The media shown in this article is not the property of Analytics Vidhya and is used at the author's discretion.
Introduction
We basically train machines to include some kind of automation in them. In machine learning, we use various types of algorithms to allow machines to learn the relationships within the provided data and make predictions with it. Then, the prediction type of the model where we need the predicted output is a continuous numeric value, it's called a regression problem.
Regression analysis revolves around simple algorithms, often used in finance, investments and others, and establishes the relationship between a single dependent variable that depends on several independent variables. For instance, predict the price of a house or an employee's salary, etc., are the most common regression problems.
We will first discuss the types of regression algorithms shortly and then move on to an example. These algorithms can be both linear and non-linear.
Linear ML algorithms

Linear regression
It is a commonly used algorithm and can be imported from the Linear Regression class. Se utiliza una única variableIn statistics and mathematics, a "variable" is a symbol that represents a value that can change or vary. There are different types of variables, and qualitative, that describe non-numerical characteristics, and quantitative, representing numerical quantities. Variables are fundamental in experiments and studies, since they allow the analysis of relationships and patterns between different elements, facilitating the understanding of complex phenomena.... Entry (the significant) to predict one or more output variables, assuming the input variable is not correlated with each other. represent yourself as:
y = b * x + c
where variable dependent on y, independent of x, slope b of the line of best fit that could get accurate output and c – their intersection. Unless there is an exact line that relates the dependent and independent variables, there could be a loss in the output that is normally taken as the square of the difference between the expected and the actual output, namely, the Loss functionThe loss function is a fundamental tool in machine learning that quantifies the discrepancy between model predictions and actual values. Its goal is to guide the training process by minimizing this difference, thus allowing the model to learn more effectively. There are different types of loss functions, such as mean square error and cross-entropy, each one suitable for different tasks and....
When you use more than one independent variable to get results, it is called Multiple linear regression. This type of model assumes that there is a linear relationship between the given characteristic and the output, what is his limitation.
Ridge regression: la norma L2
This is a type of algorithm that is an extension of a linear regression that tries to minimize the loss, also uses multiple regression data. Its coefficients are not estimated by ordinary least squares (MCO), sino por un estimatorThe "Estimator" is a statistical tool used to infer characteristics of a population from a sample. It relies on mathematical methods to provide accurate and reliable estimates. There are different types of estimators, such as the unbiased and the consistent, that are chosen according to the context and objective of the study. Its correct use is essential in scientific research, surveys and data analysis.... llamado cresta, which is biased and has a lower variance than the OLS estimator, so we obtain a contraction in the coefficients. With this type of model, we can also reduce the complexity of the model.
Although the contraction of the coefficient occurs here, are not completely reduced to zero. Therefore, your final model will still include everything.
Loop regression: the L1 standard
It is the absolute minimum selection and shrinkage operator. This penalizes the sum of the absolute values of the coefficients to minimize the prediction error. Makes the regression coefficients for some of the variables drop to zero. It can be built using the LASSO class. One of the advantages of the loop is its simultaneous selection of functions. This helps minimize prediction loss. Secondly, we must bear in mind that lasso cannot make a group selection, also selects features before saturating.
Tanto el lazo como la cresta son métodos de regularizationRegularization is an administrative process that seeks to formalize the situation of people or entities that operate outside the legal framework. This procedure is essential to guarantee rights and duties, as well as to promote social and economic inclusion. In many countries, Regularization is applied in migratory contexts, labor and tax, allowing those who are in irregular situations to access benefits and protect themselves from possible sanctions.....

source: Unsplash
Let's go over some examples:
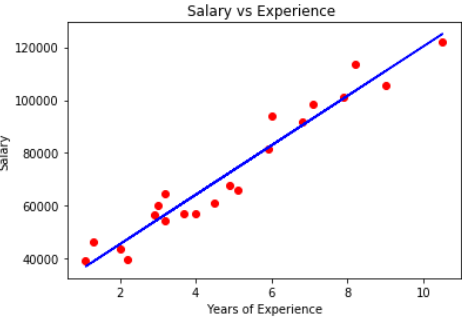
Let's suppose a data with years of experience and salary of different employees. Our goal is to create a model that predicts the employee's salary based on year of experience. Since it contains an independent and a dependent variable, we can use simple linear regression for this problem.
Nonlinear ML algorithms
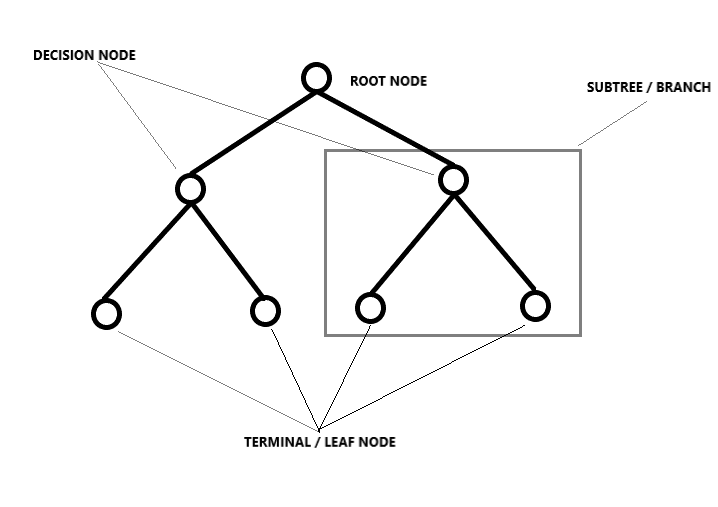
Decision tree regression
Breaks down a data set into smaller and smaller subsets by dividing it, resulting in a tree with decision nodes and leaf nodes. The idea here is to plot a value for any new data point connecting the problem. El tipo de forma en que se lleva a cabo la división está determinada por los parametersThe "parameters" are variables or criteria that are used to define, measure or evaluate a phenomenon or system. In various fields such as statistics, Computer Science and Scientific Research, Parameters are critical to establishing norms and standards that guide data analysis and interpretation. Their proper selection and handling are crucial to obtain accurate and relevant results in any study or project.... y el algoritmo, and the division stops when it reaches the minimum number of information to add. Decision trees often pay off, but even if there is a slight change in the data, the whole structure changes, which means that the models become unstable.
source: unsplash
Let's take a case of house price prediction, given a set of 13 features and around 500 rows, here you need to predict the house price. Since you have a considerable number of samples here, you must opt for trees or other methods to predict values.
Random forest
The idea behind the random forest regression is that, to find the result, use multiple decision trees. The steps involved in it are:
– Choose K random data points from the training set.
– Build a decision tree associated with these data points
– Choose the number of trees we need to build and repeat the above steps (provided as argument)
– For a new data point, have each of the trees predict values of the dependent variable for the given input.
– Assign the mean value of the predicted values to the actual final output.
This is similar to guessing the number of balls in a box.. Suppose we randomly write down the prediction values given by many people and then calculate the average to make a decision about the number of balls in the box.. The random forest is a model that uses multiple decision trees, which we know, but since it has many trees, also requires a lot of time to train and computational power, which is still a drawback.
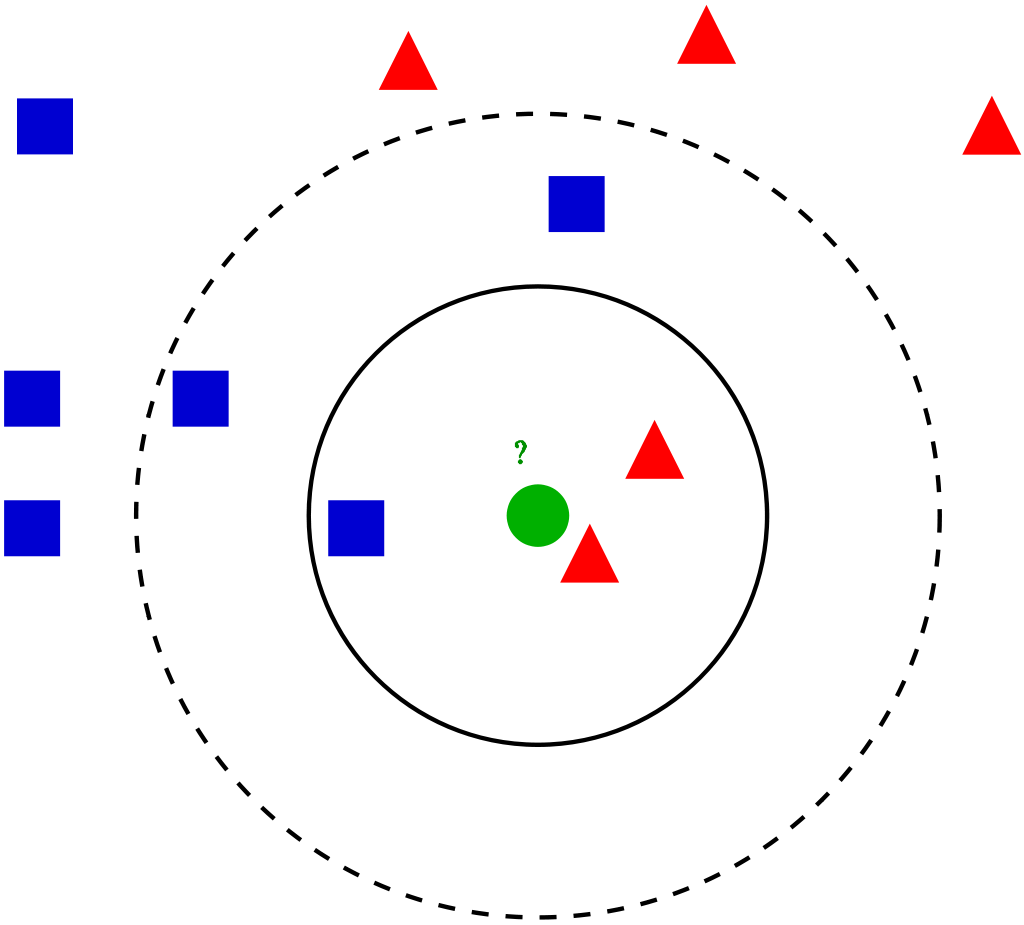
K Nearest neighbors (model KNN)
It can be used from the KNearestNeighbors class. They are simple and easy to implement. For an entry entered in the dataset, los K vecinos más cercanos ayudan a encontrar las k instancias más similares en el conjunto de trainingTraining is a systematic process designed to improve skills, physical knowledge or abilities. It is applied in various areas, like sport, Education and professional development. An effective training program includes goal planning, regular practice and evaluation of progress. Adaptation to individual needs and motivation are key factors in achieving successful and sustainable results in any discipline..... Cualquiera de los valores promedio de la medianThe median is a statistical measure that represents the central value of a set of ordered data. To calculate it, the data is organized from lowest to highest and the number in the middle is identified. If there are an even number of observations, the two core values are averaged. This indicator is especially useful in asymmetric distributions, since it is not affected by extreme values.... de los vecinos se toma como valor para esa entrada.
source: unsplash
The method to find the value can be given as an argument, whose default value is “Minkowski”, a combination of distances “Euclidean” Y “manhattan”.
Predictions can be slow when data is large and of poor quality. Since the prediction must take into account all data points, the model will take up more space during training.
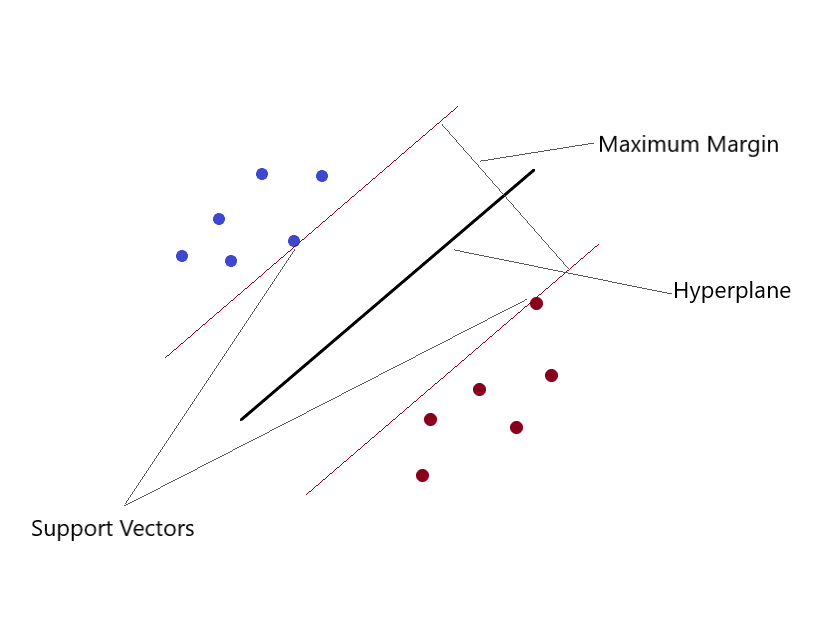
Support Vector Machines (SVM)
Can solve linear and nonlinear regression problems. We create an SVM model using the SVR class. in a multidimensional space, when we have more than one variable to determine the output, then each of the points is no longer a point as in 2D, but they are vectors. The most extreme type of value assignment can be done using this method. You separate classes and give them values. The separation is by the concept of Max-Margin (a hyperplane). What you need to keep in mind is that SVMs are not suitable for predicting values for large training sets.. SVM failure when data is noisier.
source: unsplash
source: unsplash
If the training data is much larger than the number of functions, KNN is better than SVM. SVM outperforms KNN when there are larger functions and less training data.
Good, we have reached the end of this article, we have briefly discussed the types of regression algorithms (theory). Este es Surabi, I have a degree in technology. Take a look at me Linkedin profile and connect. I hope you enjoyed reading this. Thanks.
The media shown in this article is not the property of Analytics Vidhya and is used at the author's discretion.





