Introduction
Python is one of the most beloved languages in the world of data science and machine learning. It is easy to learn and provides a lot of libraries and packages and has a good developer community. Python libraries and packages are a group of modules that makes our lives easier. There is more of 137,000 Python libraries and 198,826 Python packages prepared to facilitate the ordinary programming experience of engineers. These libraries and packages are planned for a variety of advanced fixes.
As a data science enthusiast, I've seen people who always talk about some famous libraries like data manipulation pandas and NumPy, for matplotlib data visualization, seaborn, plotly and many more, to model scikit-learn, TensorFlow, etc. In this article I'm not going to cover these libraries because there are already tons of blogs available, see my article on the most commonly used Python libraries here. But in his article, I'm going to cover some hidden gems from Python libraries that are unknown to the data science world. Here are some important libraries you can check out at 2021.

These libraries include functionalities such as handling lost values in an organized manner, handle emojis, convert numbers to ints and floats, visualization intelligence tools, time series modeling and many more. Covers a wide range of topics, from natural language processing to data visualization and time series. Then let's get started.
Table of Contents
- Missingo
- Emot
- Bamboolib
- ppscore
- AutoViz
- Numerator
- PyFlux
- Flash Text
Missingo
Real-world datasets usually contain many missing and null values. This can be due to a number of reasons, such as data leakage, data is not available, etc. Sometimes, it's very irritating to deal with this kind of messy data. This messy data requires special attention before being fed into machine learning algorithms., since these algorithms do not handle the lost values.
We need a better approach to managing these lost values. Here comes the magic of the Python library called missing. It helps us to tor deal with lost values with the help of data visualizations in a much better way. This is based on matplotlib. As of April 2021, has four types of charts to understand the distribution of missing data, namely, the bar graph. heat map, matrix and dendrogram. Then let's get started.
Installation
pip install missingo
Importing the library
import missingo as msns
In the bar chart below, you can see the number of lost values in each column:
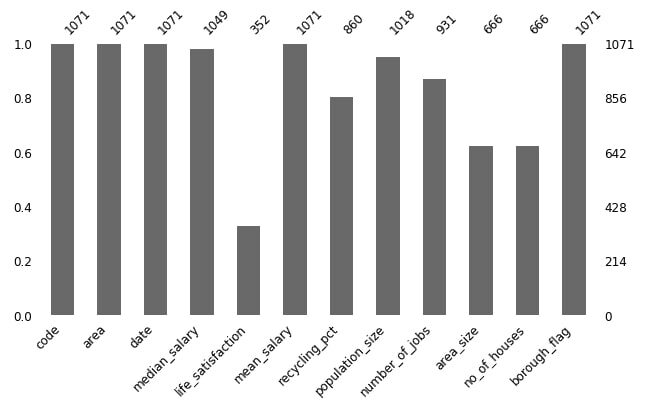
For more information, consult the official documentation: Link
Emot
Emojis are very common in chats. When it comes to natural language processing tasks, it's very tedious to deal with emojis. Here comes a very useful library to get rid of emoticons from text data. It is a famous Python library that is very useful when we have to dealing with Emoji and Emoticons. Works well with Python 2 and Python 3. Takes a string as input and returns a dictionary list. Then let's get started.
Installation
pip install emot
Importing the library
import emot
Code
import emot
text = "I love python 👨 :-)"
emot.emoji(text)
[{'value': '👨', 'mean': ':man:', 'location': [14, 14], 'flag': True}]
emot.emoticons(text)
{'value': [':-)'], 'location': [[16, 19]], 'mean': ['Happy face smiley'], 'flag': True}

For more information, consult the official documentation: Link
Bamboolib
Analyzing and visualizing information is the most meaningful and time-consuming interaction. We need to spend a lot of time researching unequivocally what the problem is here and what you are trying to say.. We use various types of Python libraries to visualize the examples and oddities in the dataset to get comfortable with the dataset..
Bamboolib is GUI for dataframe pandas that allows anyone to work with python in Jupyter Notebook or JupyterLab. Bamboolib is a deeply intelligent and widely supported library for examining, imagine and control information.
In fact, even a person without a programming base can use it to extract bits of knowledge from information., as no coding experience required. Bamboolib is not open source, which implies that you must buy bamboolib to use it, but offers a free preliminary form of 14 days for you to fully investigate it and perceive how it can be very valuable to you.
Installation
pip install bamboolib
Importing the library
import bamboolib

For more information, consult the official documentation: Link
Ppscore
Full ppscore is Predictive Power Score. This Python library is made by bamboolib developers. The Predictive Power Score is an alternative to the correlation matrix. This score is asymmetrical and can detect linear or nonlinear relationships between two columns in our dataset. So let's start with this library..
Installation
pip install ppscore
Importing the library
import ppscore
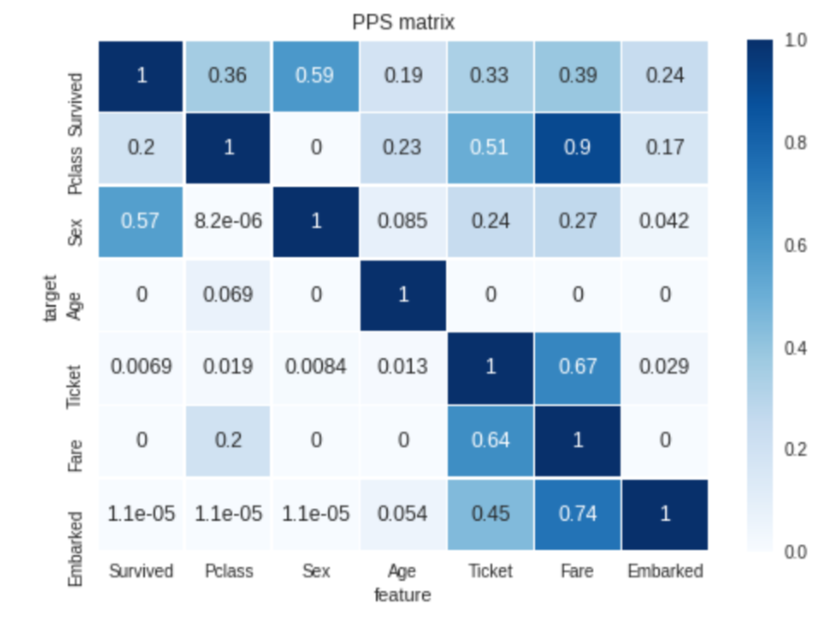
For more information, consult the official documentation: Link
AutoViz
It is the most underrated Python library ever used to perform exploratory data analysis. This library automatically displays any type of dataset, including also large data sets. Beautiful Visualizations can be drawn with a single code.. You just need to provide your data file (txt, JSON o CSV) and will automatically display it. Simply upload your data and AutoViz will automatically provide you with the right graphs that will help you get insights in a matter of seconds. Then let's get started.

Installation
pip install autoviz
Importing the library
import autoviz
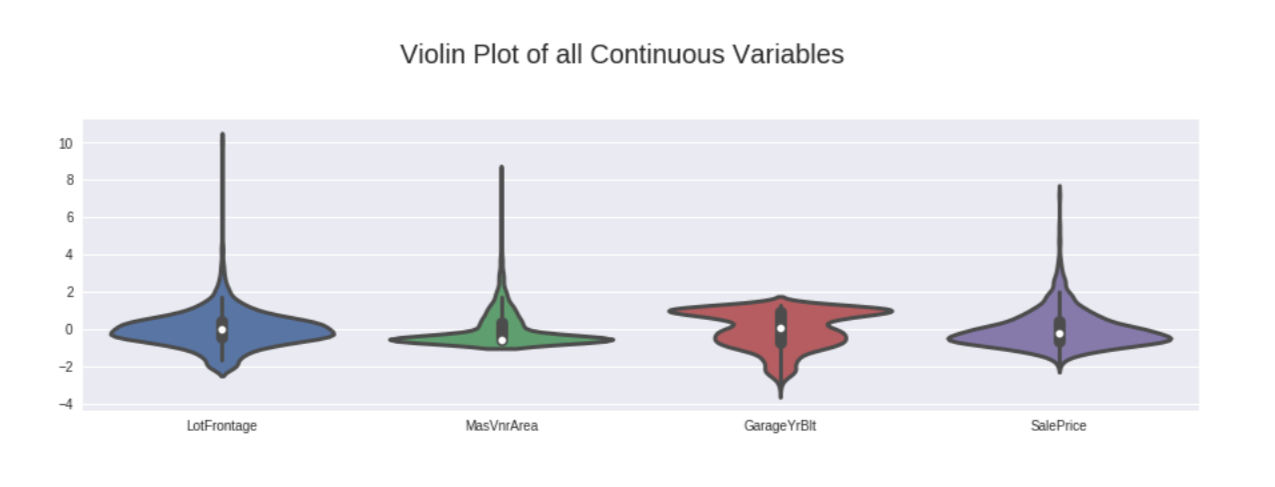
For more information, consult the official documentation: Link
Numerator
It is a very interesting Python module for word processing. That converts natural language numbers to floating and ints. This is a very useful module in natural language processing tasks. To
example, if you convert 'forty-two’ in 42, 'billion and one’ in 1000000001
etc. So let's get started.
Installation
pip install numerizer
Importing the library
from numerizer import numerize
Code
numerize('forty-two')
'42'
numerize('one billion and one')
'1000000001'
For more information, consult the official documentation: Link
PyFlux
Time series research is arguably the most frequently experienced problem in the area of machine learning.. PyFlux is an open source library in Python that worked unambiguously to work with time series issues. The library has a brilliant group of current-time layout models that include, but are not restricted to ARIMA models, GARCH and VAR. Therefore, PyFlux offers a probabilistic way of dealing with the visualization of the disposition of time. Then let's get started.
Installation
pip install pyflux
Importing the library
import pyflux
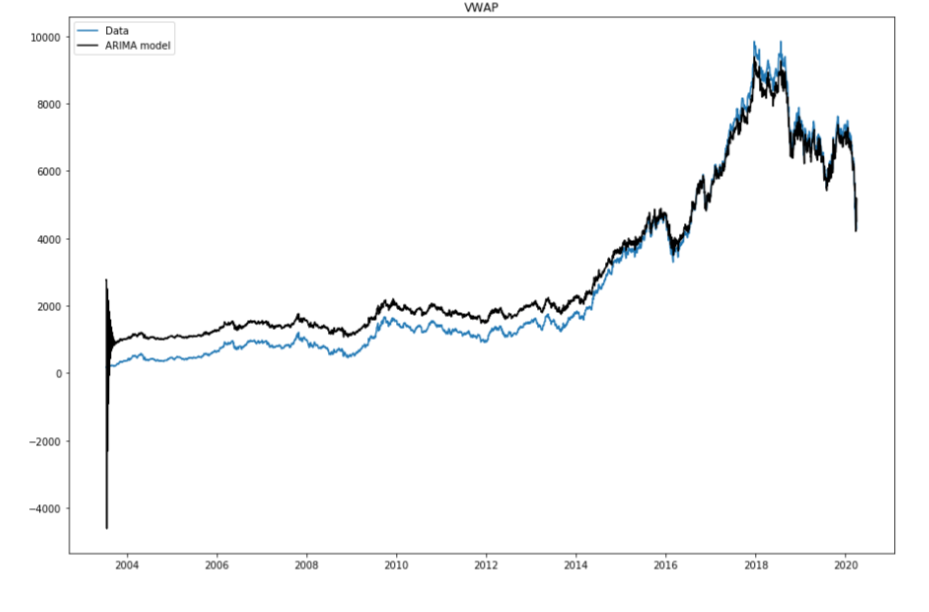
For more information, consult the official documentation: Link
FlashText
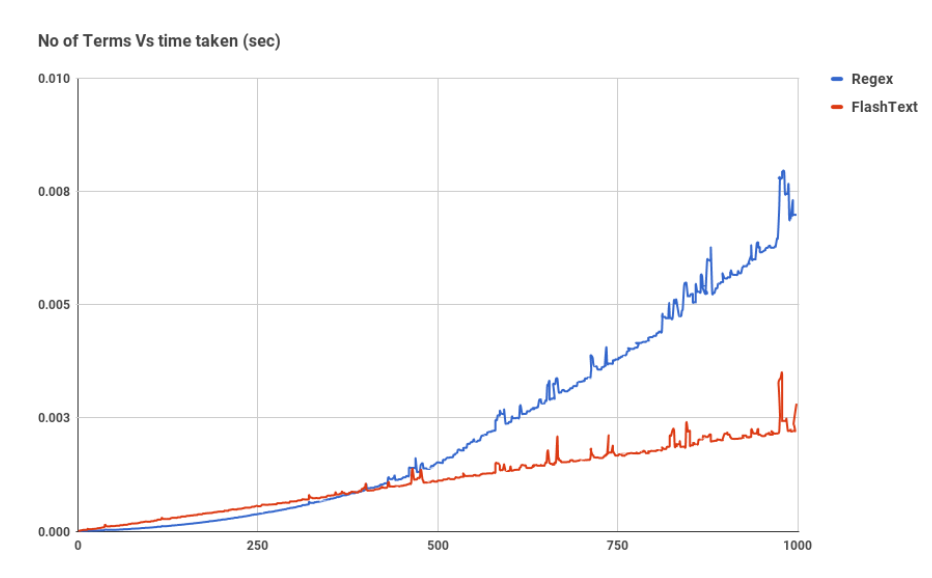
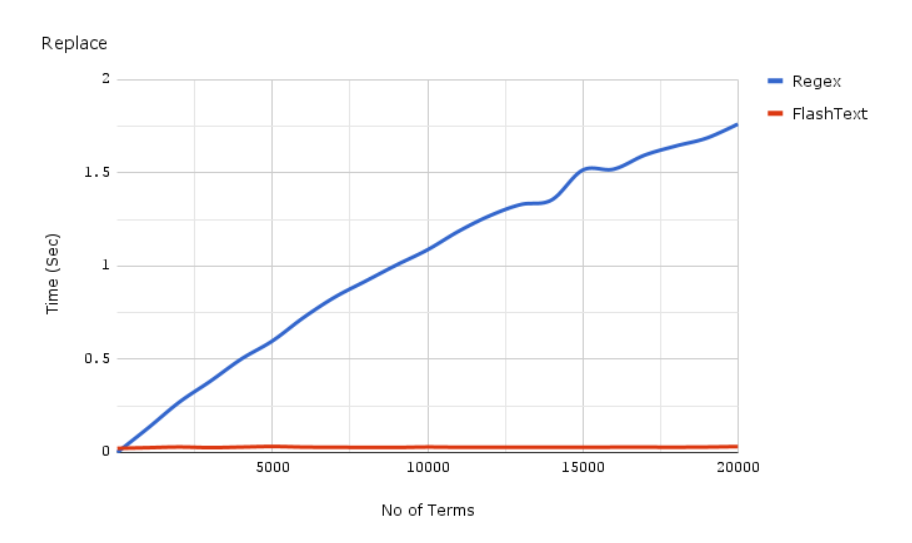
FlashText is a Python library made explicitly search in the substitution of words in a record. Nowadays, the operation of flashtext is that it requires a word or a summary of words and a string. the words that flashtext calls keywords are examined or replaced in the string.
Let us see information about how FlashText works. The moment keywords are passed to FlashText to search or impersonate, are saved as a Trie data structure that is productive in recovery mappings. Then let's get started.
Installation
pip install flashtext
Importing the library
import flashtext
Looking:
Replacement:
For more information, consult the official documentation: Link
Final note
You can check my articles here: Articles
Thank you for reading this article and for your patience.. Leave me in the comment section about comments. Share this article, it will give me the motivation to write more blogs for the data science community.
Email identification: gakshay1210@ gmail.com
Follow me on LinkedIn: LinkedIn
The media shown in this article about Python packages are not owned by DataPeaker and are used at the discretion of the author.





