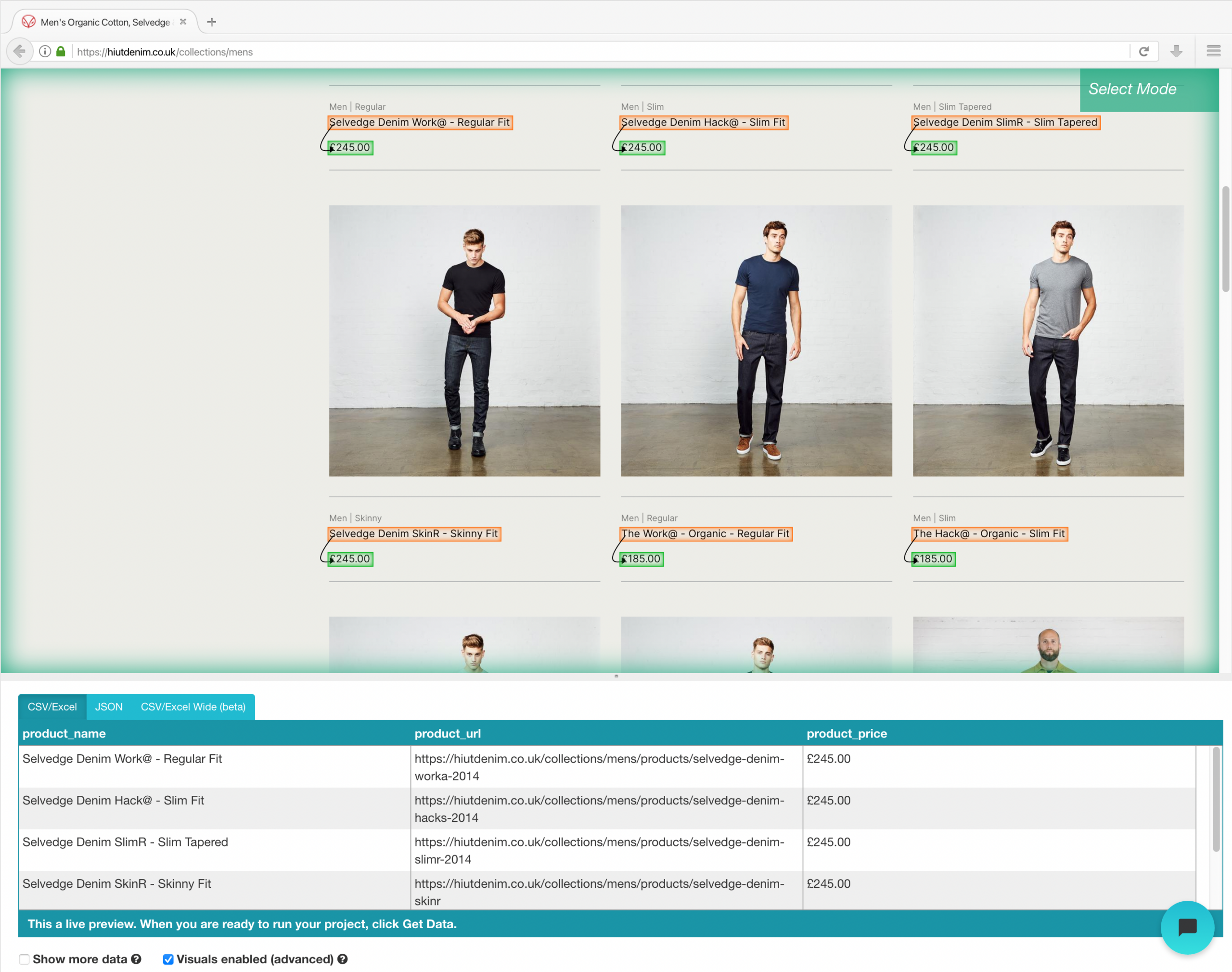
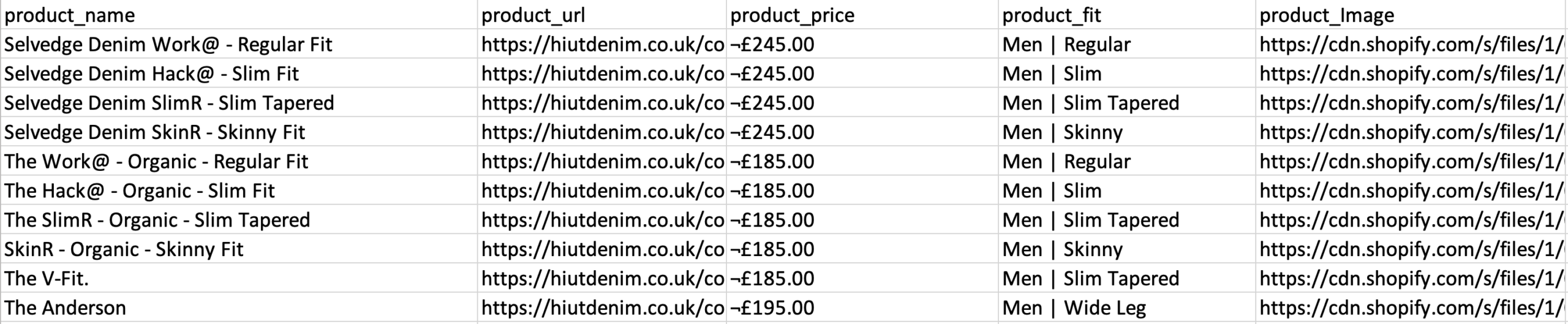
- Repeat the previous step to also extract the Fit Style and Product Image. Make sure to rename your new options appropriately.
Execution and export of your project
Now that we have finished configuring the project, it's time to run our scrape job.
To run your scraping, click the Get Data button on the left sidebar and then the Run button. For larger projects, we suggest running a test run to make sure your data is in the correct format.
It is the last scraping tool on the list. It has a web scraping API that can handle even the most complex Javascript pages and convert them to raw HTML for users to use.. It also offers a specific API to scratch websites through Google search..
We can use this tool in one of three ways:
- Web Scraping general, as an example, extracting customer reviews or stock prices.
- Search engine results page used for keyword tracking or SEO.
- The extraction of contact information or data from social networks includes Growth Hacking.
This tool offers a free plan that includes 1000 credits and paid plans for unlimited use.
Tutorial on using the Scrapingbee API
Sign up for a free plan on the ScrapingBee web portal and you will get 1000 free API requests, which should be enough to learn and test this API.
Now go to the control panel and copy the API key that we will need later in this guide. ScrapingBee now provides multi-language support, allowing you to use the API key directly in your applications.
Since Scaping Bee supports REST APIs, is suitable for any programming language, including CURL, Python, NodeJS, Java, PHP y Go. For more information on scraping, we will use python and request framework, as well as BeautifulSoup. Install them using PIP as follows:
# To install the Python Requests library: pip install requests # Additional modules we needed: pip install BeautifulSoup
Use the following code to start the ScrapingBee web API. We are making a request call with the URL and API key parameters, and the API will respond with the HTML content of the target url.
import requests
def get_data():
response = requests.get(
url address ="https://app.scrapingbee.com/api/v1/",
params={
"api_key": "INSERT-YOUR-API-KEY",
"Url address": "https://example.com/", #website to scrape
},
)
print('HTTP Status Code: ', response.status_code)
print('HTTP Response Body: ', response.content)
get_data()
When adding a beautification code, we can make this output more readable using BeautifulSoup.
Coding
Additionally you can use urllib.parse to encrypt the url you want to scrape, as it's shown in the following:
import urllib.parse
encoded_url = urllib.parse.quote("URL to scrape")
Conclution
Collecting data for your projects is the most tedious and least fun step. This task can take a long time, and if you work in a company or as a freelancer, I knew that time is money, and if there is a more important way to do a task, you better use it. The good news is that web scraping doesn't have to be tedious, since using the correct tool can help you save a lot of time, money and effort. These tools can be beneficial for analysts or people without coding skills.. Before choosing a scraping tool, there are some factors to consider, such as API integration and large-scale scraping extensibility. This post introduced you to some useful tools for different data collection tasks., where you can select the one that facilitates data collection.
I hope this article is useful. Thanks.
The media shown in this post is not the property of DataPeaker and is used at the author's discretion.





