A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do autor.
Introdução
Basicamente formamos máquinas para que elas incluam algum tipo de automação nelas. No aprendizado de máquina, usamos vários tipos de algoritmos para permitir que as máquinas aprendam os relacionamentos dentro dos dados fornecidos e façam previsões com eles. Então, o tipo de previsão do modelo em que precisamos da saída prevista é um valor numérico contínuo, é chamado de problema de regressão.
A análise de regressão gira em torno de algoritmos simples, que são frequentemente usados em finanças, investimentos e outros, e estabelece a relação entre uma única variável dependente que depende de vários. Por exemplo, prever o preço da casa ou o salário de um empregado, etc., são os problemas de regressão mais comuns.
Discutiremos primeiro os tipos de algoritmos de regressão em breve e, em seguida, passaremos para um exemplo. Esses algoritmos podem ser lineares e não lineares..
Algoritmos de ML lineares

Regressão linear
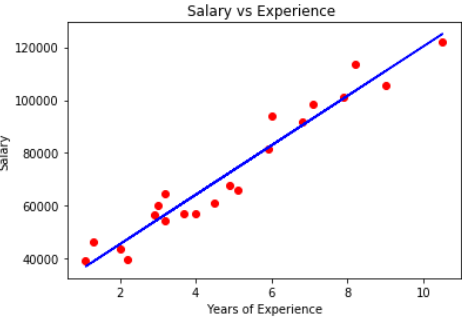
É um algoritmo comumente usado e pode ser importado da classe Linear Regression. Se utiliza una única variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... de entrada (o significativo) para prever uma ou mais variáveis de saída, assumindo que a variável de entrada não está correlacionada uma com a outra. É representado como:
y = b * x + c
onde variável dependente de y, independente de x, inclinação b da linha de melhor ajuste que poderia obter uma saída precisa e c – sua interseção. A menos que haja uma linha exata que relacione as variáveis dependentes e independentes, pode haver uma perda na produção que normalmente é tomada como o quadrado da diferença entre a produção esperada e a real, quer dizer, a Função de perdaA função de perda é uma ferramenta fundamental no aprendizado de máquina que quantifica a discrepância entre as previsões do modelo e os valores reais. Seu objetivo é orientar o processo de treinamento, minimizando essa diferença, permitindo assim que o modelo aprenda de forma mais eficaz. Existem diferentes tipos de funções de perda, como erro quadrático médio e entropia cruzada, cada um adequado para diferentes tarefas e....
Quando você usa mais de uma variável independente para obter resultados, se denomina Regressão linear múltipla. Este tipo de modelo assume que existe uma relação linear entre a característica dada e a saída., qual é seu limitación.
Regressão de cume: la normal L2
Este é um tipo de algoritmo que é uma extensão de uma regressão linear que tenta minimizar a perda, também usa dados de regressão múltipla. Seus coeficientes não são estimados por mínimos quadrados ordinários (MCO), sino por un Estimadoro "Estimador" é uma ferramenta estatística usada para inferir características de uma população a partir de uma amostra. Ele se baseia em métodos matemáticos para fornecer estimativas precisas e confiáveis. Existem diferentes tipos de estimadores, como o imparcial e o consistente, escolhidos de acordo com o contexto e objetivo do estudo. Seu uso correto é essencial na pesquisa científica, levantamentos e análise de dados.... llamado cresta, que é tendencioso e tem uma variância menor do que o estimador OLS, então obtemos uma contração nos coeficientes. Com este tipo de modelo, também podemos reduzir a complexidade do modelo.
Embora a contração do coeficiente ocorra aqui, não completamente reduzido a zero. Portanto, seu modelo final ainda incluirá tudo.
Regressão de loop: a norma L1
É o operador mínimo absoluto de seleção e contração. Isso penaliza a soma dos valores absolutos dos coeficientes para minimizar o erro de previsão. Faz com que os coeficientes de regressão para algumas das variáveis sejam reduzidos a zero. Pode ser construído usando a classe LASSO. Uma das vantagens do loop é a seleção simultânea de funções. Isso ajuda a minimizar a perda de previsão. Por outro lado, devemos levar em conta que o laço não pode fazer uma seleção de grupo, também selecione recursos antes de saturar.
Tanto el lazo como la cresta son métodos de regularizaçãoA regularização é um processo administrativo que busca formalizar a situação de pessoas ou entidades que atuam fora do marco legal. Esse procedimento é essencial para garantir direitos e deveres, bem como promover a inclusão social e econômica. Em muitos países, A regularização é aplicada em contextos migratórios, Trabalhista e Tributário, permitindo que aqueles que estão em situação irregular tenham acesso a benefícios e se protejam de possíveis sanções.....

fonte: Unsplash
Vamos rever alguns exemplos:
Suponha um dado com anos de experiência e salário de diferentes funcionários. Nosso objetivo é criar um modelo que prever o salário do funcionário com base no ano de experiência. Uma vez que contém uma variável independente e uma dependente, podemos usar regressão linear simples para este problema.
Algoritmos AA não lineares
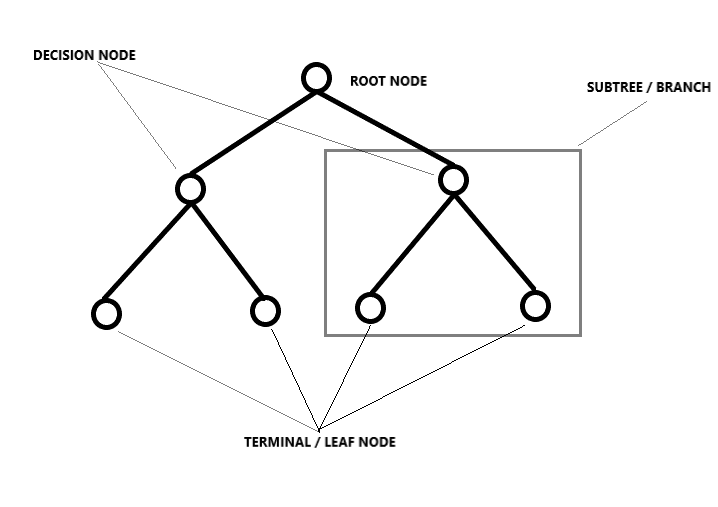
Regressão da árvore de decisão
Quebra um conjunto de dados em subconjuntos cada vez menores, dividindo-o, que resulta em uma árvore com nós de decisão e nós folha. Aqui a ideia é traçar um valor para qualquer novo ponto de dados que conecte o problema. El tipo de forma en que se lleva a cabo la división está determinada por los parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... y el algoritmo, e a divisão para quando atinge o número mínimo de informações a serem adicionadas. Árvores de decisão geralmente dão bons resultados, mas mesmo que haja uma pequena alteração nos dados, toda a estrutura muda, o que significa que os modelos se tornam instáveis.
fonte: abrir
Tome um caso de previsão de preços de casas, dado um conjunto de 13 características e ao redor 500 filas, aqui você precisa prever o preço da casa. Como você tem um número considerável de amostras aqui, deve optar por árvores ou outros métodos para prever valores.
Floresta aleatória
A ideia por trás da regressão aleatória da floresta é que, para encontrar o resultado, usa várias árvores de decisão. As etapas envolvidas são:
– Escolha K pontos de dados aleatórios do conjunto de treinamento.
– Construir uma árvore de decisão associada a esses pontos de dados
– Escolha o número de árvores que precisamos construir e repita os passos acima (fornecido como argumento)
– Para um novo ponto de dados, faça com que cada uma das árvores preveja valores da variável dependente para a entrada dada.
– Mapeie o valor médio dos valores previstos para a saída final real.
Isso é semelhante a adivinhar o número de bolas em uma caixa. Suponha que anotamos aleatoriamente os valores de previsão dados por muitas pessoas e, em seguida, calculemos a média para tomar uma decisão sobre o número de bolas na caixa.. A floresta aleatória é um modelo que usa várias árvores de decisão., que nós sabemos, mas como tem muitas árvores, também requer muito tempo para treinar e poder computacional, o que ainda é uma desvantagem.
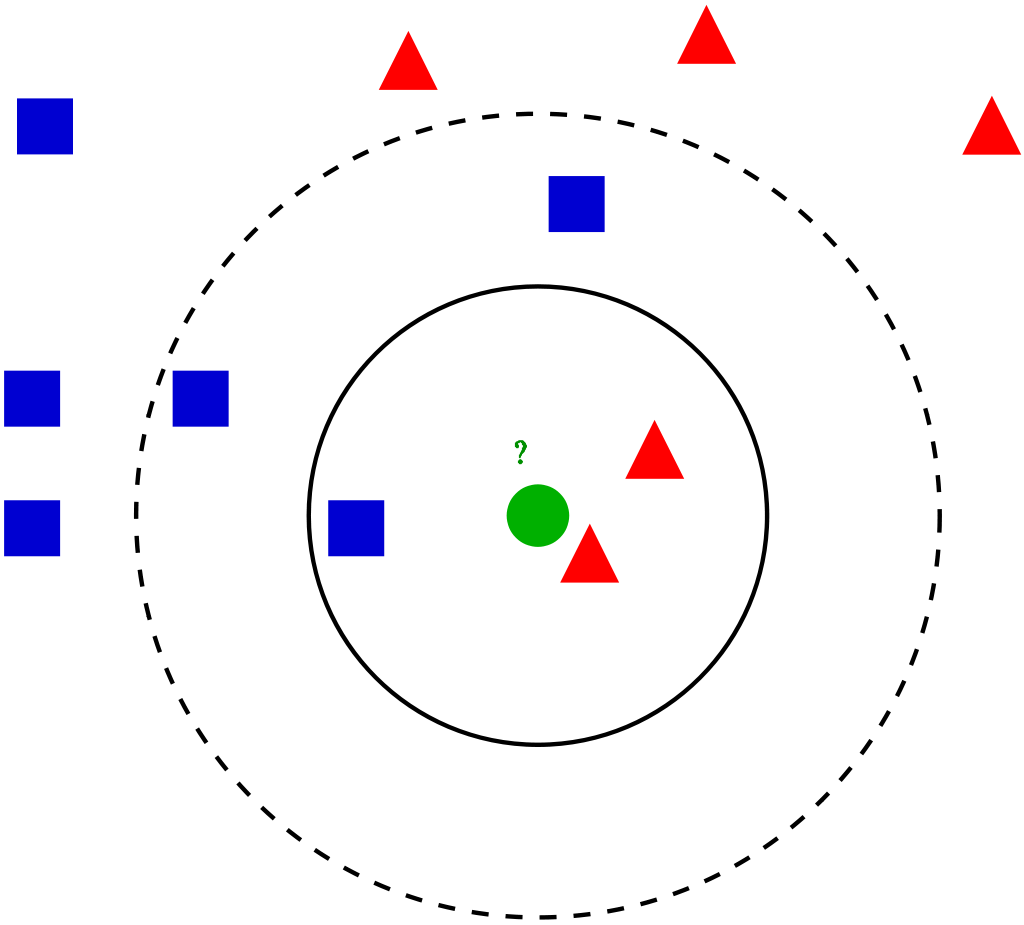
K Vizinhos mais próximos (Modelo KNN)
Pode ser usado a partir da classe KNearestNeighbors. São simples e fáceis de implementar. Para uma entrada inserida no conjunto de dados, los K vecinos más cercanos ayudan a encontrar las k instancias más similares en el conjunto de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina..... Cualquiera de los valores promedio de la medianaA mediana é uma medida estatística que representa o valor central de um conjunto de dados ordenados. Para calculá-lo, Os dados são organizados do menor para o maior e o número no meio é identificado. Se houver um número par de observações, Os dois valores principais são calculados em média. Este indicador é especialmente útil em distribuições assimétricas, uma vez que não é afetado por valores extremos.... de los vecinos se toma como valor para esa entrada.
fonte: abrir
O método para encontrar o valor pode ser dado como um argumento, cujo valor padrão é “Minkowski”, uma combinação de distâncias “Euclidiana” e “Manhattan”.
As previsões podem ser lentas quando os dados são grandes e de baixa qualidade. Como a previsão deve levar em consideração todos os pontos de dados, o modelo ocupará mais espaço durante o treinamento.
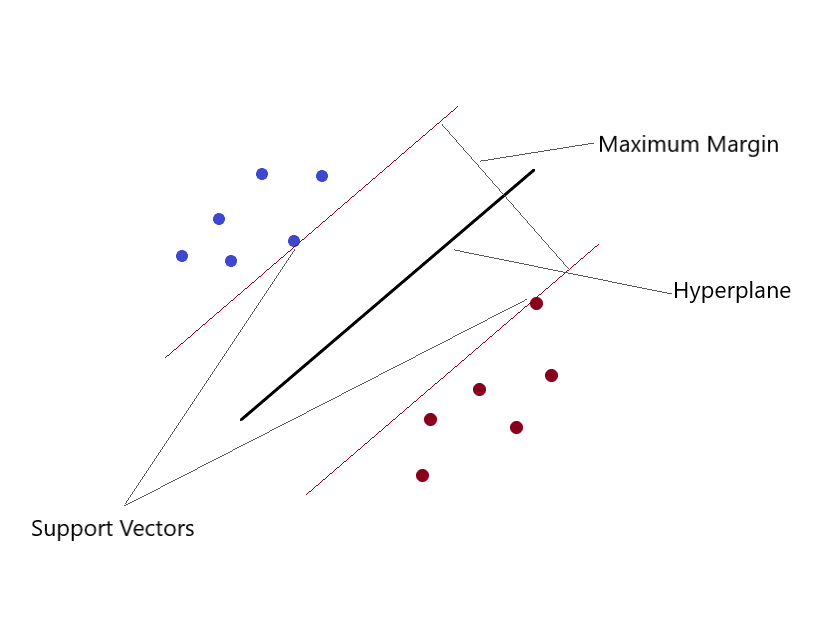
Máquinas de vetor de suporte (SVM)
Pode resolver problemas de regressão linear e não linear. Criamos um modelo SVM usando a classe SVR. em um espaço multidimensional, quando temos mais de uma variável para determinar a saída, então cada um dos pontos não é mais um ponto como em 2D, mas são vetores. O tipo mais extremo de atribuição de valor pode ser feito usando este método. Você separa as classes e dá a elas valores. A separação é pelo conceito de Max-Margin (um hiperplano). O que você precisa estar ciente é que os SVMs não são adequados para prever valores para grandes conjuntos de treinamento. SVM fracasso quando os dados são mais ruidosos.
fonte: abrir
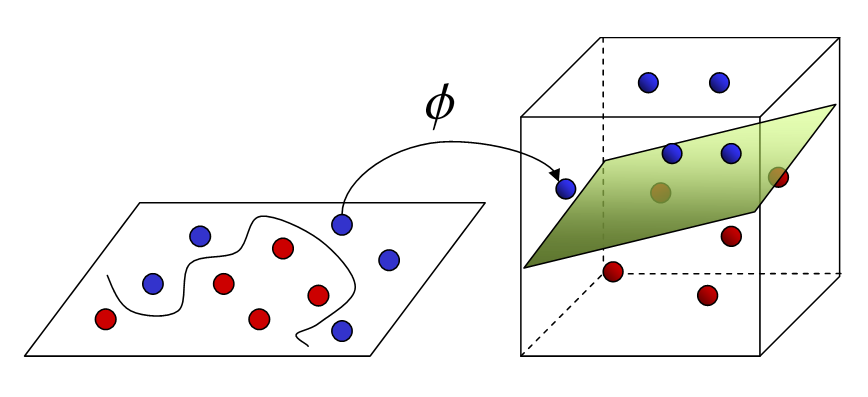
fonte: abrir
Se os dados de treinamento forem muito maiores que o número de recursos, KNN é melhor que SVM. O SVM supera o KNN quando há funções maiores e menos dados de treinamento.
Nós vamos, chegamos ao final deste artigo, discutimos brevemente os tipos de algoritmos de regressão (teoria). Este é Surabi, tenho licenciatura em tecnologia. dê uma olhada em mim Perfil do linkedIn e conectar. Espero que tenha gostado de ler isso. Obrigado.
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do autor.





