Tipos de aprendizaje automático

1. Aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en...: En un modelo de aprendizaje supervisado, el algoritmo aprende en un conjunto de datos etiquetado para generar predicciones esperadas para la solución a nuevos datos.
P.ej; Para el pronóstico del precio de la vivienda, primero necesitamos datos sobre viviendas como; pie cuadrado, no. de habitaciones, la casa tiene jardín o no, y así sucesivamente. Entonces necesitamos saber los precios de estas casas, dicho de otra forma; etiquetas de clase. Ahora que los datos provienen de cientos de casas, sus características y precios, ahora podemos entrenar un modelo de aprendizaje automático supervisado para predecir el precio de una nueva casa en función de experiencias pasadas del modelo.
El aprendizaje supervisado es de dos tipos:
a) Clasificación: En Clasificación, un programa de computadora se entrena en un conjunto de datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y, según el entrenamiento, categoriza los datos en diferentes etiquetas de clase. Este algoritmo se utiliza para predecir los valores discretos como hombre | mujer, verdadero | falso, spam | no spam, etc.
P.ej; Detección de correo no deseado, acreditación de voz, identificación de células cancerosas, etc.
Tipos de algoritmos de clasificación:
- Clasificador ingenuo de Bayes
- Árboles de decisión
- Regresión logística
- K-Vecinos más cercanos
- Máquinas de vectores soporte
- Clasificación de bosque aleatoria
b) Regresión: La tarea del algoritmo de regresión es hallar la función de mapeo para mapear las variables de entrada (x) a la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de salida continua (y). Los algoritmos de regresión se usan para predecir valores continuos como precio, salario, edad, notas, etc.
P.ej; Predicción del tiempo, predicción del precio de la vivienda, detección de noticias falsas, etc.
Tipos de algoritmos de regresión:
- Regresión lineal simple
- Regresión lineal múltiple
- regresión polinomial
- Regresión del árbol de decisión
- Regresión de bosque aleatorio
- Método de conjunto
2. Aprendizaje no supervisadoEl aprendizaje no supervisado es una técnica de machine learning que permite a los modelos identificar patrones y estructuras en datos sin etiquetas predefinidas. A través de algoritmos como k-means y análisis de componentes principales, este enfoque se utiliza en diversas aplicaciones, como la segmentación de clientes, la detección de anomalías y la compresión de datos. Su capacidad para revelar información oculta lo convierte en una herramienta valiosa en la...: En un modelo de aprendizaje no supervisado, el algoritmo aprende en un conjunto de datos sin etiquetar e intenta tener sentido extrayendo características, co-ocurrencia y patrones subyacentes por sí solo.
P.ej; Detección de anomalías, incluida la detección de fraudes. Otro ejemplo es la apertura de hospitales de urgencias a las zonas de máxima propensión a accidentes. El agrupamientoEl "agrupamiento" es un concepto que se refiere a la organización de elementos o individuos en grupos con características o objetivos comunes. Este proceso se utiliza en diversas disciplinas, incluyendo la psicología, la educación y la biología, para facilitar el análisis y la comprensión de comportamientos o fenómenos. En el ámbito educativo, por ejemplo, el agrupamiento puede mejorar la interacción y el aprendizaje entre los estudiantes al fomentar el trabajo... de K-medias agrupará estas ubicaciones de áreas propensas máximas en grupos y definirá un centro de grupo (dicho de otra forma, hospital) para cada grupo (dicho de otra forma, áreas propensas a accidentes).
Tipos de aprendizaje no supervisado:
- Agrupación
- Detección de anomalías
- Asociación
- Autoencoders
- Modelos de variables latentes
- Redes neuronales
3. Aprendizaje por refuerzoEl aprendizaje por refuerzo es una técnica de inteligencia artificial que permite a un agente aprender a tomar decisiones mediante la interacción con un entorno. A través de la retroalimentación en forma de recompensas o castigos, el agente optimiza su comportamiento para maximizar las recompensas acumuladas. Este enfoque se utiliza en diversas aplicaciones, desde videojuegos hasta robótica y sistemas de recomendación, destacándose por su capacidad de aprender estrategias complejas....: El aprendizaje por refuerzo es un tipo de aprendizaje automático en el que el modelo aprende a comportarse en un entorno realizando algunas acciones y analizando las reacciones. RL toma las medidas adecuadas para maximizar la solución positiva en la situación particular. El modelo de refuerzo decide qué acciones tomar para realizar una tarea determinada, es por ello que está obligado a aprender de la experiencia misma.
P.ej; Tomemos un ejemplo de un bebé cuando está aprendiendo a caminar. En el primer caso, cuando el bebé comienza a caminar y llega al chocolate dado que el chocolate es el objetivo final del bebé y la solución de un bebé es positiva dado que está feliz. En el segundo caso, cuando el bebé comienza a caminar y mientras camina es golpeado por la silla y no puede lograr el chocolate, comienza a llorar, lo cual es una respuesta negativa. Dicho de otra forma que cómo los humanos aprendemos del rastro y el error. Aquí, el bebé es el «agente», el chocolate es la «recompensa» y muchos estorbos en el medio. Ahora el agente intenta de varias formas y descubre el mejor camino factible para lograr la recompensa.
Ciclo de vida del aprendizaje automático
El aprendizaje automático ayuda a incrementar el rendimiento y la productividad de la tarea. Incluye aprendizaje y autocorrección cuando se presenta con nuevos datos.
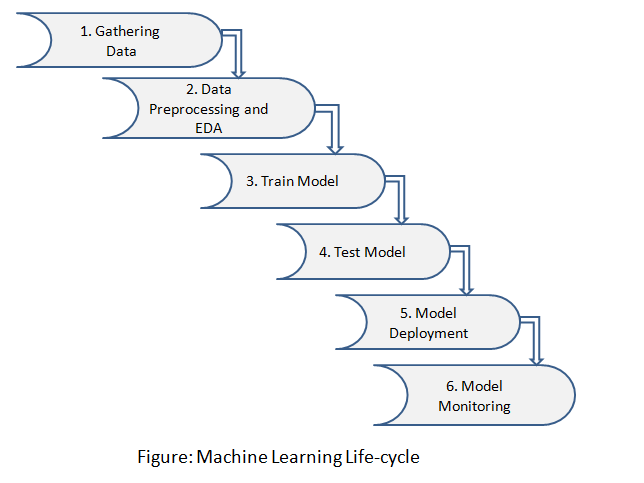
El ciclo de vida del aprendizaje automático implica seis pasos principales:
Paso 1: recopilación de datos
Identifique varias fuentes de datos como Kaggle y recopile el conjunto de datos requerido
Paso 2: procesamiento previo de datos y EDA
En este paso, hacemos un análisis de los datos en busca de valores perdidos, datos duplicados, datos inválidos usando diferentes técnicas analíticas. Y además preprocesar los datos para extracciones de características, análisis de características y visualización de datos.
Paso 3: modelo de tren
Usamos un conjunto de datos para entrenar el modelo usando varios algoritmos de aprendizaje automático. Entrenar un modelo es esencial para que pueda comprender los distintos patrones, reglas y características.
Paso 4: modelo de prueba
En este paso, verificamos la precisión de nuestro modelo proporcionando un conjunto de datos de prueba al modelo entrenado.
Paso 5: Implementación del modelo
La implementación del modelo significa integrar un modelo de aprendizaje automático en un entorno de producción existente que toma entradas y devuelve resultados para tomar decisiones comerciales sustentadas en datos. Se enumeran varias tecnologías que puede usar para poner en práctica sus modelos de aprendizaje automático:
- Estibador
- Kubernetes
- AWS SageMaker
- MLFlow
- Servicio de aprendizaje automático de Azure
Paso 6: Monitoreo del modelo
Después de la implementación del modelo, aquí viene el monitoreo del modelo que monitorea sus modelos de aprendizaje automático en busca de factores como errores, fallas y latencia y, lo más importante, para garantizar que su modelo mantenga el rendimiento deseado. El monitoreo de modelos es muy importante debido a que sus modelos se degradarán con el tiempo debido a varios factores, como datos invisibles, cambios en el entorno y relaciones entre variables.
Algunas aplicaciones del aprendizaje automático en el mundo real
- Traducción automática de idiomas en el Traductor de Google
- Selección de ruta más rápida en el buscador de Google Map
- Coche sin conductor / autónomo
- Smartphone con acreditación facial
- Acreditación de voz
- Sistema de recomendación de anuncios
- Sistema de recomendación de Netflix
- Sugerencia de etiquetado automático de amigos en Facebook
- Negociación del mercado de valores
- Detección de fraudes
- Predicción del tiempo
- Diagnostico medico
- Chatbot
- Aprendizaje automático en agricultura
Beneficios del aprendizaje automático
- Automatización del trabajo
- Potente capacidad predictiva
- Aumento de las ventas en el mercado de comercio electrónico.
- Beneficios del AA en el dominio médico para impulsar el diagnóstico médico y el desarrollo de fármacos
- El aprendizaje automático se utiliza en cirugía médica robótica
- ML en finanzas aumenta la productividad mejora los ingresos y brinda transacciones seguras
- Modelar los datos para tomar decisiones útiles
Resumen
El aprendizaje automático se puede usar en casi todos los sectores de la vida humana para hacer nuestro trabajo eficiente, robusto, y Sin complicaciones. Como sabemos, todo tiene sus pros y sus contras, el aprendizaje automático además tiene sus desventajas, como a modo de ejemplo, con el aumento del aprendizaje automático, muchas personas pueden perder su trabajo de escenario actual. Pero más en tono rimbombante está beneficioso a la larga para humanidad.
Los medios que se muestran en este post no son propiedad de DataPeaker y se usan a discreción del autor.





