Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
Panoramica
divennero, verità? Raggruppiamo i punti dati in 3 gruppi in base alla loro somiglianza o vicinanza.
Sommario
1.Introduzione a K significa
2.K significa ++ algoritmo
3.Come scegliere il valore K in K significa?
4.Considerazioni pratiche sul K . medio
5.Tendencia de grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro....
1. introduzione
Comprendiamo solo il raggruppamento di mezzi K con esempi della vita quotidiana. Sappiamo che in questi giorni tutti amano guardare serie web o film su Amazon Prime, Netflix. Hai mai osservato qualcosa ogni volta che apri Netflix?? vale a dire, film di gruppo in base al loro genere, vale a dire, crimine, sospeso, eccetera., Spero che tu l'abbia osservato o lo sappia già. quindi il raggruppamento del genere Netflix è un esempio di raggruppamento di facile comprensione. capiamo di più su k significa algoritmo di clustering.
Definizione: Raggruppa i punti dati in base alla loro somiglianza o vicinanza reciproca, in parole povere, l'algoritmo deve trovare i punti dati i cui valori sono simili tra loro e, così, questi punti apparterrebbero allo stesso gruppo.
Quindi, Come fa l'algoritmo a trovare i valori tra due punti per raggrupparli?? El algoritmo encuentra los valores usando el método de ‘MisurareIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... de distancia’. qui la misura della distanza è "distanza euclidea"’
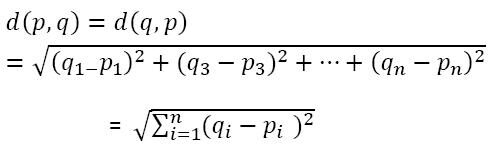
Le osservazioni più vicine o simili tra loro avrebbero una distanza euclidea bassa e quindi sarebbero raggruppate.
un'altra formula che devi sapere per capire i mezzi di K è "Centroid". L'algoritmo k-means utilizza il concetto di centroide per creare "k gruppi".
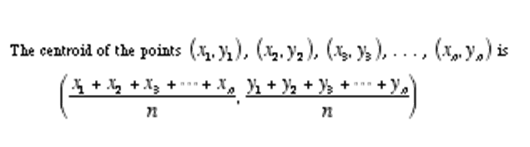
Quindi ora sei pronto per capire i passaggi dell'algoritmo di clustering k-means.
Passi in K-mezzi:
passo 1: scegli il valore k per ex: k = 2
passo 2: inizializza casualmente i centroidi
passo 3: calcolare la distanza euclidea dai centroidi a ciascun punto dati e formare gruppi vicini ai centroidi
passo 4: trova il baricentro di ogni gruppo e aggiorna i centroidi
passo: 5 ripetere il passaggio 3
Ogni volta che si creano gruppi, aggiornamento centroidi, il baricentro aggiornato è il centro di tutti i punti che ricadono nel gruppo. Questo processo continua fino a quando il baricentro non cambia più, vale a dire, la soluzione converge.
Puoi giocare con l'algoritmo K-means usando il link qui sotto, Provalo.
https://stanford.edu/class/engr108/visualizations/kmeans/kmeans.html
Quindi, Qual è il prossimo? Come si scelgono a caso i centroidi iniziali??
Ecco il concetto di algoritmo k-Means ++.
2. Algoritmo K-Mezzi ++:
Non ti stresserò per questo, quindi non preoccuparti. È molto facile da capire. Quindi, Che cosa significa k? ++ ??? Diciamo di voler scegliere inizialmente due centroidi (k = 2), puoi scegliere un centroide a caso o puoi scegliere uno dei punti dati a caso. semplice verità? Il nostro prossimo compito è scegliere un altro centroide, Come lo scegli? qualche idea?
Scegliamo il prossimo centroide dei punti dati che è a grande distanza dal centroide esistente o quello che è a grande distanza da un gruppo esistente che ha un'alta probabilità di catturare.
3.Come scegliere il valore K in K-means:
1.Metodo del gomito
Passi:
passo 1: calcolare l'algoritmo di clustering per diversi valori di k.
per esempio k =[1,2,3,4,5,6,7,8,9,10]
passo 2: per ogni k, calcolare la somma dei quadrati all'interno del cluster (WCSS).
passo 3: tracciare la curva WCSS in base al numero di cluster.
passo 4: La posizione della curva sulla trama è generalmente considerata un indicatore del numero approssimativo di cluster.
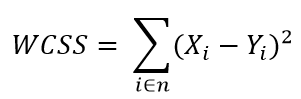
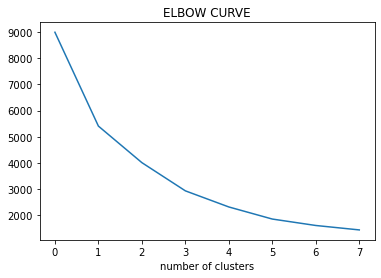
Considerazioni pratiche in K-mezzi:
- Un certo numero di cluster scelti in anticipo (K).
- Standardizzazione dei dati (ridimensionato).
- Dati categoriali (può essere risolto con la modalità K).
- Impatto dei centroidi e dei valori anomali iniziali.
5. Tendenza cluster:
Prima di applicare un algoritmo di clustering ai dati forniti, è importante verificare se i dati forniti hanno alcuni cluster significativi o meno. Il processo per valutare i dati per verificare se i dati sono fattibili per il clustering o meno è noto come "tendenza cluster", quindi non dovremmo applicare alla cieca il metodo di raggruppamento e controllare l'andamento del raggruppamento. Come?
Usiamo la "statistica Hopkins"’ per sapere se eseguire il clustering o meno per un determinato set di dati. Esaminare se i punti dati differiscono significativamente dai dati distribuiti uniformemente nello spazio multidimensionale.
Con esto concluye nuestro artículo sobre el algoritmo de raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro.. de k-means. Nel mio prossimo articolo, Parlerò dell'implementazione Python dell'algoritmo di clustering K-means.
Grazie!
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





