This article was published as part of the Data Science Blogathon

Introduction
Learning. Logistic regression is generally used when we have to classify the data into two or more classes. One is binary and the other is multiple class logistic regression. As the name suggests, the binary class has 2 classes that are Yes / No, True / Fake, 0/1, etc. In the classification of multiple classes, there is more of 2 classes to classify data. But, before we go, let's first define the logistic regression:
“Logistic regression is a classification algorithm for categorical variables such as Yes / No, True / Fake, 0/1, etc.”
How does it differ from linear regression?
You may have also heard of linear regression. Let me tell you that there is a big difference between linear regression and logistic regression. Linear regression is used to generate continuous values such as house price, income, the population, etc. In the logistic regression, we generally calculate the probability that lies between the interval 0 Y 1 (both inclusive). Then the probability can be used to classify the data. For instance, if the calculated probability turns out to be greater than 0,5, then the data belonged to class A and, on the contrary, for less than 0,5, the data belonged to class B.
But my question is if we can still use linear regression for classification. My answer will be "Yes!! Why not? But it sure is an absurd idea ". My reason will be that you can assign a threshold value for linear regression, namely, if the predicted value is greater than the threshold value, belonged to class A; on the contrary, to class B. But it will give big error and poor model with low precision, that we really don't want. Right? I suggest you use only sort algorithms.
Now let's look at the linear regression graph shown below.
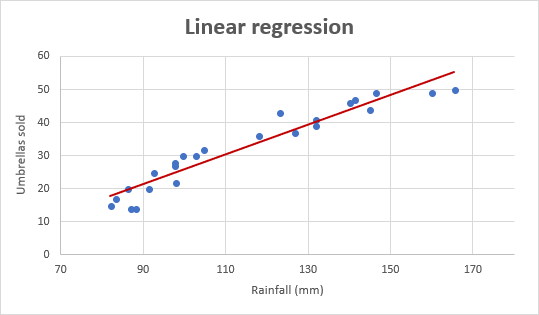
(Courtesy: https://www.ablebits.com/)
The graph is a straight line that passes through some points since we always avoid overfitting and misfit curves.
Now let's take a look at the logistic regression graph:
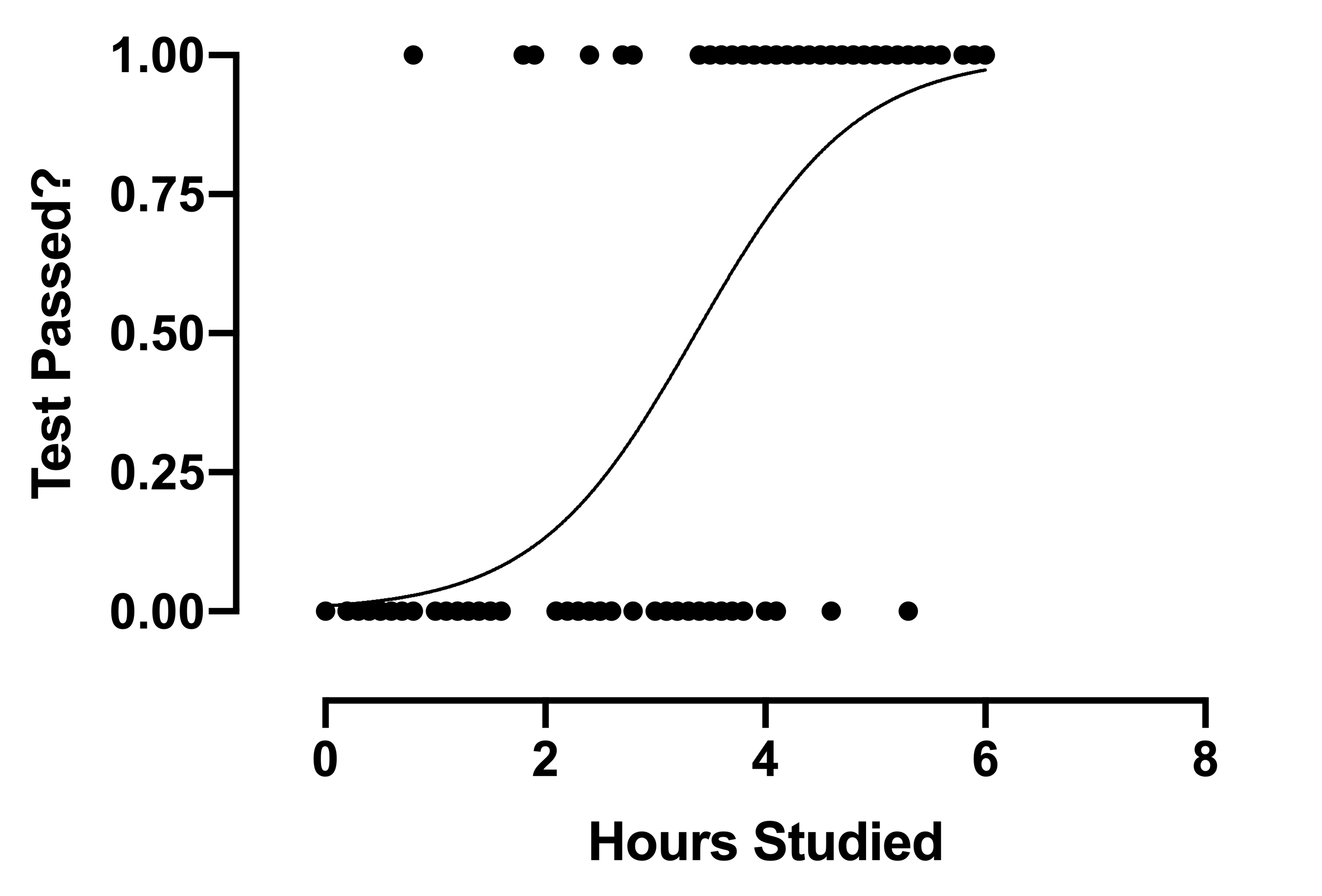
The graph is a curved line instead of a straight line, unlike linear regression.
This is a big difference between the two types of regression we just talked about.. So my next question is.
Why do we have a curved line for logistic regression instead of a straight line?
To answer this question, we will walk a bit through the linear regression and from there we will arrive at the logistic regression curve. That's fine? Let's start.
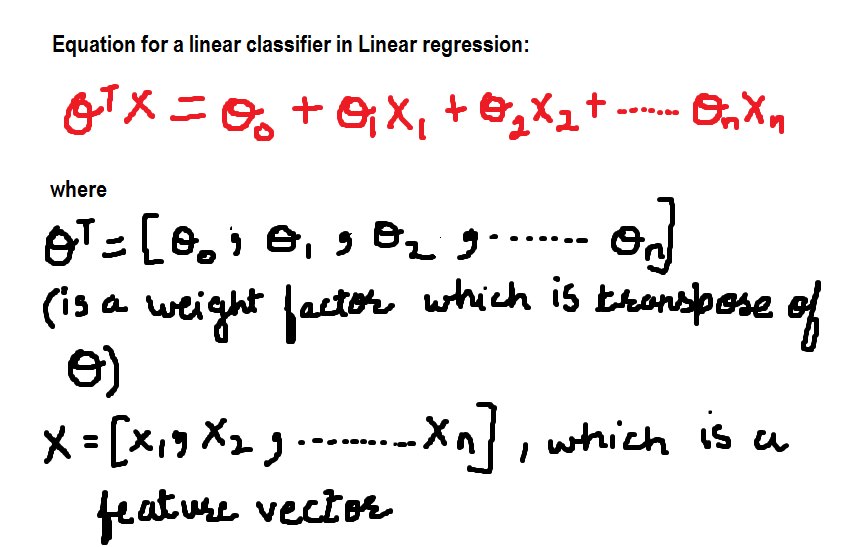
For now, the equation for the linear classifier is:
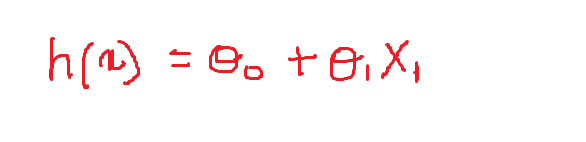
Now we will define the values of the variable weights:
theta_0 = -1 and theta = 0.1
Then, Our equation looks like this and the following is the graph that represents the equation in the 2-D plane:
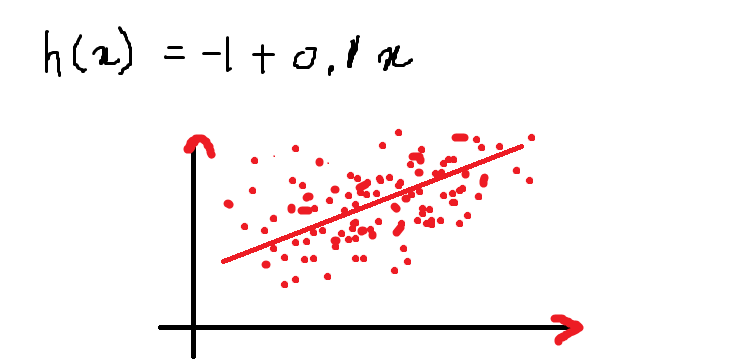
Above is an equation of a line for the given equation:
h (x) = – 1 + 0.1x
The value of the function h (x) when x = 13 it is:
h (13) = – 1+ (0,1) * (13) = 0,3
As described earlier in this article, I am defining the threshold in 0.5, which is any value of h greater than (equal to) 0.5 will be labeled as 1 Y, on the contrary, 0. We can define it as follows in the form of step function:

Now, agree with this, h has a value of 0.3, hence the value of y_hat = 0 according to the function defined above.
Now, One thing to note here is that each value greater than 0.5, suppose I say that the value of 'h’ it is 1000 for some value of x, then it will be labeled as 1 only, there is no difference between the value 1 Y 1000 since both are classified as 1 only. It's right? Can we accept this solution? Well, no! I would not accept it !!!
One more thing, What is the probability that h has a value of 0.3? All these questions remain unanswered. For these reasons, data scientists do not prefer to use linear regression for classification purposes.
before continuing, I want to show you how the y_hat function behaves graphically:
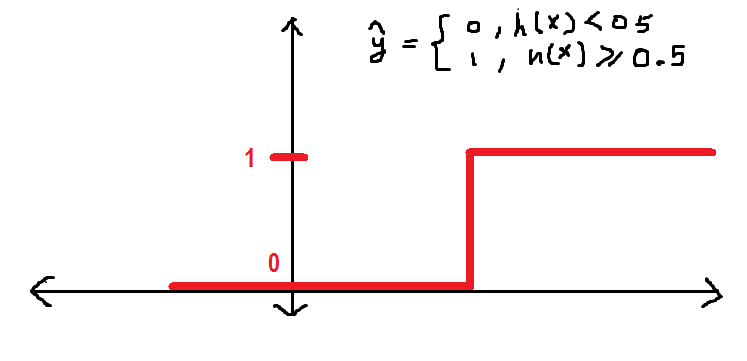
It will be better if we have a smoother curve instead of the old one. We'll see:
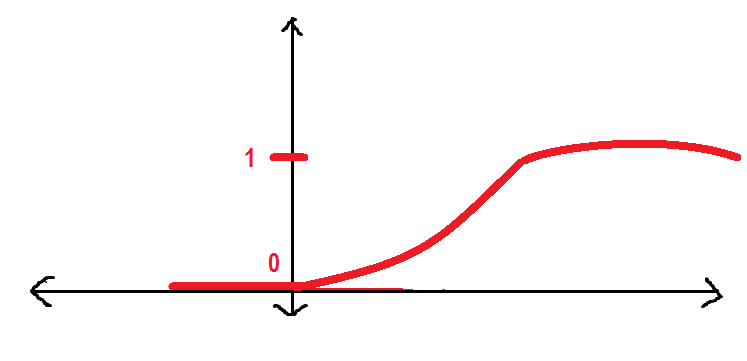
The above curve is known as Sigmoid function that we will use throughout this article. Here I will introduce the sigmoid function.
What is sigmoid function?
The sigmoid function is represented by the symbol sigma. Its graphical behavior has been described in the previous figure. The mathematical equation for the sigmoid function is described below:
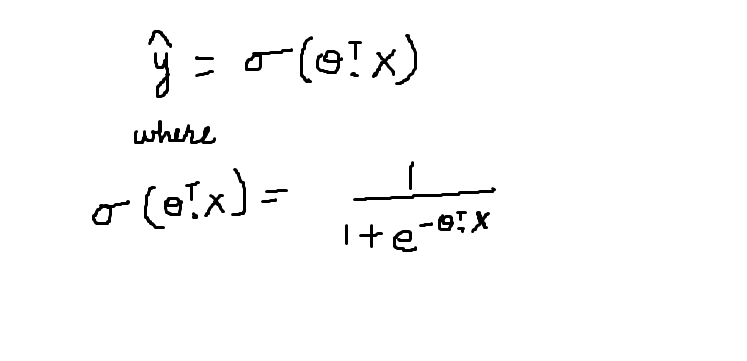
The sigmoid function gives the probability that the data belongs to a particular class that is in the interval [0,1]. Accept the scalar product of the theta transposition and the feature vector X as parameter. The resulting value is the probability.
Therefore, when P (Y = 1 | X) = sigmoide (theta * X)
P (Y = 0 | X) = 1- sigmoide (theta * X)
What's more, I want you to observe the behavior of the sigmoid function:
- When theta (transposition) * X gets so much bigger, the sigmoid value becomes equal to 1
- When theta (transposition) * X becomes very small the sigmoid value becomes equal to 0
Applications of logistic regression
In this section, I would like to discuss some of the applications of logistic regression.
1. Predicting the likelihood of a person having a heart attack
2. Predict a customer's propensity to buy a product or suspend a subscription.
3. Predict the probability of failure of a given process or product.
Before finishing this article, I just want to recap when you should use logistic regression:
- When your data is binary: 0/1, True / Fake, Yes / No
- When you need probabilistic results
- When your data can be linearly separated
- When you need to understand the impact of the feature.
Many other classification algorithms are widely used in addition to logistic regression such as kNN, decision trees, random forest and clustering algorithms as clustering of k-means. But logistic regression is a widely used algorithm and also easy to implement..
So it was all about the logistic regression algorithm for beginners. We have talked about everything you need to know about logistic regression theory. I hope you enjoyed my article!!
The media shown in this article is not the property of DataPeaker and is used at the author's discretion.





