This article was published as part of the Data Science Blogathon
w
- This article will give you a basic understanding of how text analysis works..
- Learn about the different steps of the NLP process
- Derivation of the general sentiment of the text.
- Dashboard showing general statistics and sentiment analysis of the text.
Abstract
In this modern digital age, a large amount of information is generated per second. Most of the data that humans generate through messages, tweets, blogs, news articles, Product recommendations and WhatsApp reviews are unstructured. Then, to get useful insights from this highly unstructured data, we must first convert them into structured and normalized form.
Natural language processing (PNL) is a class of artificial intelligence that performs a series of processes on this unstructured data to obtain meaningful information. Language processing is completely non-deterministic in nature because the same language can have different interpretations. It becomes tedious because something suitable for one person is not suitable for another. What's more, the use of colloquial language, acronyms, hashtags with words attached, emoticons has an overhead for preprocessing.
If you are interested in the power of social media analytics, this article is the starting point for you. This article covers the basics of text analysis and provides you with a step-by-step tutorial to perform natural language processing without the requirement of any training dataset..
Introduction to NLP
Natural language processing is the subfield of artificial intelligence that comprises systematic processes to convert unstructured data into meaningful information and extract useful insights from it.. NLP is further classified into two broad categories: Rules-based NLP and Statistical NLP. Rule-based NLP uses basic reasoning to process tasks, so manual effort is required without much training of the dataset. Statistical NLP, Secondly, train a large amount of data and obtain information from it. Use machine learning algorithms to train yourself. In this article, we will learn rules-based NLP.
NLP Applications:
- Text summary
- Translator machine
- Question and answer systems
- Spelling checks
- Autocomplete
- Sentiment analysis
- Speech recognition
- Topic Segmentation
NLP channeling:

The NLP pipeline is divided into five subtasks:
1. Lexical analysis: Lexical analysis is the process of analyzing the structure of words and phrases present in the text. The lexicon is defined as the smallest identifiable fragment of text. Could be a word, phrase, etc. It involves identifying and dividing the entire text into sentences, paragraphs and words.
2. Syntactic analysis: Syntactic analysis is the process of ordering words in a way that shows the relationship between words. It involves analyzing them for grammatical patterns. For instance, the sentence “College goes to the girl”. is rejected by the parser.
3. Semantic analysis: Semantic analysis is the process of analyzing text to determine its meaning. Consider syntactic structures to map objects in the task domain. For instance, the phrase “Wants to eat hot ice cream” is rejected by the semantic analyzer.
4. Disclosure integration: Disclosure integration is the process of studying the context of the text. Sentences are arranged in a meaningful order to form a paragraph, which means that the sentence before a particular sentence is necessary to understand the general meaning. What's more, the sentence that follows the sentence depends on the previous one.
5. Pragmatic analysis: Pragmatic analysis is defined as the process of reconfirming that what the text really meant is the same as the derivative.
Reading the text file:
filename = "C:UsersDellDesktopexample.txt" text = open(filename, "r").read()
Print the text:
print(text)

Library installation for NLP:
We will use the spaCy library for this tutorial. space is an open source software library for advanced NLP written in the Python and Cython programming languages. The library is published under a license from MIT. Unlike NLTK, que se usa ampliamente para la enseñanza y la investigación, spaCy se enfoca en proporcionar software para uso en producción. spaCy también admite flujos de trabajo de aprendizaje profundo que permiten conectar modelos estadísticos entrenados por bibliotecas de aprendizaje automático populares como TensorFlow, Pytorch a través de su propia biblioteca de aprendizaje automático Thinc.[Wikipedia]
pip install -U pip setuptools wheel
pip install -U spacy
Ya que estamos tratando con el idioma inglés. Entonces necesitamos instalar el en_core_web_sm paquete para ello.
python -m spacy download en_core_web_sm
Verificando que la descarga fue exitosa e importando el paquete spacy:
import spacy
nlp = spacy.load('en_core_web_sm')
Después de la creación exitosa del objeto NLP, podemos pasar al preprocesamiento.
Tokenización:
Tokenization is the process of converting all text into a series of words known as tokens.. This is the first step in any NLP process. Divide all the text into meaningful units.
text_doc = nlp(text) print ([token.text for token in text_doc])

As we can see in the tokens, there are a lot of blanks, commas, Empty words that are of no use from an analytical perspective.
Sentence identification
Identifying sentences from the text is useful when we want to configure significant parts of the text that occur together. That is why it is useful to find phrases.
about_doc = nlp(about_text) sentences = list(about_doc.sents)

Noise word removal
Stopwords are defined as words that appear frequently in the language. They have no significant role in text analysis and hamper the analysis of frequency distribution. For instance, the, a, a, O, etc. Therefore, should be removed from the text to get a clearer image of the text.
normalized_text = [token for token in text_doc if not token.is_stop] print (normalized_text)

Punctuation removal:
As we can see in the previous result, there are punctuation marks that do not serve us. So let's remove them.
clean_text = [token for token in normalized_text if not token.is_punct] print (clean_text)

Lematización:
Stemming is the process of reducing a word to its original form. Lemma is a word that represents a group of words called lexemes. For instance: to participate, to participate, to participate. They all come down to a common motto, namely, to participate.
for token in clean_text: print (token, token.lemma_)
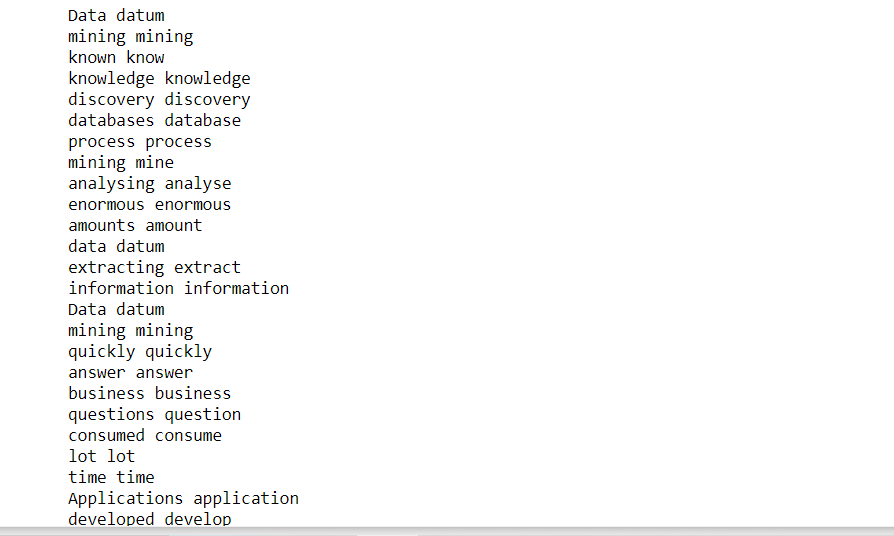
Recuento de frecuencia de palabras:
Realicemos ahora un análisis estadístico del texto. Encontraremos las diez primeras palabras según su frecuencia en el texto.
from collections import Counter words = [token.text for token in clean_text if not token.is_stop and not token.is_punct] word_freq = Counter(words) # 10 commonly occurring words with their frequencies common_words = word_freq.most_common(10) print (common_words)

Sentiment analysis
El análisis de sentimiento es el proceso de analizar el sentimiento del texto. Una forma de hacerlo es a través de la polaridad de las palabras, ya sean positivas o negativas.
VADER (Valence Aware Dictionary and Sentiment Reasoner) es una biblioteca de análisis de sentimientos basada en reglas y léxico en Python. Utiliza una serie de léxicos de sentimientos. A sentiment lexicon is a series of words that are assigned to their respective polarities, namely, positive, negative and neutral according to its semantic meaning.
For instance:
1. Words like good, great, amazing, fantastic are positive polarity.
2. Words like bad, worse, pathetic are negative polarity.
The VADER sentiment analyzer finds the percentages of words of different polarity and gives polarity scores for each of them respectively. The output of the analyzer is scored from 0 a 1, which can be converted to percentages. It doesn't just talk about positivity or negativity scores, but also of how positive or negative a feeling is.
Let's first download the package using pip.
pip install VaderSentiment
Later, analyze sentiment scores.
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
vs = analyzer.polarity_scores(text)
vs

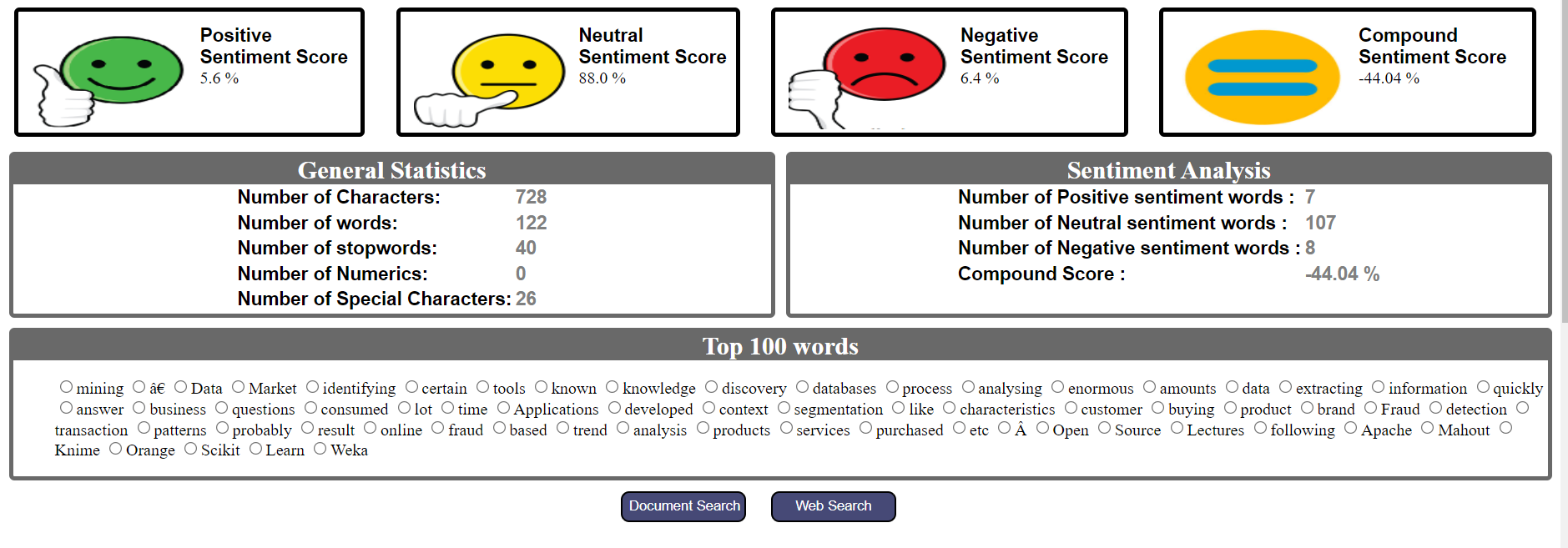
Panel de control del analizador de texto
Los pasos anteriores se pueden resumir para crear un tablero para el analizador de texto. Incluye la cantidad de palabras, la cantidad de caracteres, la cantidad de números, las N palabras principales, la intención del texto, la opinión general, la puntuación de la opinión positiva, la puntuación de la opinión negativa, la puntuación de la opinión neutral y el recuento de palabras de la opinión.
Conclution
La PNL ha tenido un gran impacto en campos como el análisis de reseñas de productos, recommendations, social media analysis, traducción de texto y, Thus, ha obtenido enormes beneficios para las grandes empresas.
I hope this article helps you start your journey in the field of NLP..
And finally, … No need to say,
Thank you for reading!
The media shown in this article is not the property of DataPeaker and is used at the author's discretion.





