This article was published as part of the Data Science Blogathon.
Introduction
Are you working on an image recognition or object detection project but didn't have the basics to build an architecture??
In this article, we will see what convolutional neural network architectures are from the basics and take a basic architecture as a case study to apply our learnings The only prerequisite is that you just need to know how convolution works. worry it's very simple !!
Tomemos una red neuronal convolucionalConvolutional Neural Networks (CNN) are a type of neural network architecture designed especially for data processing with a grid structure, as pictures. They use convolution layers to extract hierarchical features, which makes them especially effective in pattern recognition and classification tasks. Thanks to its ability to learn from large volumes of data, CNNs have revolutionized fields such as computer vision.. simple,
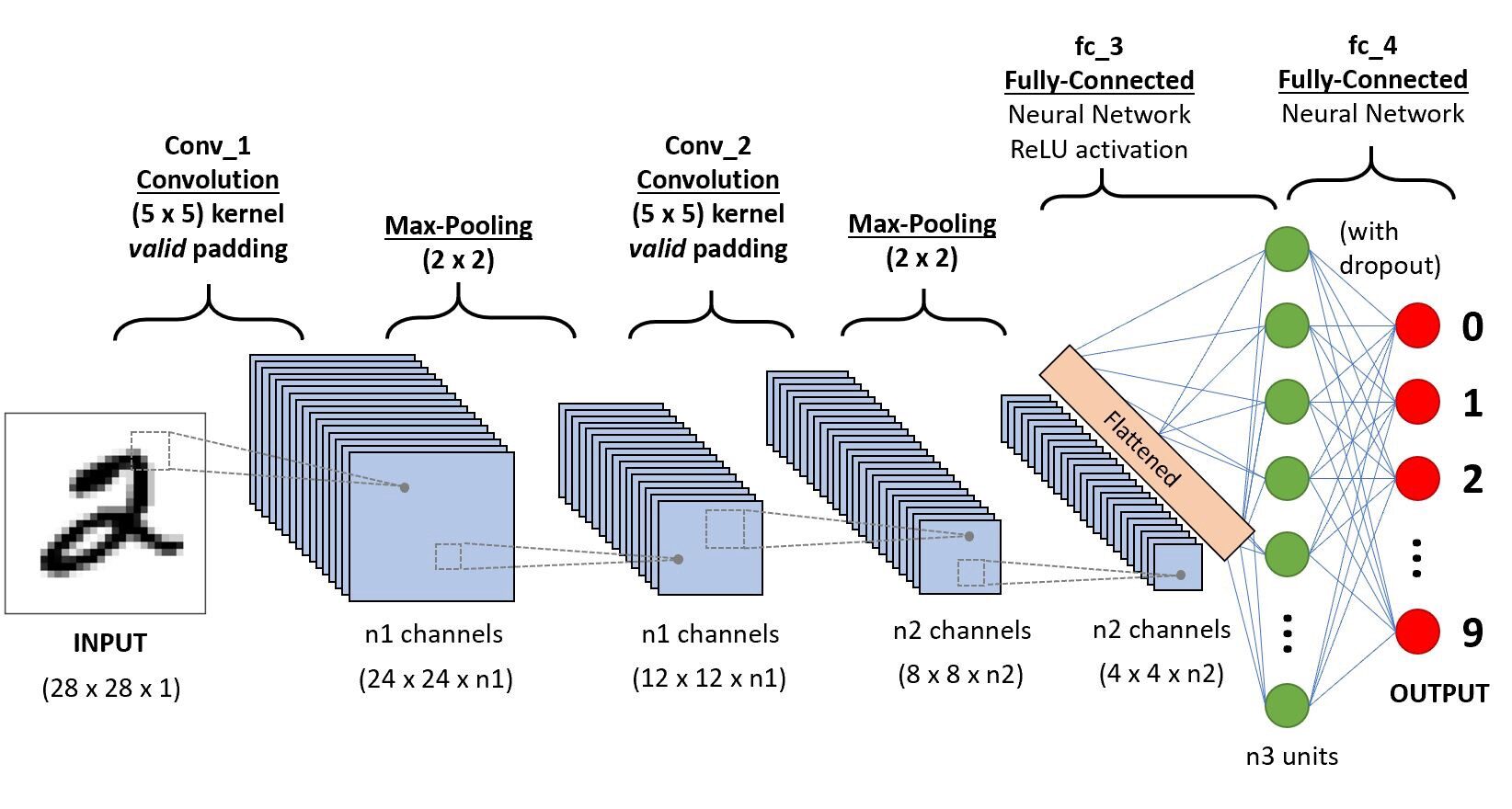
We will go in layers to get detailed information about this CNN.
First, there are some things to learn from the cape 1 What is it strides and padding, we will see each of them shortly with examples
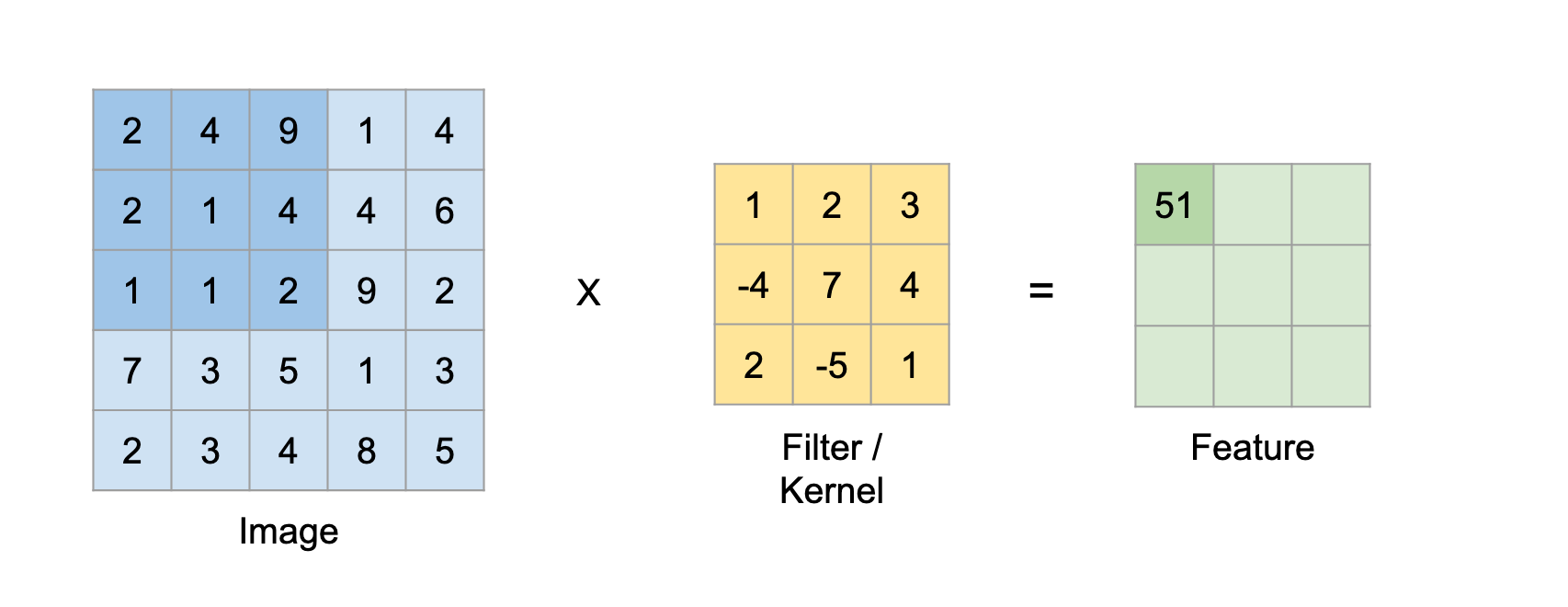
Suppose this in the input matrix of 5 × 5 and a 3X3 matrix filter, for those who don't know what The filter is a set of weights in a matrix that is applied on an image or a matrix to obtain the required characteristics., search by convolution if it is the first time.
Note: We always take the sum or average of all values while doing a convolution.
A filter can be of any depth, if a filter has a depth d, can go to a depth of d layers and convolve, namely, add all (weights x tickets) of d layers
Here the entrance is of size 5 × 5 after applying a kernel or filters 3 × 3, a map of output characteristics of 3 × 3, so let's try to formulate this
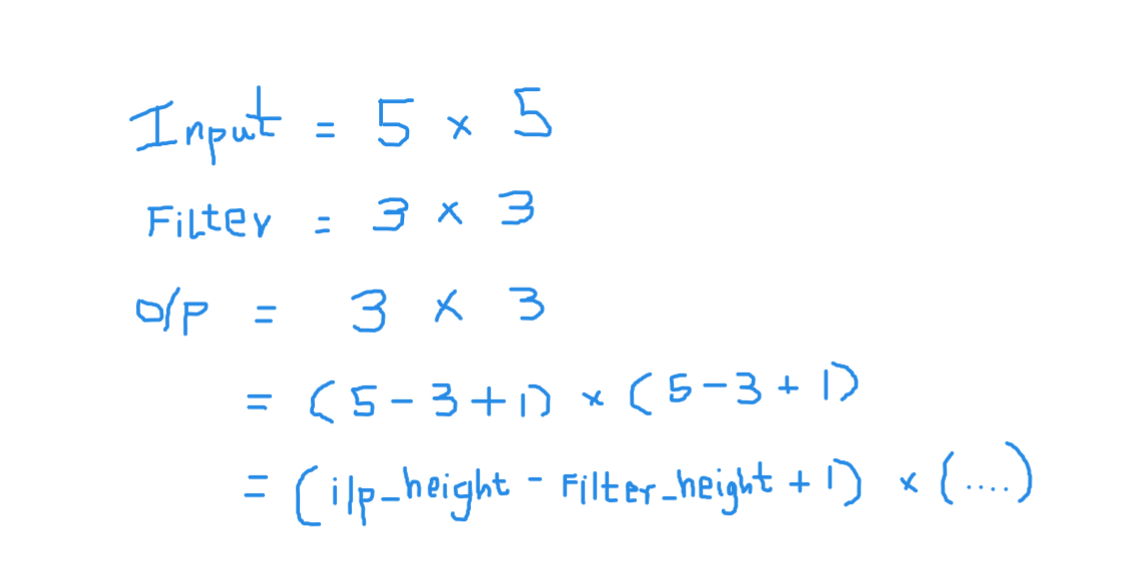
Then, the output height is formulated and the same with the width of or / p also …
Filling
While applying convolutions, we will not obtain the same output dimensions as the input dimensions, we will lose data on the edges, so we add a border of zeros and recalculate the convolution that covers all input values.
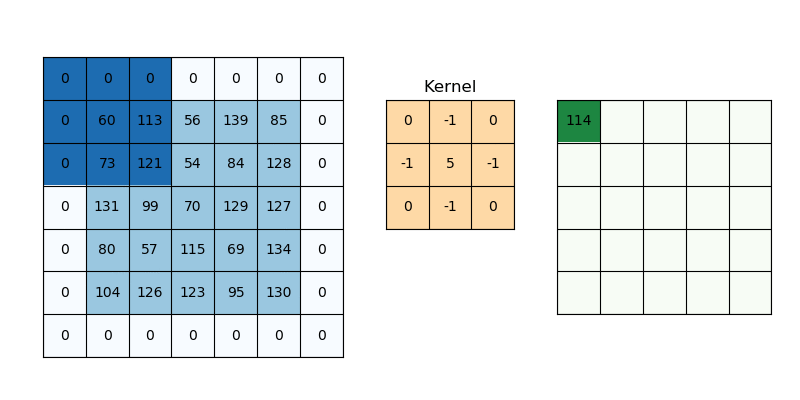
We will try to formulate this,
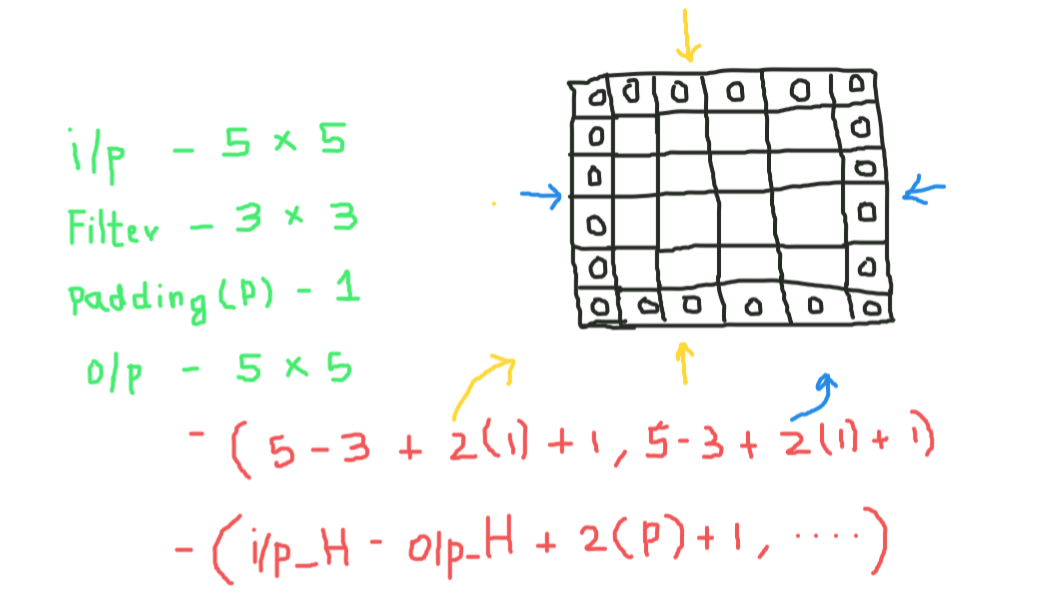
Here 2 is for two columns of zeros along with the height and width, and formulates the same for the width as well
Strides
Sometimes we do not want to capture all the data or information available so we skip some neighboring cells let us visualize it,
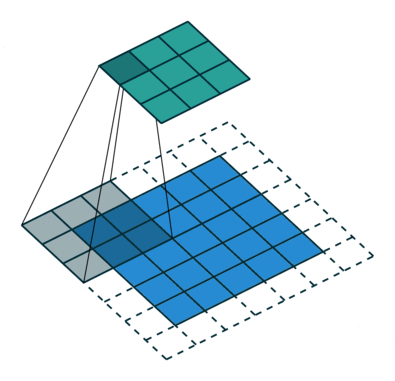
Here the input matrix or image is of dimensions 5 × 5 with a filter 3 × 3 and a stride of 2 so every time we skip two columns and convolve, let's formulate this
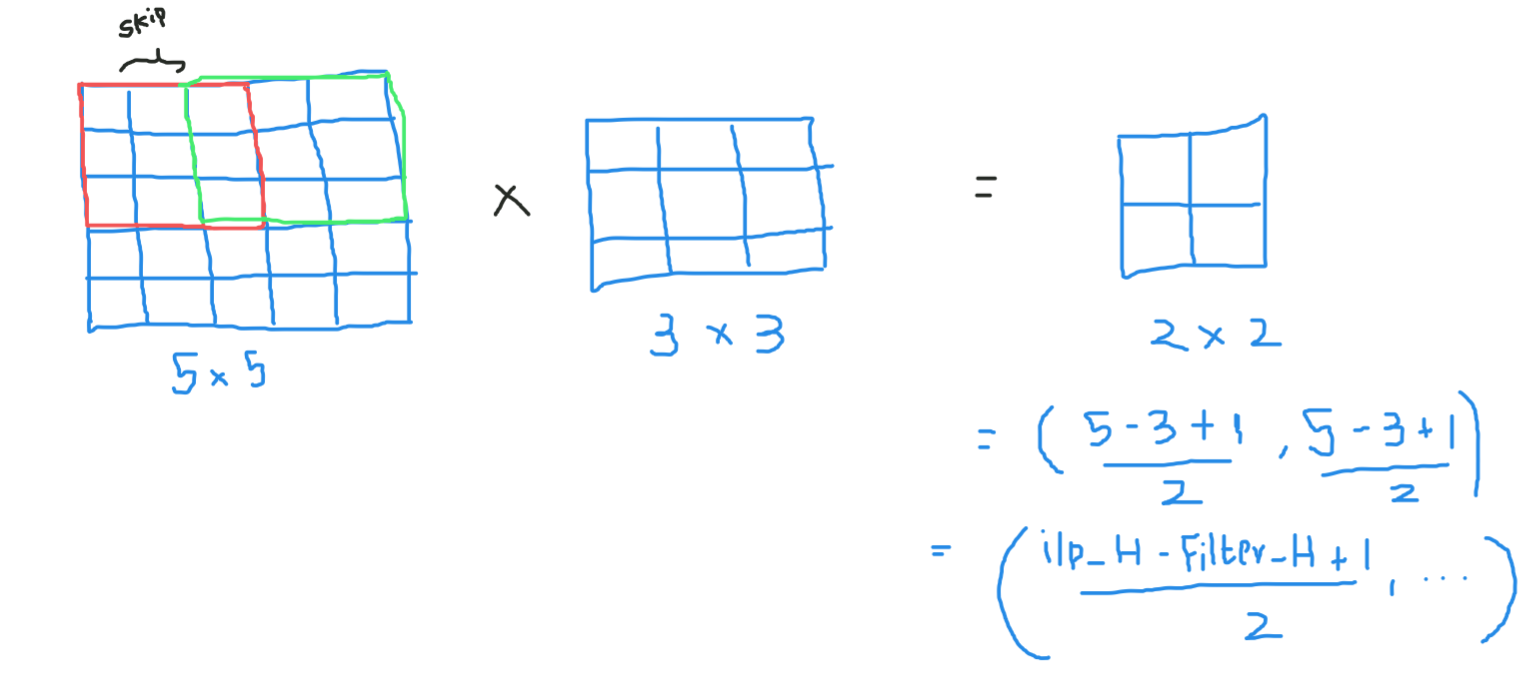
If the dimensions are in float, can take ceil () at the exit, namely (next near integer)
Here H refers to the height, so the output height is formulated and the same with the width of or / p also and here 2 is the stride value so you can make it like S in the formulas.
Grouping
In general terms, grouping refers to a small part, so here we take a small part of the input and try to take the average value called average pool or take a maximum value called maximum pool, so when grouping on an image, we are not getting all the values we are taking a summarized value over all the present values !!!

here, this is an example of maximum grouping, so here, taking a step of two, we are taking the maximum value present in the matrix
Trigger functionThe activation function is a key component in neural networks, since it determines the output of a neuron based on its input. Its main purpose is to introduce nonlinearities into the model, allowing you to learn complex patterns in data. There are various activation functions, like the sigmoid, ReLU and tanh, each with particular characteristics that affect the performance of the model in different applications....
La función de activación es un nodeNodo is a digital platform that facilitates the connection between professionals and companies in search of talent. Through an intuitive system, allows users to create profiles, share experiences and access job opportunities. Its focus on collaboration and networking makes Nodo a valuable tool for those who want to expand their professional network and find projects that align with their skills and goals.... que se coloca al final o entre las redes neuronales. They help decide whether the neuron will fire or not.. Tenemos diferentes tipos de funciones de activación como en la figure"Figure" is a term that is used in various contexts, From art to anatomy. In the artistic field, refers to the representation of human or animal forms in sculptures and paintings. In anatomy, designates the shape and structure of the body. What's more, in mathematics, "figure" it is related to geometric shapes. Its versatility makes it a fundamental concept in multiple disciplines.... anterior, but for this post, my focus will be on Rectified linear unit (resumeThe ReLU activation function (Rectified Linear Unit) It is widely used in neural networks due to its simplicity and effectiveness. Defined as ( f(x) = max(0, x) ), ReLU allows neurons to fire only when the input is positive, which helps mitigate the problem of gradient fading. Its use has been shown to improve performance in various deep learning tasks, making ReLU an option...)
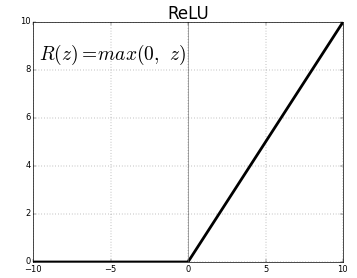
Don't drop your jaw, this is not so complex this function simply returns 0 if its value is negative, on the contrary, returns the same value you gave, nothing more than eliminates negative outputs and maintains values between 0 Y + Infinity
Now that we have learned all the necessary basics, estudiemos una red neuronalNeural networks are computational models inspired by the functioning of the human brain. They use structures known as artificial neurons to process and learn from data. These networks are fundamental in the field of artificial intelligence, enabling significant advancements in tasks such as image recognition, Natural Language Processing and Time Series Prediction, among others. Their ability to learn complex patterns makes them powerful tools.. básica llamada LeNet.
LeNet-5
Before we begin we will see what are the architectures designed to date. These models were tested on ImageNet data where we have over a million images and 1000 classes to predict
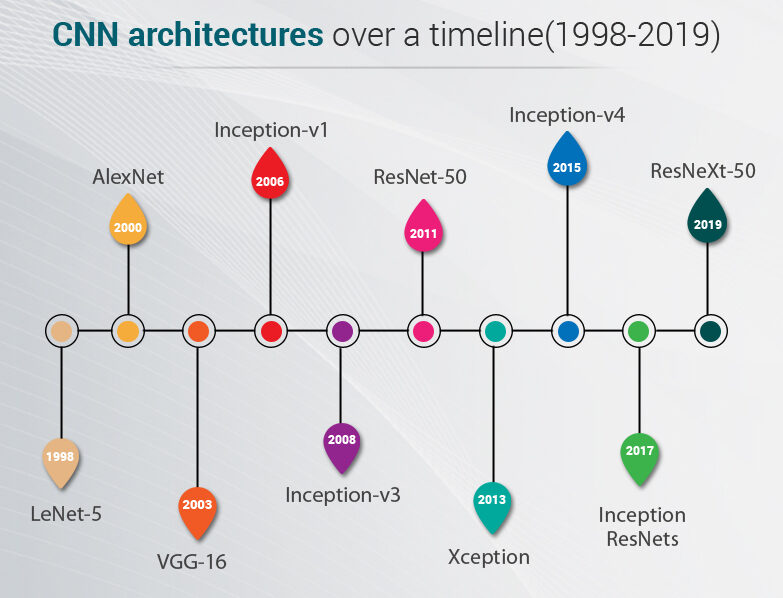
LeNet-5 is a very basic architecture so anyone can start with advanced architectures
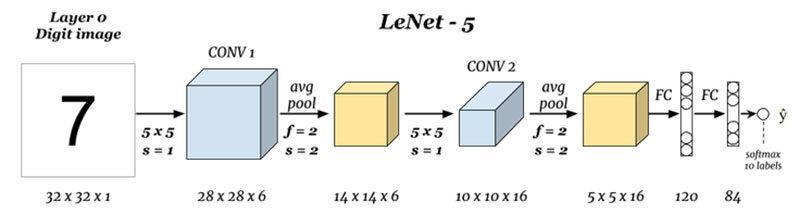
What are the inputs and outputs (Front cover 0 and Layer N):
Here we are predicting digits based on the given input image, note that here the image has the dimensions of height = 32 pixels, width = 32 pixels and a depth of 1, so we can assume it is a grayscale or black and white image, Taking into account that the output is a softmax of the 10 values, here softmax gives probabilities or reasons for all 10 digits, we can take the number as the output with the highest probability or reason.
Convolución 1 (Front cover 1):
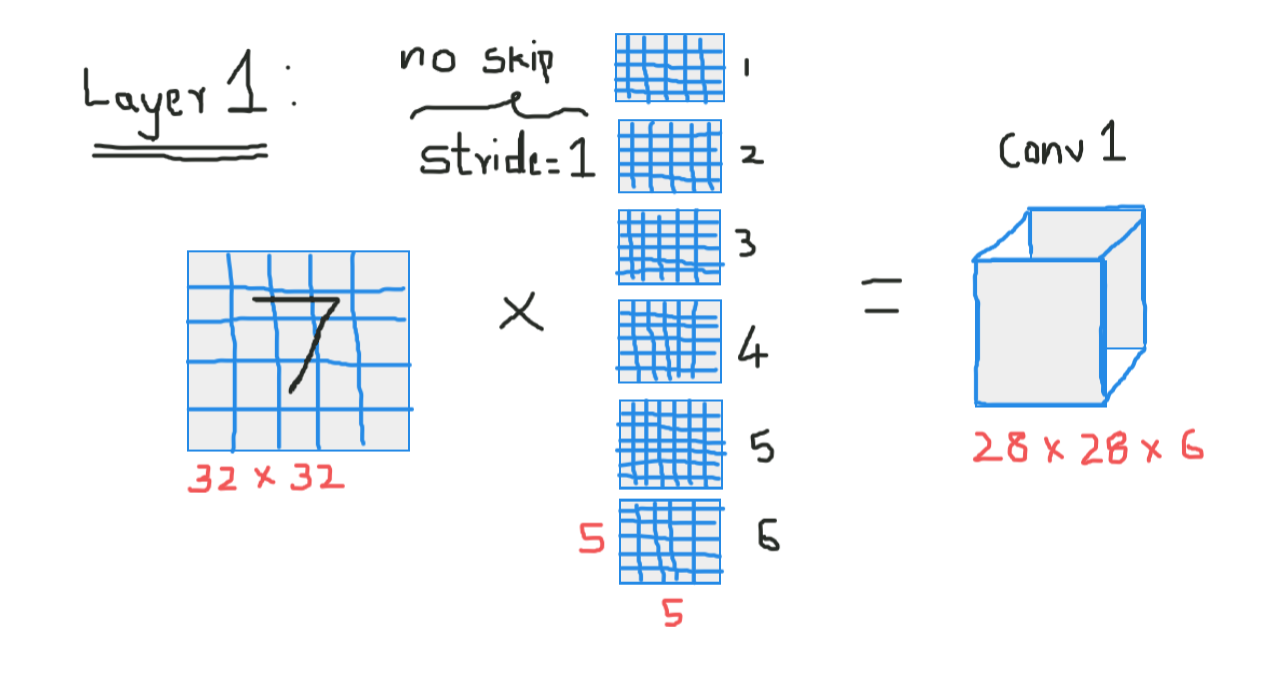
Here we are taking input and convolving with size filters 5 x 5, thus producing an output of size 28 x 28 Check the above formula to calculate the output dimensions, what here is that we have taken 6 filters of this type and, Thus, the depth of conv1 is 6, Thus, its dimensions were 28 x 28 x 6 now pass this to grouping layer
Grouping 1 (Front cover 2):
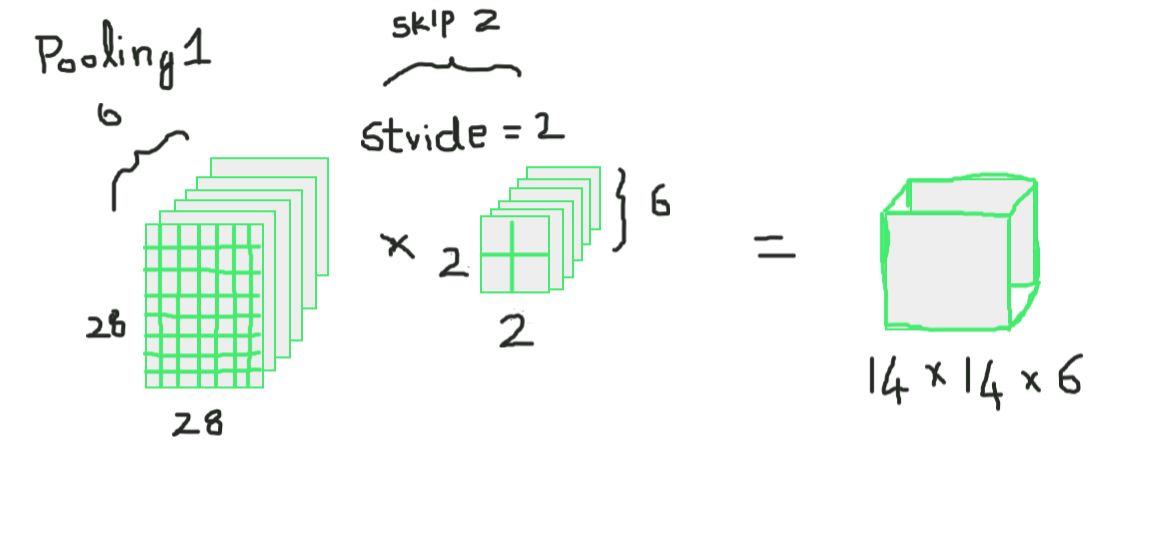
Here we are taking 28 x 28 x 6 as input and applying the average combination of a matrix of 2 × 2 and a step from 2, namely, placing an array of 2 x 2 at the input and taking the average of all those four pixels and jumping with a jump of 2 columns every time, what gives 14 x 14 x 6 as a way out, we are calculating the grouping for each layer, so here the output depth is 6
Convolución 2 (Front cover 3):
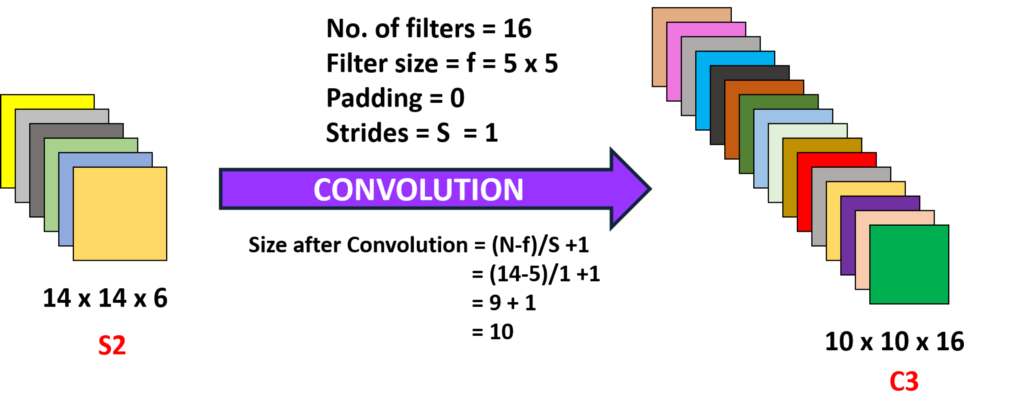
Here we are taking the 14 x 14 x 6, namely, the o / py convolving with a size filter 5 x5, with a stride of 1, namely (no jumps), and with zero fillings, so we get an output of 10 x 10, now here we take 16 filters of this type of depth 6 and we convolve thus obtaining an output of 10 x 10 x 16
Grouping 2 (Front cover 4):

Here we are taking the output from the previous layer and performing an average grouping with a step of 2, namely (skip two columns) and with a size filter 2 x 2, here we superimpose this filter on the layers of 10 x 10 x 16 so for each 10 x 10 we get outputs from 5 x 5, Thus, getting 5 x 5 x 16
Front cover (N-2) and Cape (N-1):
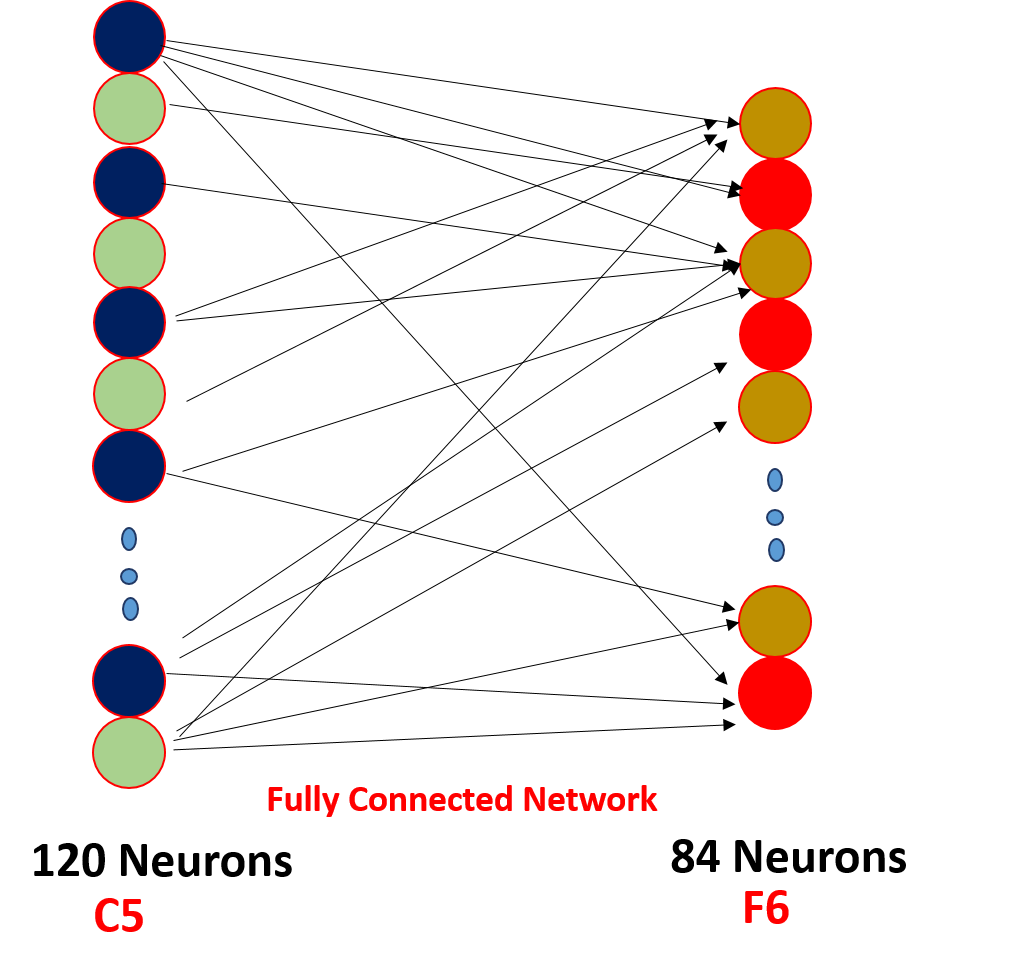
Finally, we flatten all the values of 5 x 5 x 16 to a single layer in size 400 and we input them into a forward feeding neural network of 120 neurons that have a weight matrix of size. [400,120] and a hidden layer of 84 neurons connected by 120 neurons with a weight matrix of [120,84] and you are 84 neurons are in fact connected to 10 output neurons
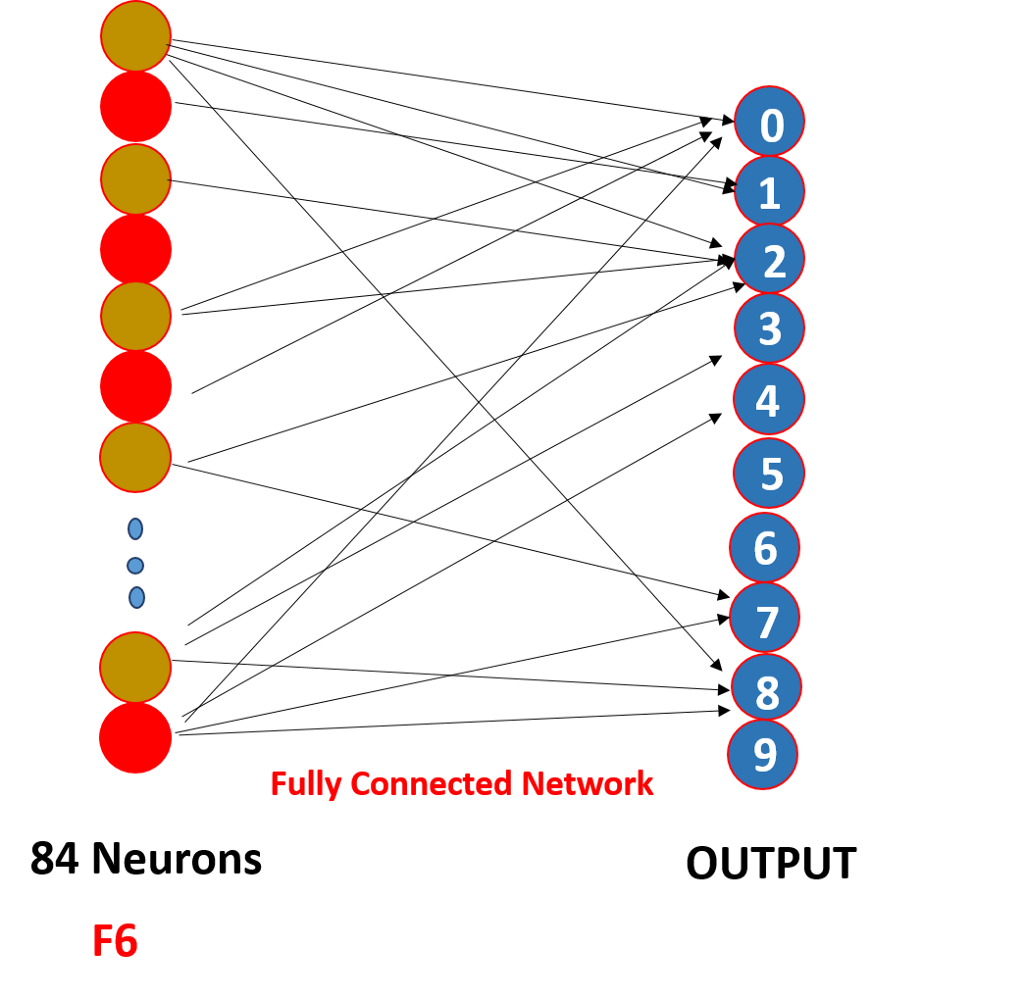
These neurons o / p finalize the number predicted by softmaxing.
How does a convolutional neural network really work??
Works through weight sharing and poor connectivity,
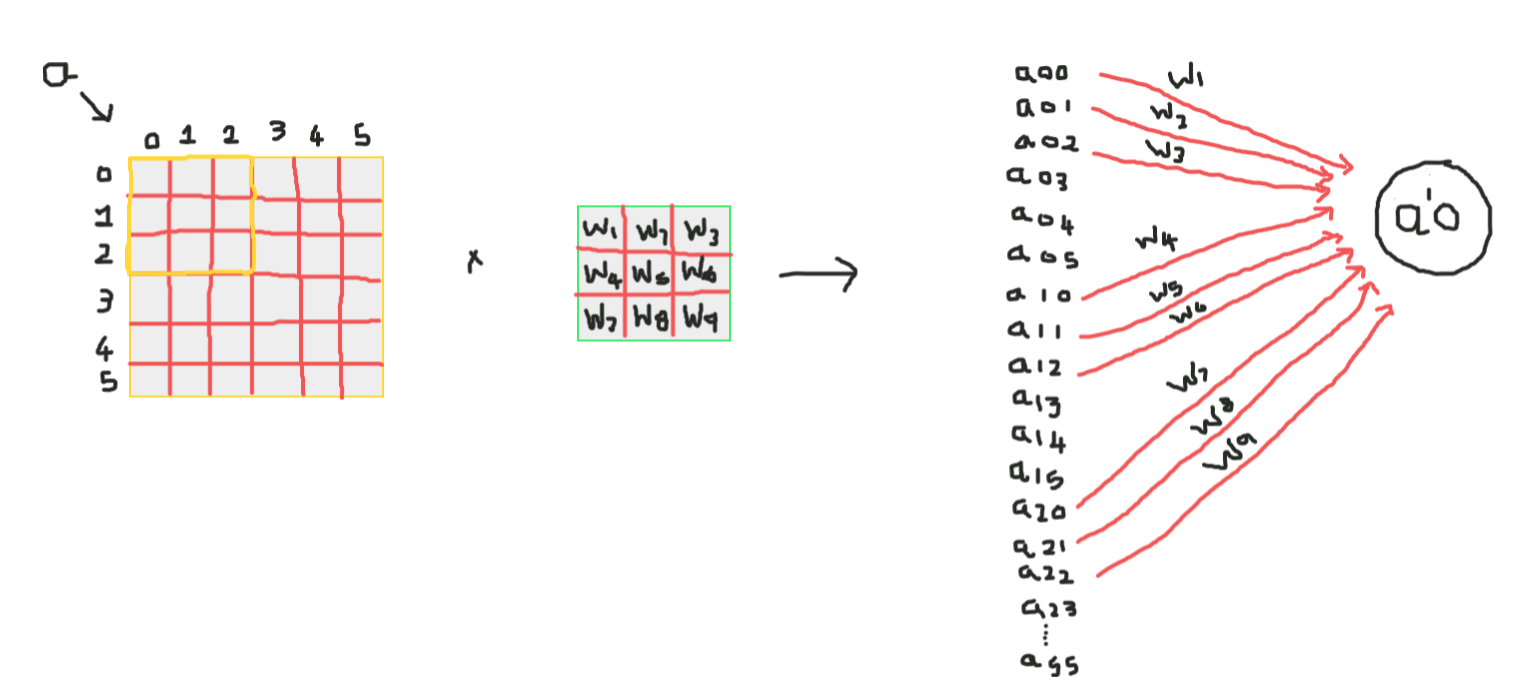
So here, as you can see the convolution has some weights these weights are shared by all input neurons, not each entry has a separate weight called a shared weight, Y not all input neurons are connected to the output neuron and only some that are convoluted are activated, what is known as poor connectivity, CNN is no different from feedforward neural networks, These two properties make them special!
Points to look at
1. After each convolution, the output is sent to a trigger function for better characteristics and to maintain positivity, for instance: resume
2. Poor connectivity and shared weight are the main reason for a convolutional neural network to work.
3. The concept of choosing a series of filters between the layers and the padding and the dimensions of the stride and the filter is taken by conducting a series of experiments, do not worry about it, focus on building the foundation, one day you will do those experiments and build a more productive !!!





