Introdução
Al crear un modelo de aprendizaje automático en la vida real, es casi raro que todas las variables del conjunto de datos sean útiles para crear un modelo. Agregar variables redundantes reduce la capacidad de generalización del modelo y también puede reducir la precisión general de un clasificador. O que mais, agregar más y más variables a un modelo aumenta la complejidad general del modelo.
Según el Ley de la parsimonia a partir de ‘navalha de Occam’, la mejor explicación a un problema es la que involucra la menor cantidad de supuestos posibles. Portanto, la selección de características se convierte en una parte indispensable de la construcción de modelos de aprendizaje automático.
objetivo
El objetivo de la selección de características en el aprendizaje automático es encontrar el mejor conjunto de características que le permita construir modelos útiles de los fenómenos estudiados.
Las técnicas para la selección de funciones en el aprendizaje automático se pueden clasificar en general en las siguientes categorías:
Técnicas supervisadas: Estas técnicas se pueden usar para datos etiquetados y se usan para identificar las características relevantes para aumentar la eficiencia de modelos supervisados como clasificación y regresión.
Técnicas no supervisadas: Estas técnicas se pueden utilizar para datos sin etiquetar.
Desde un punto de vista taxonómico, estas técnicas se clasifican en:
UMA. Métodos de filtrado
B. Métodos de envoltura
C. Métodos integrados
D. Métodos híbridos
Neste artigo, analizaremos algunas técnicas populares de selección de funciones en el aprendizaje automático.
UMA. Métodos de filtrado
Los métodos de filtro recogen las propiedades intrínsecas de las características medidas a través de estadísticas univariadas en lugar del rendimiento de validación cruzada. Estos métodos son más rápidos y menos costosos computacionalmente que los métodos de envoltura. Cuando se trata de datos de alta dimensão"Dimensão" É um termo usado em várias disciplinas, como a física, Matemática e filosofia. Refere-se à extensão em que um objeto ou fenômeno pode ser analisado ou descrito. Em física, por exemplo, fala-se de dimensões espaciais e temporais, enquanto em matemática pode se referir ao número de coordenadas necessárias para representar um espaço. Compreendê-lo é fundamental para o estudo e..., es computacionalmente más económico utilizar métodos de filtrado.
Analicemos algunas de estas técnicas:
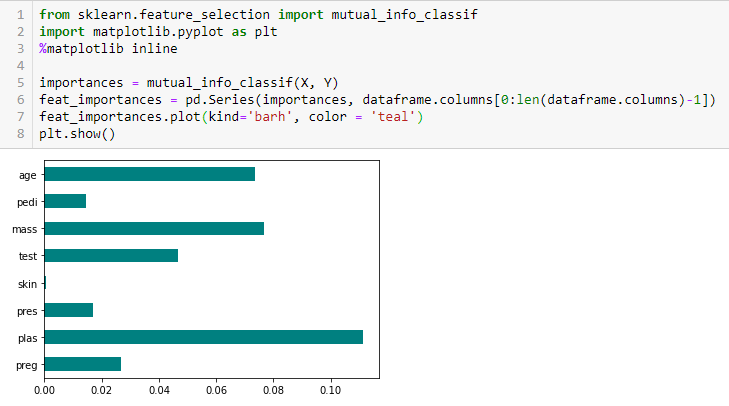
Ganho de informação
La ganancia de información calcula la reducción de la entropía a partir de la transformación de un conjunto de datos. Se puede utilizar para la selección de características evaluando la ganancia de información de cada variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... en el contexto de la variable de destino.
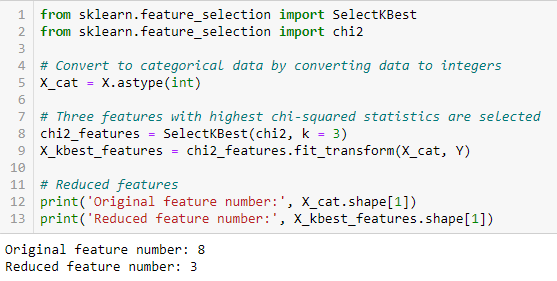
Teste qui-quadrado
La prueba de chi-cuadrado se usa para características categóricas en un conjunto de datos. Calculamos Chi-cuadrado entre cada característica y el objetivo y seleccionamos el número deseado de características con las mejores puntuaciones de Chi-cuadrado. Para aplicar correctamente el chi-cuadrado para probar la relación entre varias características en el conjunto de datos y la variable objetivo, se deben cumplir las siguientes condiciones: las variables deben ser categórico, muestreado independientemente y los valores deben tener un frecuencia esperada mayor que 5.
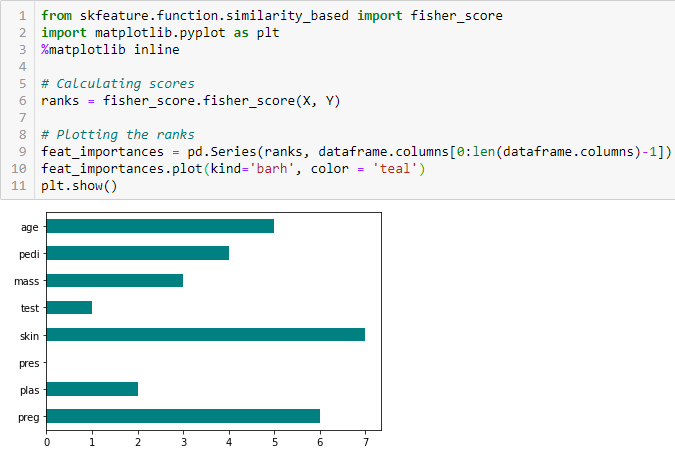
Puntuación de Fisher
La puntuación de Fisher es uno de los métodos de selección de características supervisadas más utilizados. El algoritmo que usaremos devuelve los rangos de las variables basados en la puntuación del pescador en orden descendente. Luego podemos seleccionar las variables según el caso.
Coeficiente de correlación
La correlación es una mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... de la relación lineal de 2 ou mais variáveis. Mediante la correlación, podemos predecir una variable a partir de la otra. La lógica detrás del uso de la correlación para la selección de características es que las buenas variables están altamente correlacionadas con el objetivo. O que mais, las variables deben estar correlacionadas con el objetivo, pero no deben estar correlacionadas entre sí.
Si dos variables están correlacionadas, podemos predecir una a partir de la otra. Portanto, si dos características están correlacionadas, el modelo realmente solo necesita una de ellas, ya que la segunda no agrega información adicional. Usaremos la correlación de Pearson aquí.
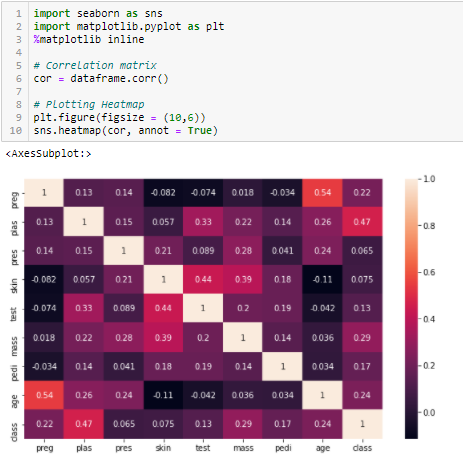
Necesitamos establecer un valor absoluto, Digamos 0.5 como el umbral para seleccionar las variables. Si encontramos que las variables predictoras están correlacionadas entre sí, podemos descartar la variable que tiene un valor de coeficiente de correlación más bajo con la variable objetivo. También podemos calcular múltiples coeficientes de correlación para comprobar si más de dos variables están correlacionadas entre sí. Este fenómeno se conoce como multicolinealidad.
Umbral de varianza
El umbral de varianza es un enfoque de línea de base simple para la selección de características. Elimina todas las características cuya variación no alcanza algún umbral. Por padrão, elimina todas las características de varianza cero, quer dizer, las características que tienen el mismo valor en todas las muestras. Suponemos que las características con una varianza más alta pueden contener información más útil, pero tenga en cuenta que no estamos teniendo en cuenta la relación entre las variables de característica o las variables de característica y objetivo, que es uno de los inconvenientes de los métodos de filtro.

Get_support devuelve un vector booleano donde True significa que la variable no tiene varianza cero.
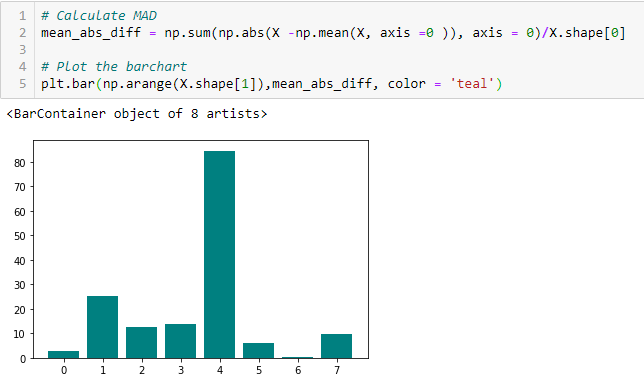
Diferencia absoluta media (MAD)
‘La diferencia absoluta media (MAD) calcula la diferencia absoluta del valor medio. La principal diferencia entre las medidas de varianza y MAD es la ausencia del cuadrado en esta última. El MAD, al igual que la varianza, también es una variante de escala ». [1] Esto significa que a mayor DMA, mayor poder discriminatorio.
Relación de dispersión
‘Otra medida de dispersión aplica la media aritmética (SOU) y la media geométrica (GM). Para una característica dada (Positivo) Xeu en n patrones, AM y GM están dados por
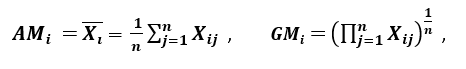
respectivamente; desde SOYeu ≥ GMeu, con igualdad si y solo si Xi1 = Xi2 =…. = Xsobre, luego la proporción
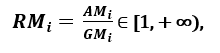
se puede utilizar como medida de dispersión. Una mayor dispersión implica un mayor valor de Ri, por lo que una característica más relevante. Pelo contrário, cuando todas las muestras de características tienen (aproximadamente) el mismo valor, Ri está cerca de 1, lo que indica una característica de baja relevancia ‘. [1]

 ‘
‘
B. Métodos de envoltura:
Los envoltorios requieren algún método para buscar en el espacio todos los posibles subconjuntos de características, evaluando su calidad aprendiendo y evaluando un clasificador con ese subconjunto de características. El proceso de selección de características se basa en un algoritmo de aprendizaje automático específico que intentamos encajar en un conjunto de datos determinado. Sigue un enfoque de búsqueda codiciosa al evaluar todas las posibles combinaciones de características contra el criterio de evaluación. Los métodos de envoltura generalmente dan como resultado una mejor precisión predictiva que los métodos de filtro.
Analicemos algunas de estas técnicas:
Selección de funciones avanzadas
Este es un método iterativo en el que comenzamos con la variable de mejor rendimiento contra el objetivo. A seguir, seleccionamos otra variable que ofrezca el mejor rendimiento en combinación con la primera variable seleccionada. Este proceso continúa hasta que se alcanza el criterio preestablecido.
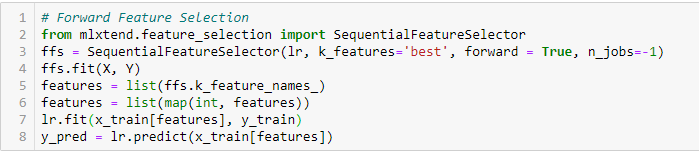
Eliminación de características hacia atrás
Este método funciona exactamente de manera opuesta al método de selección de características hacia adelante. Aqui, comenzamos con todas las funciones disponibles y construimos un modelo. A seguir, tomamos la variable del modelo que da el mejor valor de medida de evaluación. Este proceso continúa hasta que se alcanza el criterio preestablecido.
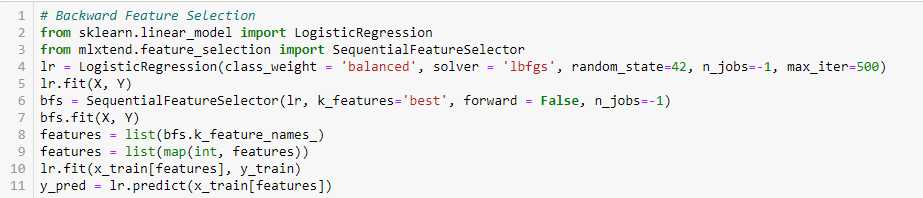
Este método, junto con el discutido anteriormente, también se conoce como el método de selección secuencial de características.
Selección exhaustiva de funciones
Este es el método de selección de características más sólido cubierto hasta ahora. Esta es una evaluación de fuerza bruta de cada subconjunto de características. Esto significa que intenta todas las combinaciones posibles de las variables y devuelve el subconjunto de mejor rendimiento.
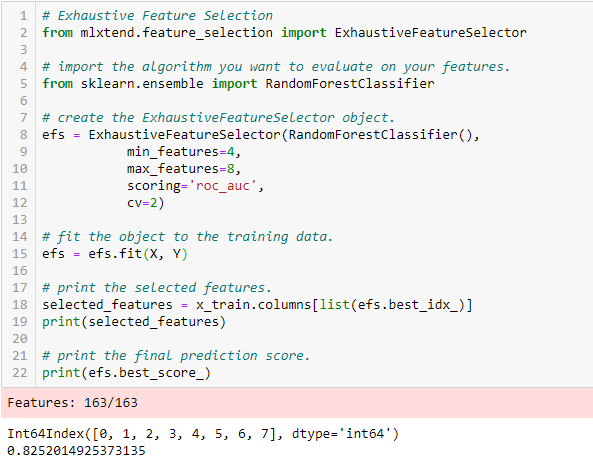
Eliminación de características recursivas
‘Dado un Estimadoro "Estimador" é uma ferramenta estatística usada para inferir características de uma população a partir de uma amostra. Ele se baseia em métodos matemáticos para fornecer estimativas precisas e confiáveis. Existem diferentes tipos de estimadores, como o imparcial e o consistente, escolhidos de acordo com o contexto e objetivo do estudo. Seu uso correto é essencial na pesquisa científica, levantamentos e análise de dados.... externo que asigna pesos a las características (por exemplo, los coeficientes de un modelo lineal), el objetivo de la eliminación de características recursivas (RFE) es seleccionar características considerando recursivamente conjuntos de características cada vez más pequeños. Primeiro, el estimador se entrena en el conjunto inicial de características y la importancia de cada característica se obtiene mediante un atributo coef_ o mediante un atributo feature_importances_.
Mais tarde, las características menos importantes se eliminan del conjunto actual de características. Ese procedimiento se repite de forma recursiva en el conjunto podado hasta que finalmente se alcanza el número deseado de características para seleccionar. ‘[2]
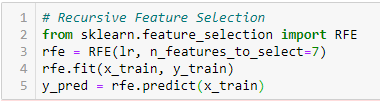
C. Métodos integrados:
Estos métodos abarcan los beneficios de los métodos de envoltura y de filtro, al incluir interacciones de características pero también mantener un costo computacional razonable. Los métodos integrados son iterativos en el sentido de que se encargan de cada iteración del proceso de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... del modelo y extraen cuidadosamente las características que más contribuyen al entrenamiento para una iteración en particular.
Analicemos algunas de estas técnicas, Clique aqui:
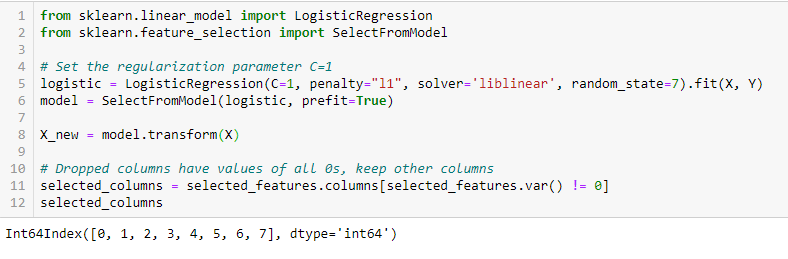
RegularizaçãoA regularização é um processo administrativo que busca formalizar a situação de pessoas ou entidades que atuam fora do marco legal. Esse procedimento é essencial para garantir direitos e deveres, bem como promover a inclusão social e econômica. Em muitos países, A regularização é aplicada em contextos migratórios, Trabalhista e Tributário, permitindo que aqueles que estão em situação irregular tenham acesso a benefícios e se protejam de possíveis sanções.... LASSO (L1)
La regularización consiste en agregar una penalización a los diferentes parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... del modelo de aprendizaje automático para reducir la libertad del modelo, quer dizer, para evitar un ajuste excesivo. En la regularización de modelos lineales, la penalización se aplica sobre los coeficientes que multiplican cada uno de los predictores. De los diferentes tipos de regularización, Lasso o L1 tiene la propiedad de reducir algunos de los coeficientes a cero. Portanto, esa característica se puede eliminar del modelo.
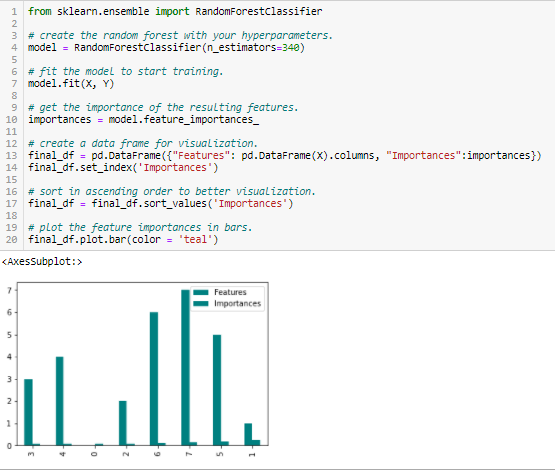
Importancia del bosque aleatorio
Random Forests es una especie de algoritmo de ensacado que agrega un número específico de árboles de decisión. Las estrategias basadas en árboles utilizadas por los bosques aleatorios se clasifican naturalmente según lo bien que mejoran la pureza del nóO Nodo é uma plataforma digital que facilita a conexão entre profissionais e empresas em busca de talentos. Através de um sistema intuitivo, permite que os usuários criem perfis, Compartilhar experiências e acessar oportunidades de trabalho. Seu foco em colaboração e networking torna o Nodo uma ferramenta valiosa para quem deseja expandir sua rede profissional e encontrar projetos que se alinhem com suas habilidades e objetivos...., ou em outras palavras, una disminución en la impureza (Impureza de gini) sobre todos los árboles. Los nodos con la mayor disminución de impurezas ocurren al comienzo de los árboles, mientras que las notas con la menor disminución de impurezas ocurren al final de los árboles. Portanto, al podar árboles debajo de un nodo en particular, podemos crear un subconjunto de las características más importantes.
conclusão
Hemos discutido algunas técnicas para la selección de funciones. Hemos dejado a propósito las técnicas de extracción de características como Análisis de Componentes Principales, Descomposición de Valor Singular, Análisis Discriminante Lineal, etc. Estos métodos ayudan a reducir la dimensionalidad de los datos o reducir el número de variables preservando la varianza de los datos.
Aparte de los métodos discutidos anteriormente, existen muchos otros métodos de selección de características. También existen métodos híbridos que utilizan técnicas de filtrado y envoltura. Si desea explorar más sobre las técnicas de selección de características, na minha opinião, un excelente material de lectura completo sería ‘Selección de funciones para el reconocimiento de patrones y datos«por Urszula Stańczyk y Lakhmi C. Jain.
Referências
Documento denominado ‘Filtros de selección de características eficientes para datos de alta dimensión’ por Artur J. Ferreira, Mário AT Figueiredo [1]
https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.RFE.html%20%5b2%5d [2]





