In this article, We will learn how we can handle multiple category variables using the One Hot Encoding function engineering technique.
But before continuing, let's have a short discussion on function engineering and One Hot Encoding.
Function engineering
Then, Feature engineering is the process of extracting features from raw data using domain knowledge of the problem. These functions can be used to improve the performance of machine learning algorithms and, if performance increases, will provide the best accuracy. We can also say that function engineering is the same as applied machine learning. Feature engineering is the most important art in machine learning that creates a huge difference between a good model and a bad model. This is the third step in the life cycle of any data science project.
The concept of transparency for machine learning models is somewhat complicated, as different models often require different approaches for different types of data. Such as:-
- Continuous data
- Categorical characteristics
- Missing values
- NormalizationStandardization is a fundamental process in various disciplines, which seeks to establish uniform standards and criteria to improve quality and efficiency. In contexts such as engineering, Education and administration, Standardization makes comparison easier, interoperability and mutual understanding. When implementing standards, cohesion is promoted and resources are optimised, which contributes to sustainable development and the continuous improvement of processes....
- Dates and time
But here we will only discuss the categorical features, categorical characteristics are those characteristics in which the data type is an object type. The data point value in any categorical characteristic is not in numerical form, but in the form of an object.
There are many techniques for handling categorical variables, some are:
- Tag encoding or ordinal encoding
- A hot coding
- Dummy coding
- Effects encoding
- Binary encoding
- Basel coding
- Hash encoding
- Destination encoding
Then, here we handle categorical characteristics by One Hot Encoding, Thus, first, discutiremos One Hot Encoding.
A hot coding
We know that categorical variables contain the label values instead of numeric values. The number of possible values is often limited to a fixed set. Categorical variables are often called nominal. Many machine learning algorithms cannot operate directly on tag data. Require all input and output variables to be numeric.
This means that categorical data must be converted to a numeric form. If the variableIn statistics and mathematics, a "variable" is a symbol that represents a value that can change or vary. There are different types of variables, and qualitative, that describe non-numerical characteristics, and quantitative, representing numerical quantities. Variables are fundamental in experiments and studies, since they allow the analysis of relationships and patterns between different elements, facilitating the understanding of complex phenomena.... categorical is an output variable, you may also want to convert model predictions back to categorical form to present or use in some application.
for instance data on gender are in the form of 'masculine’ Y 'woman'.
But if we use one-hot encoding, coding and allowing the model to assume a natural order between categories can result in poor performance or unexpected results.
One-hot encoding can be applied to the representation of integers. This is where the integer encoded variable is removed and a new binary variable is added for each unique integer value.
For instance, we code the variable of colors,
| Red color | Color blue |
| 0 | 1 |
| 1 | 0 |
| 0 | 1 |
Now we will begin our journey. In the first step, we take a set of house price prediction data.
Data set
Here we will use the data set of house_price which is used to predict the price of the house according to the size of the area.
If you want to download the house price prediction dataset, click on here.
Module import
Now, we have to import important python modules to be used for one-hot encoding
# importing pandas import pandas as pd # importing numpy import numpy as np # importing OneHotEncoder from sklearn.preprocessing import OneHotEncoder()
Here, we use pandas that are used for data analysis, NumPyused for n-dimensional arrays, and from sklearn, we will use a class One hot encoder important for categorical encoding.
Now we have to read this data using Python.
Read data set
Generally, the dataset is in CSV form, and the dataset we use is also in CSV form. To read the CSV file we will use the pandas read_csv function (). look down:
# reading dataset
df = pd.read_csv('house_price.csv')
df.head()
production:-

But we only have to use categorical variables for an active encoder and we will only try to explain with categorical variables for easy understanding.
to partition categorical variables from data, we have to check how many characteristics have categorical values.
Checking categorical values
To verify the values we use the pandas select_dtypes function that is used to select the data types of the variable.
# checking features cat = df.select_dtypes(include="O").keys() # display variabels cat
production:-

Now we have to remove those numeric columns from the dataset and we will use this categorical variable for our use. We only use 3-4 categorical columns of the dataset to apply one-hot encoding.
Create a new data frame
Now, to use categorical variables, we will create a new data frame from selected categorical columns.
# creating new df
# setting columns we use
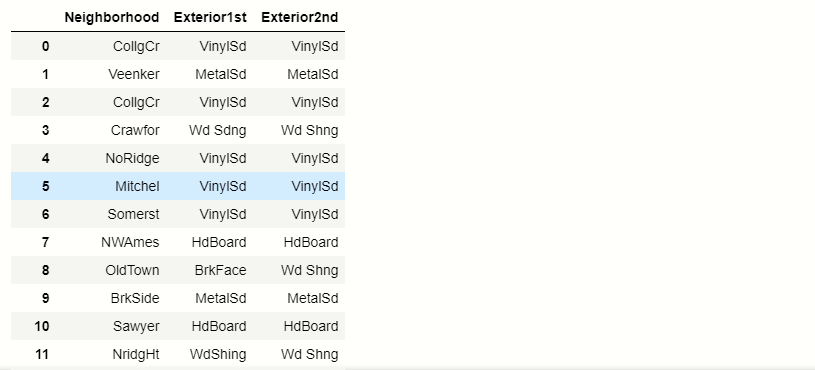
new_df = pd.read_csv('house_price.csv',usecols =['Neighborhood','Exterior1st ','Exterior2nd'])
new_df.head()
production:-
Now we have to find out how many unique categories are present in each categorical column.
Find unique values
To find unique values we will use the pandas unique function ().
# unique values in each columns
for x in new_df.columns:
#prinfting unique values
print(x ,':', len(new_df[x].unique()))
production:-
| Neighborhood: 25 |
| Exterior 1st: 15 |
| Exterior 2nd: 16 |
Now, we will use our technique to apply one-hot encoding on multi-category variables.
Technique for multi-category variables
The technique is to limit the one-hot encoding to 10 variable's most frequent labels. This means that we would make a binary variable only for each of the 10 most frequent tags, this is equivalent to grouping all other tags into a new category, which in this case will be eliminated. A) Yes, the 10 new dummy variables indicate whether one of the 10 most frequent tags is present is 1 or not then 0 for a particular observation.
Most frequent variables
Here we will select the 20 most frequent variables.
Suppose we take a categorical variable Neighborhood.
# finding the top 20 categories new_df.Neighborhood.value_counts().sort_values(ascending=False).head(20)
production:

When you see in this output image, you will notice that the Names The label repeats 225 times in the neighborhood columns and we go down this number is decreasing.
So we take the 10 top results from the top and we convert this top result 10 in one-hot encoding and the labels on the left become zero.
production:-
List of most frequent categorical variables
# make list with top 10 variables top_10 = [x for x in new_df.Neighborhood.value_counts().sort_values(ascending=False).head(10).index] top_10
production:-
[‘NAmes’,
‘CollgCr’,
‘OldTown’,
‘Edwards’,
‘Somerst’,
‘Gilbert’,
‘NridgHt’,
‘Sawyer’,
‘NWAmes’,
‘SawyerW’]
There are the 10 top categorical labels in the Neighborhood column.
Make binary
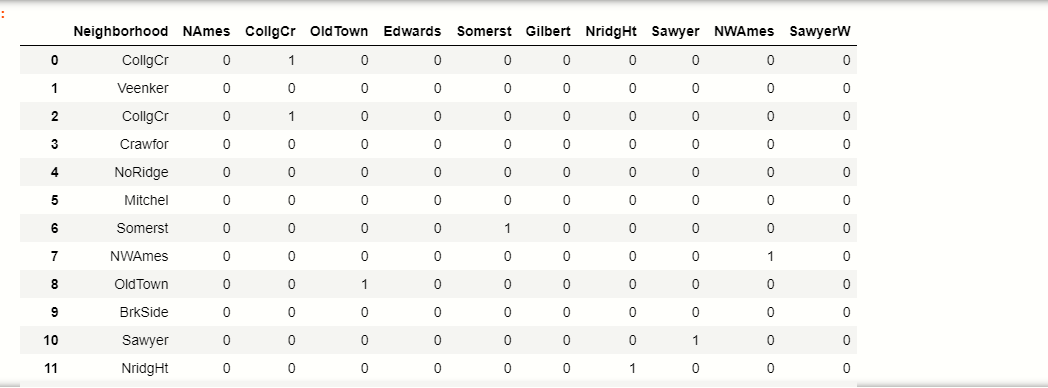
Now, we have to do the 10 binary variables of the top_10 labels:
# make binary labels
for tag in top_10:
new_df[label] = np.where (new_df[‘Neighborhood’]== label, 1,0)
new_df[[‘Neighborhood’]+ top_10]
production:-
| Names | CollgCr | Old Town | Edwards | Somerst | Gilbert | NridgHt | Sawyer | NWAmes | SawyerW | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CollgCr | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | Veenker | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | CollgCr | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | Crawfor | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | NoRidge | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | Mitchel | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | Somerst | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 7 | NWAmes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 8 | Old Town | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | BrkSide | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10 | Sawyer | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 11 | NridgHt | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
You can see how the top_10 tags are now converted to binary format.
Let's take an example, see in the table where 1 indexThe "Index" It is a fundamental tool in books and documents, which allows you to quickly locate the desired information. Generally, it is presented at the beginning of a work and organizes the contents in a hierarchical manner, including chapters and sections. Its correct preparation facilitates navigation and improves the understanding of the material, making it an essential resource for both students and professionals in various areas.... Veenker that did not belong to our tag top_10 categories, so it will result in 0 all columns.
Now we will do it for all the categorical variables that we have selected previously.
All variables selected in OneHotEncoding
# for all categorical variables we selected
def top_x(df2,variable,top_x_labels):
for label in top_x_labels:
df2[variable+'_'+label] = np.where(data[variable]==label,1,0)
# read the data again
data = pd.read_csv('D://xdatasets/train.csv',usecols = ['Neighborhood','Exterior1st','Exterior2nd'])
#encode Nighborhood into the 10 most frequent categories
top_x(data,'Neighborhood',top_10)
# display data
data.head()
Production:-

Now, here we apply one-hot encoding on all multi-category variables.
Now we will see the advantages and disadvantages of One Hot Encoding for multiple variables.
Advantage
- Easy to implement
- Does not require much time for variable exploration.
- Doesn't massively expand the feature space.
Disadvantages
- It does not add any information that could make the variable more predictive
- Do not save the information of ignored variables.
Final notes
Then, the summary of this is that we learn how to handle variables of multiple categories. If you run into this problem, so this is a very difficult task. So thanks for reading this article..
Connect with me on Linkedin: Profile
Read my other articles: https://www.analyticsvidhya.com/blog/author/mayurbadole2407/
Thank you
The media shown in this article is not the property of DataPeaker and is used at the author's discretion.





