Vue d'ensemble
- SQL est un langage incontournable pour tous ceux qui travaillent dans le domaine de la science des données ou de l'analyse.
- Ici il y a 8 Des techniques SQL ingénieuses pour l'analyse de données avec lesquelles les professionnels de l'analyse et de la science des données adoreront travailler
introduction
SQL est un engrenage clé dans l'arsenal d'un professionnel de la science des données. je parle par expérience: vous ne pouvez tout simplement pas espérer construire une carrière réussie dans la science des données ou l'analyse si vous n'avez pas encore appris SQL.
Et pourquoi SQL est-il si important?
Alors que nous entrons dans une nouvelle décennie, la vitesse à laquelle nous produisons et consommons des données monte en flèche de jour en jour. Pour prendre des décisions intelligentes basées sur les données, des organisations du monde entier embauchent des professionnels des données tels que des analystes commerciaux et des scientifiques des données pour extraire et dénicher des informations à partir de la vaste mine de données.
Et l'un des outils les plus importants nécessaires pour cela est, Je suppose que, SQL!

Le langage de requête structuré (SQL) existe depuis des décennies. C'est un langage de programmation utilisé pour gérer les données stockées dans des bases de données relationnelles. SQL est utilisé par la plupart des grandes entreprises dans le monde. Un analyste de données peut utiliser SQL pour accéder, lis, manipuler et analyser les données stockées dans une base de données et générer des informations utiles pour conduire un processus de prise de décision éclairé.
Dans cet article, je vais discuter 8 technique / Des requêtes SQL qui vous prépareront à tout problème d'analyse de données avancée. Veuillez noter que cet article suppose une compréhension très basique de SQL.
Je vous suggère de consulter les cours ci-dessous si vous débutez avec SQL et / ou analyse commerciale:
Table des matières
- Commençons par comprendre l'ensemble de données
- Technique SQL n. ° 1: compter les lignes et les éléments
- Technique SQL n. ° 2: fonctions d'agrégation
- Technique SQL # 3: Identification des valeurs extrêmes
- Technique SQL n. ° 4: données coupées
- Technique SQL n. ° 5: limitation des données
- Technique SQL n. ° 6: classification des données
- Technique SQL n. ° 7: modèles de filtre
- Technique SQL n. ° 8: groupes, accumulation de données et filtrage en groupes
Commençons par comprendre l'ensemble de données
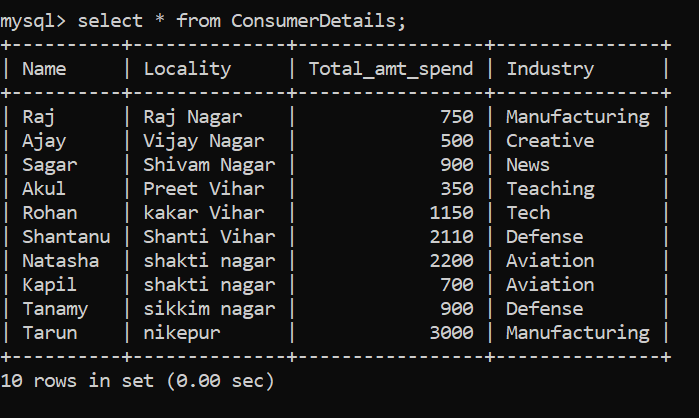
Quelle est la meilleure façon d'apprendre à analyser des données? Le faire côte à côte sur un ensemble de données !! Dans ce but, J'ai créé un jeu de données factice d'un magasin de détail. Le tableau des données client est représenté par Détails du consommateur.
Notre ensemble de données se compose des colonnes suivantes:
- nom – Le nom du consommateur
- localité – L'emplacement du client
- Total_amt_spend – Le montant total d'argent dépensé par le consommateur dans le magasin.
- Industrie – Cela signifie l'industrie à laquelle appartient le consommateur
Noter: – je vais utiliser MySQL 5.7 avancer dans l'article. Vous pouvez le télécharger à partir d'ici – Descargas de My SQL 5.7.
Technique SQL n. ° 1: nombre de lignes et d'articles
Nous allons commencer notre analyse par la requête la plus simple, c'est-à-dire, compter le nombre de lignes dans notre tableau. Nous allons le faire en utilisant la fonction – COMPTER ().
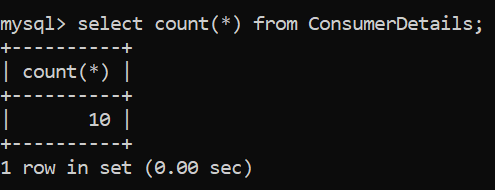
Excellent! Maintenant, nous connaissons le nombre de lignes dans notre table, Qu'est que c'est 10. Il peut sembler amusant d'utiliser cette fonction sur un petit ensemble de données de test, Mais cela peut aller très loin lorsque vos rangs se comptent par millions !!
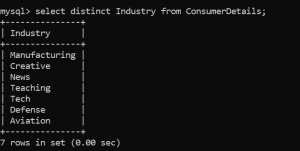
Beaucoup de fois, notre table de données est pleine de valeurs en double. Pour atteindre la valeur unique, on utilise la fonction DISTINCT.
Dans notre jeu de données, Comment pouvons-nous trouver les industries uniques auxquelles les clients appartiennent?
Vous l'avez deviné. Nous pouvons le faire en utilisant la fonction DISTINCT.
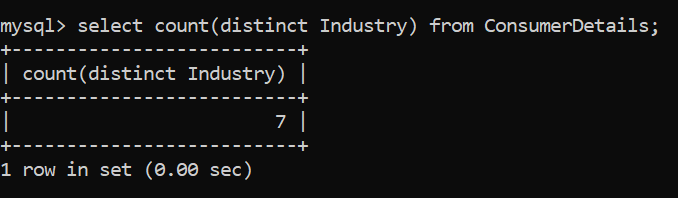
Vous pouvez même compter le nombre de lignes uniques en utilisant le comptage en conjonction avec différents. Vous pouvez vous référer à la requête suivante:
Technique SQL # 2 – Fonctions d'agrégation
Les fonctions d'agrégation sont à la base de tout type d'analyse de données. Ils nous donnent un aperçu de l'ensemble de données. Certaines des fonctions dont nous allons discuter sont: SOMME (), MOYENNE () et STDDEV ().
Nous utilisons le SOMME() fonction pour calculer la somme de la colonne numérique dans un tableau.
Découvrons la somme du montant dépensé par chacun des clients:
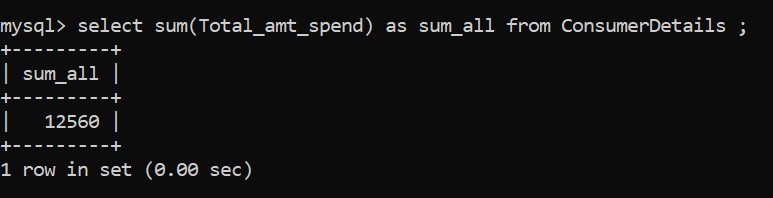
Dans l'exemple ci-dessus, somme_tout est la variable dans laquelle la valeur de la somme est stockée. La somme des sommes dépensées par les consommateurs est de Rs. 12.560.
Pour calculer la moyenne des colonnes numériques, nous utilisons le MOYENNE () une fonction. Trouvons les dépenses de consommation moyennes pour notre magasin de détail:
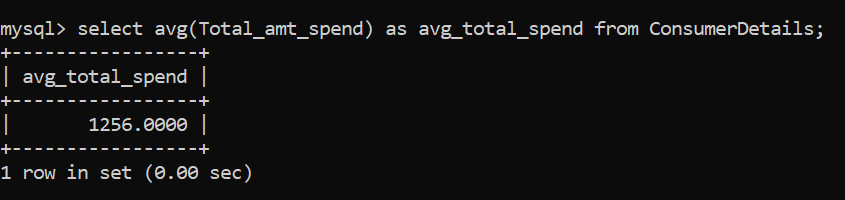
Le montant moyen dépensé par les clients dans le magasin de détail est de Rs. 1256.
-
Calculer l'écart type
Si vous avez examiné l'ensemble de données, puis la valeur moyenne des dépenses de consommation, vous aurez remarqué qu'il manque quelque chose. La moyenne ne donne pas une image complète, cherchons donc une autre métrique importante: l'écart type. La fonction est STDDEV ().
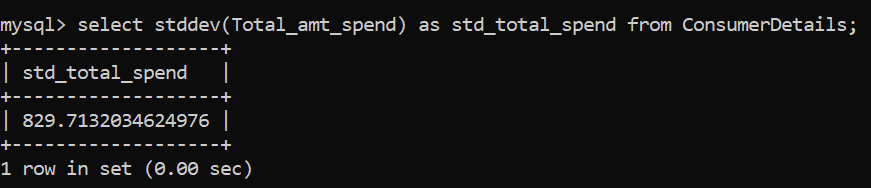
L'écart type s'avère être 829,7, ce qui signifie qu'il existe une grande disparité entre les dépenses de consommation.
Technique SQL # 3 – Identification des valeurs extrêmes
Le prochain type d'analyse consiste à identifier des valeurs extrêmes qui vous aideront à mieux comprendre les données..
La valeur numérique maximale peut être identifiée par la fonction MAX (). Voyons comment l'appliquer:
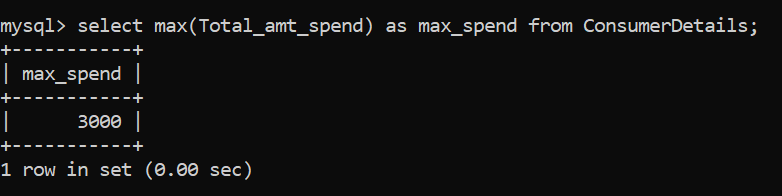
Le montant maximum d'argent que le consommateur dépense dans le magasin de détail est de Rs. 3000.
Similaire à la fonction max, nous avons la fonction MIN () pour identifier la valeur numérique minimale dans une colonne donnée:
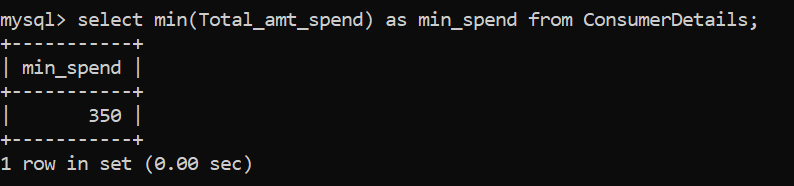
Le montant minimum d'argent dépensé par le consommateur du magasin de détail est de Rs. 350.
Technique SQL n. ° 4: données coupées
À présent, concentrons-nous sur l'une des parties les plus importantes de l'analyse des données: diviser les données. Cette section de l'analyse constituera la base des requêtes avancées et vous aidera à récupérer des données en fonction d'un certain type de condition..
- Disons que le magasin de détail veut trouver des clients qui viennent d'une localité, spécifiquement Shakti Nagar et Shanti Vihar. Quelle sera la requête pour cela?
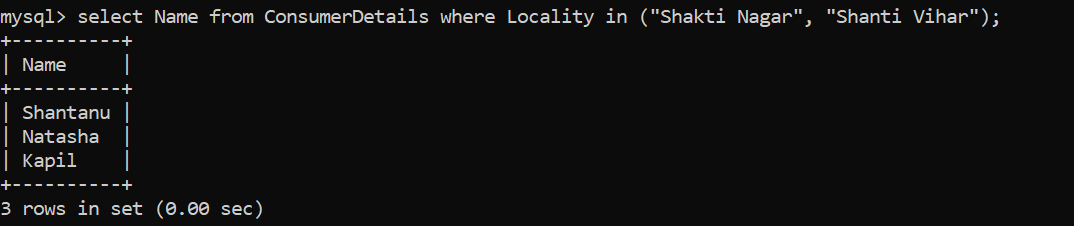
Genial, avoir 3 les clients! Nous avons utilisé la clause WHERE pour filtrer les données en fonction de la condition que les consommateurs doivent vivre dans la localité: Shakti Nagar et Shanti Vihar. Je n'ai pas utilisé la condition OR ici. À sa place, J'ai utilisé l'opérateur IN qui nous permet de spécifier plusieurs valeurs dans la clause WHERE.
- Nous devons trouver des clients qui vivent dans des endroits spécifiques (Shakti Nagar et Shanti Vihar) et dépenser un montant supérieur à Rs. 2000.

Dans notre jeu de données, seuls Shantanu et Natasha remplissent ces conditions. Comment les deux conditions doivent être remplies, la condition AND est la mieux adaptée ici. Voyons un autre exemple pour diviser nos données.
- Cette fois, le magasin de détail veut reconquérir tous les consommateurs qui dépensent entre Rs. 1000 y Rs. 2000 pour générer des offres marketing spéciales. Quelle sera la requête pour cela?
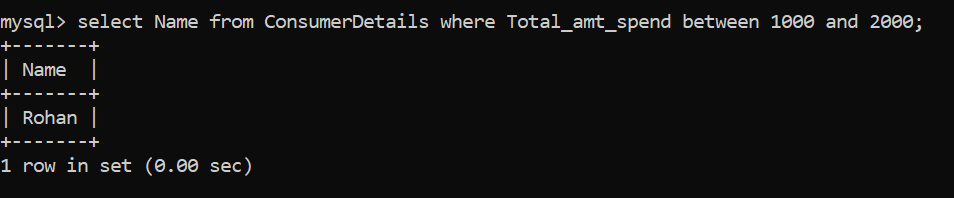
Une autre façon d'écrire la même déclaration serait:

Seul Rohan efface ce critère !!
Excellent! Nous avons atteint le milieu de notre voyage. Développons davantage sur les connaissances que nous avons acquises jusqu'à présent.
Technique SQL n. ° 5: limitation des données
Disons que nous voulons voir la table de données composée de millions d'enregistrements. Nous ne pouvons pas utiliser l'instruction SELECT directement car cela viderait la table entière sur notre écran, ce qui est lourd et gourmand en calcul. À sa place, nous pouvons utiliser le LIMITE clause:
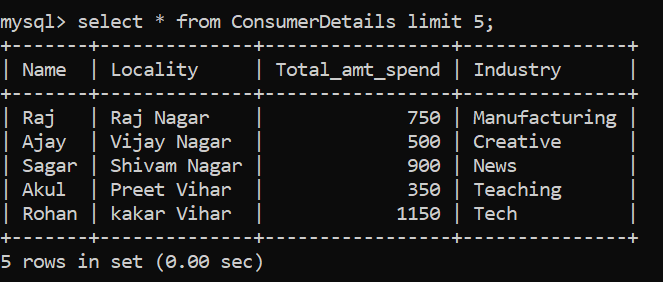
La commande SQL ci-dessus nous aide à montrer le premier 5 lignes du tableau.
Que ferez-vous si vous ne souhaitez sélectionner que les quatrième et cinquième lignes? Nous utiliserons la clause OFFSET. La clause OFFSET ignorera le nombre de lignes spécifié. Voyons voir comment ça fonctionne:
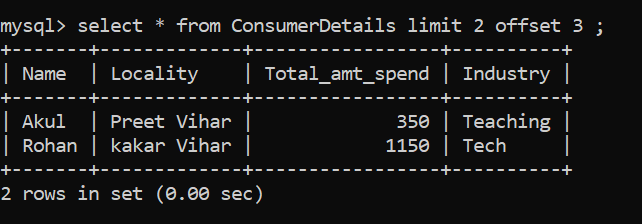
Technique SQL n. ° 6: classification des données
Le tri des données nous aide à mettre nos données en perspective. Nous pouvons effectuer le processus de classification en utilisant le mot-clé – COMMANDÉ PAR.
Le mot-clé peut être utilisé pour trier les données par ordre croissant ou décroissant. Le mot clé ORDER BY trie les données par ordre croissant par défaut.
Voyons un exemple dans lequel nous trions les données selon la colonne Total_amt_spend dans l'ordre croissant:
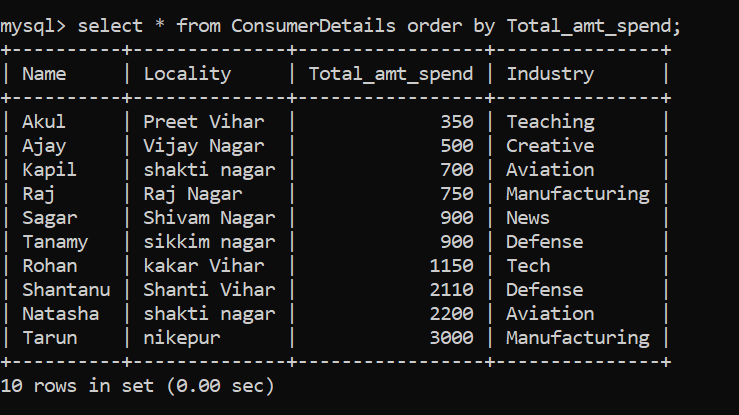
Impressionnant! Pour trier l'ensemble de données par ordre décroissant, on peut suivre la commande suivante:
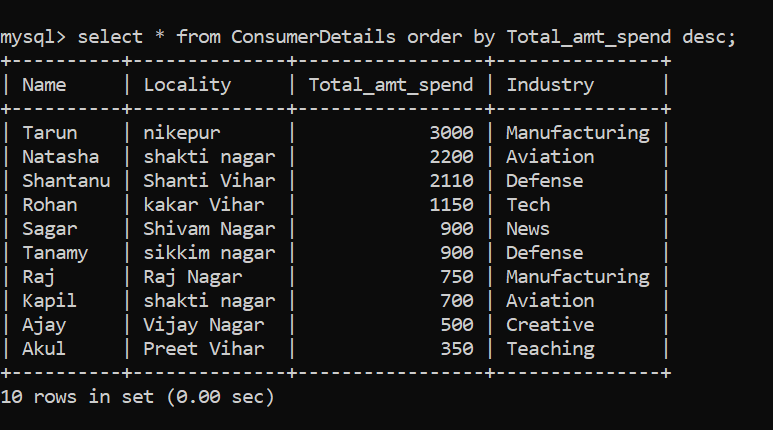
Technique SQL # 7 – Modèles de filtrage
Dans les sections précédentes, nous avons appris à filtrer les données en fonction d'une ou plusieurs conditions. Ici, nous allons apprendre à filtrer les colonnes qui correspondent à un modèle spécifique. Pour continuer avec ça, nous allons d'abord comprendre l'opérateur LIKE et les caractères génériques.
L'opérateur LIKE est utilisé dans une clause WHERE pour rechercher un modèle spécifique dans une colonne.
Le caractère générique est utilisé pour remplacer un ou plusieurs caractères dans une chaîne. Ceux-ci sont utilisés en conjonction avec l'opérateur LIKE. Les deux caractères génériques les plus courants sont:
-
- %: Cela représente 0 ou plusieurs caractères
- _ – Représente un seul personnage
Dans notre ensemble de données de vente au détail fictif, disons que nous voulons toutes les localités qui se terminent par "Nagar". Prenez un moment pour comprendre l'énoncé du problème et réfléchissez à la façon dont nous pouvons le résoudre.
Essayons de résoudre le problème. Nous exigeons que tous les emplacements se terminent par “Nagar” et ils peuvent avoir n'importe quel nombre de caractères avant cette chaîne particulière. Donc, nous pouvons utiliser le joker “%” avant de “Nagar”:
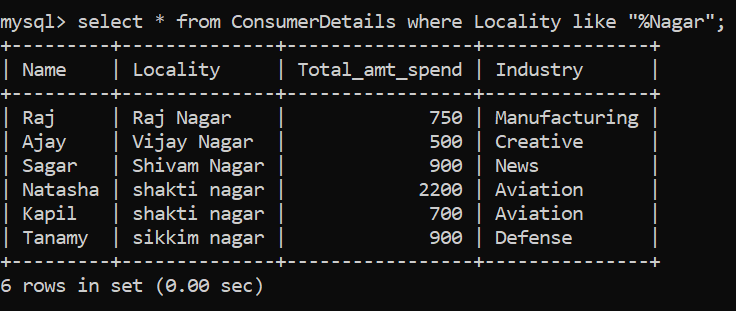
Impressionnant, avoir 6 localités qui se terminent par ce nom. Notez que nous utilisons l'opérateur LIKE pour effectuer une correspondance de modèle.
Ensuite, nous allons essayer de résoudre un autre problème basé sur des modèles. Nous voulons les noms des consommateurs dont le deuxième caractère a “une” en leurs noms respectifs. Encore, Je vous suggère de prendre un moment pour comprendre le problème et réfléchir à une logique pour le résoudre.
Analysons le problème. Ici, le deuxième caractère doit être “une”. Le premier caractère peut être n'importe quoi, nous substituons donc cette lettre au caractère générique "_". Après le deuxième caractère, il peut y avoir n'importe quel nombre de caractères, nous substituons donc ces caractères par le caractère générique “%”. Le match de modèle final ressemblera à ceci:
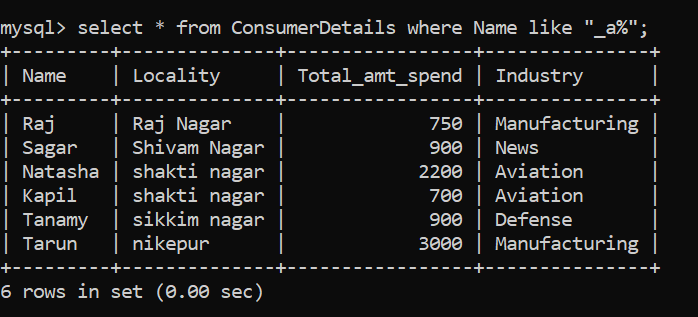
Ont 6 les gens qui satisfont à cette étrange condition!
Technique SQL n. ° 8: groupes, accumulation de données et filtrage en groupes
Nous sommes enfin arrivés à l'un des outils d'analyse les plus puissants en SQL: le regroupement de données effectué à l'aide de l'instruction GROUP BY. L'application la plus utile de cette déclaration est de trouver la distribution des variables catégorielles. Cela se fait à l'aide de l'instruction GROUP BY en conjonction avec des fonctions d'agrégation telles que – COMPTER, SOMME, MOYENNE, etc.
Essayons de mieux comprendre cela en prenant un énoncé du problème. Le magasin de détail veut trouver le nombre de clients correspondant aux industries auxquelles il appartient:

Nous observons que le nombre de clients appartenant aux différentes industries est plus ou moins le même. Ensuite, Allons de l'avant et trouvons la somme des dépenses des clients regroupés par l'industrie à laquelle ils appartiennent:
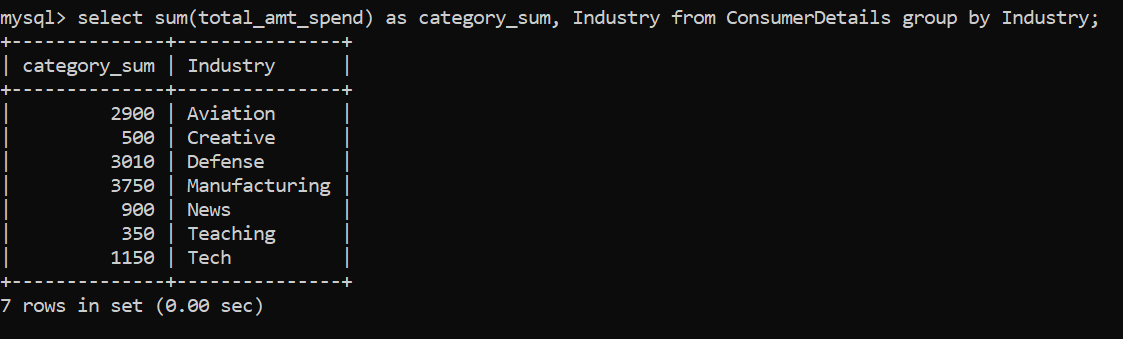
Nous pouvons voir que le montant maximum d'argent dépensé est par les clients appartenant à la Fabrication industrie. Cela semble un peu facile, vérité? Avançons et compliquons les choses.
À présent, le détaillant veut trouver les industries dont Montant total est supérieur à 2500. Pour résoudre ce problème, nous regrouperons les données par industrie puis utiliserons la clause HAVING.
La clause HAVING est comme la clause WHERE mais uniquement pour filtrer les données regroupées. Rappelles toi, viendra toujours après l'instruction GROUP BY.

Nous n'avons que 3 catégories qui remplissent les conditions: Aviation, Défendre, Oui Fabrication. Mais pour que ce soit plus clair, Je vais également ajouter le mot clé ORDER BY pour le rendre plus intuitif:

Remarques finales
Je suis tellement content que tu sois arrivé jusqu'ici. Ce sont les blocs de construction de toutes les requêtes d'analyse de données en SQL. Vous pouvez également effectuer des requêtes avancées en utilisant ces bases. Dans cet article, j'ai utilisé mysql 5.7 donner des exemples.
J'espère vraiment que ces requêtes SQL vous aideront au quotidien lorsque vous analysez des données complexes. Ayez l'un de vos trucs et astuces pour analyser les données en SQL? Faites-moi savoir dans les commentaires!!





