¿Cuántos algoritmos de impulso conoces?
¿Puede nombrar al menos dos algoritmos de impulso en el aprendizaje automático?
Los algoritmos de impulso han existido durante años y, sin embargo, solo recientemente se han convertido en la corriente principal de la comunidad de aprendizaje automático. Pero, ¿por qué estos algoritmos de impulso se han vuelto tan populares?
Una de las principales razones del aumento en la adopción de algoritmos de impulso son las competencias de aprendizaje automático. Los algoritmos de impulso otorgan superpoderes a los modelos de aprendizaje automático para mejorar su precisión de predicción. Un vistazo rápido a las competiciones de Kaggle y Hackatones de DataHack es suficiente evidencia – ¡los algoritmos de impulso son tremendamente populares!
En pocas palabras, los algoritmos de impulso a menudo superan a los modelos más simples como la regresión logística y árboles de decisión. De hecho, la mayoría de los finalistas de nuestra plataforma DataHack utilizan un algoritmo de impulso o una combinación de varios algoritmos de impulso.

En este artículo, le presentaré cuatro algoritmos de impulso populares que puede usar en su próximo aprendizaje automático hackathon o proyecto.
4 Impulsar los algoritmos en el aprendizaje automático
- Máquina de aumento de gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en... (GBM)
- Máquina de aumento de gradiente extremo (XGBM)
- LightGBM
- CatBoost
Introducción rápida a Boosting (¿Qué es Boosting?)
Imagínese este escenario:
Ha creado un modelo de regresión lineal que le brinda una precisión decente del 77% en el conjunto de datos de validación. A continuación, decide ampliar su cartera mediante la creación de un modelo de k-vecino más cercano (KNN) y un árbol de decisión modelo en el mismo conjunto de datos. Estos modelos le dieron una precisión del 62% y el 89% en el conjunto de validación, respectivamente.
Es obvio que los tres modelos funcionan de formas completamente diferentes. Por ejemplo, el modelo de regresión lineal intenta capturar relaciones lineales en los datos, mientras que el modelo de árbol de decisión intenta capturar la no linealidad en los datos.
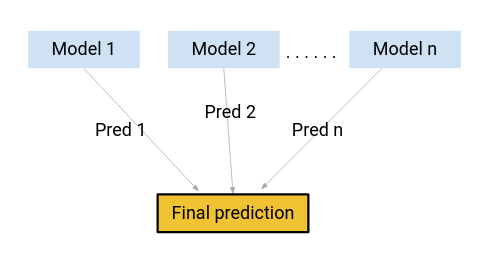
¿Qué tal si, en lugar de usar cualquiera de estos modelos para hacer las predicciones finales, usamos una combinación de todos estos modelos?
Estoy pensando en un promedio de las predicciones de estos modelos. Al hacer esto, podríamos capturar más información de los datos, ¿verdad?
Esa es principalmente la idea detrás del aprendizaje en conjunto. ¿Y dónde entra el impulso?
El impulso es una de las técnicas que utiliza el concepto de aprendizaje conjunto. Un algoritmo de impulso combina varios modelos simples (también conocidos como aprendices débiles o estimadores de base) para generar el resultado final.
Veremos algunos de los algoritmos de impulso importantes en este artículo.
1. Máquina de aumento de gradiente (GBM)
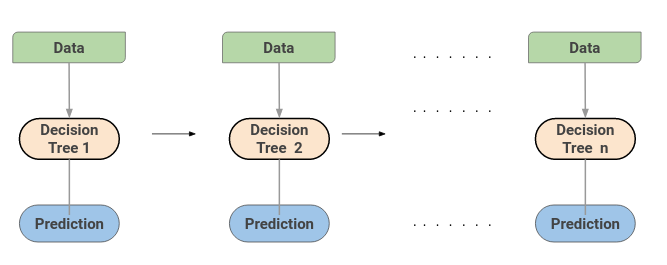
Una máquina de aumento de gradiente o GBM combina las predicciones de varios árboles de decisión para generar las predicciones finales. Tenga en cuenta que todos los estudiantes débiles en una máquina de aumento de gradiente son árboles de decisión.
Pero si usamos el mismo algoritmo, ¿cómo es mejor usar cien árboles de decisión que usar un solo árbol de decisión? ¿Cómo los diferentes árboles de decisión capturan diferentes señales / información de los datos?
Aquí está el truco: los nodos en cada árbol de decisión toman un subconjunto diferente de características para seleccionar la mejor división. Esto significa que los árboles individuales no son todos iguales y, por lo tanto, pueden capturar diferentes señales de los datos.
Además, cada árbol nuevo tiene en cuenta los errores o errores cometidos por los árboles anteriores. Por lo tanto, cada árbol de decisiones sucesivo se basa en los errores de los árboles anteriores. Así es como los árboles en un algoritmo de máquina de aumento de gradiente se construyen secuencialmente.
Aquí hay un artículo que explica el proceso de ajuste de hiperparámetros para el algoritmo GBM:
2. Máquina de aumento de gradiente extremo (XGBM)
Extreme Gradient Boosting o XGBoost es otro algoritmo de impulso popular. De hecho, ¡XGBoost es simplemente una versión improvisada del algoritmo GBM! El procedimiento de trabajo de XGBoost es el mismo que el de GBM. Los árboles en XGBoost se construyen secuencialmente, tratando de corregir los errores de los árboles anteriores.
Aquí hay un artículo que explica intuitivamente las matemáticas detrás de XGBoost y también implementa XGBoost en Python:

Pero hay ciertas características que hacen que XGBoost sea un poco mejor que GBM:
- Uno de los puntos más importantes es que XGBM implementa un preprocesamiento paralelo (a nivel de nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos....) que lo hace más rápido que GBM.
- XGBoost también incluye una variedad de técnicas de regularizaciónLa regularización es un proceso administrativo que busca formalizar la situación de personas o entidades que operan fuera del marco legal. Este procedimiento es fundamental para garantizar derechos y deberes, así como para fomentar la inclusión social y económica. En muchos países, la regularización se aplica en contextos migratorios, laborales y fiscales, permitiendo a quienes se encuentran en situaciones irregulares acceder a beneficios y protegerse de posibles sanciones.... que reducen el sobreajuste y mejoran el rendimiento general. Puede seleccionar la técnica de regularización configurando los hiperparámetros del algoritmo XGBoost
Obtenga información sobre los diferentes hiperparámetros de XGBoost y cómo juegan un papel en el proceso de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... del modelo aquí:
Además, si está utilizando el algoritmo XGBM, no tiene que preocuparse por imputar valores faltantes en su conjunto de datos. El modelo XGBM puede manejar los valores faltantes por sí solo. Durante el proceso de entrenamiento, el modelo aprende si los valores faltantes deben estar en el nodo derecho o izquierdo.
3. LightGBM
El algoritmo de impulso LightGBM se está volviendo más popular día a día debido a su velocidad y eficiencia. LightGBM puede manejar grandes cantidades de datos con facilidad. Pero tenga en cuenta que este algoritmo no funciona bien con una pequeña cantidad de puntos de datos.
Tomemos un momento para entender por qué ese es el caso.
Los árboles en LightGBM tienen un crecimiento de hojas, en lugar de un crecimiento de niveles. Después de la primera división, la siguiente división se realiza solo en el nodo hoja que tiene una mayor pérdida delta.
Considere el ejemplo que he ilustrado en la siguiente imagen:
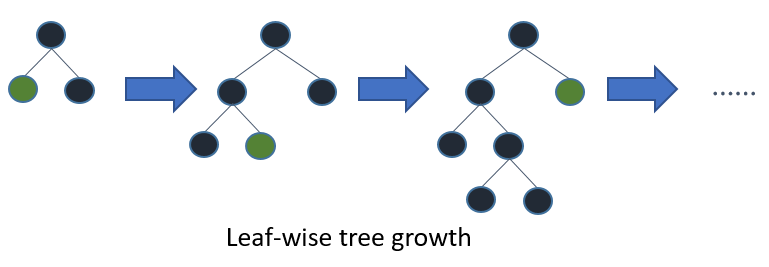
Después de la primera división, el nodo izquierdo tuvo una pérdida mayor y se selecciona para la siguiente división. Ahora, tenemos tres nodos de hoja y el nodo de hoja del medio tuvo la mayor pérdida. La división por hojas del algoritmo LightGBM le permite trabajar con grandes conjuntos de datos.
Para acelerar el proceso de formación, LightGBM utiliza un método basado en histogramasLos histogramas son representaciones gráficas que muestran la distribución de un conjunto de datos. Se construyen dividiendo el rango de valores en intervalos, o "bins", y contando cuántos datos caen en cada intervalo. Esta visualización permite identificar patrones, tendencias y la variabilidad de los datos de manera efectiva, facilitando el análisis estadístico y la toma de decisiones informadas en diversas disciplinas.... para seleccionar la mejor división. Para cualquier variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... continua, en lugar de utilizar los valores individuales, estos se dividen en contenedores o cubos. Esto acelera el proceso de entrenamiento y reduce el uso de memoria.
Aquí hay un excelente artículo que compara los algoritmos LightGBM y XGBoost:
4. CatBoost
Como sugiere el nombre, CatBoost es un algoritmo de impulso que puede manejar variables categóricas en los datos. La mayoría de los algoritmos de aprendizaje automático no pueden funcionar con cadenas o categorías en los datos. Por lo tanto, convertir variables categóricas en valores numéricos es un paso previo al procesamiento esencial.
CatBoost puede manejar internamente variables categóricas en los datos. Estas variables se transforman en numéricas utilizando varias estadísticas sobre combinaciones de características.
Si desea comprender las matemáticas detrás de cómo estas categorías se convierten en números, puede leer este artículo:

Otra razón por la que CatBoost se usa ampliamente es que funciona bien con el conjunto predeterminado de hiperparámetros. Por lo tanto, como usuario, no tenemos que dedicar mucho tiempo a ajustar los hiperparámetros.
Aquí hay un artículo que implementa CatBoost en un desafío de aprendizaje automático:
Notas finales
En este artículo, cubrimos los conceptos básicos del aprendizaje por conjuntos y analizamos los 4 tipos de algoritmos de refuerzo. ¿Está interesado en aprender sobre otros métodos de aprendizaje en conjunto? Debería consultar el siguiente artículo:
¿Con qué otros algoritmos de impulso has trabajado? ¿Ha tenido éxito con estos algoritmos de impulso? Comparta sus pensamientos y experiencia conmigo en la sección de comentarios a continuación.





